- Преподавателю
- Математика
- Розробка алгоритму ефективної побудови контрольних тестів булевих функцій
Розробка алгоритму ефективної побудови контрольних тестів булевих функцій
| Раздел | Математика |
| Класс | - |
| Тип | Другие методич. материалы |
| Автор | Юрченко Е.В. |
| Дата | 28.09.2012 |
| Формат | doc |
| Изображения | Есть |

ЗМІСТ:
Вступ
Розділ 1. Необхідні теоритичні відомості.
1.1. Еволюційні алгоритми.
1.2. Оптимізаційні задачі.
Розділ 2. Побудова контрольних тестів булевих функцій.
2.1. Реалізація булевих функцій.
2.2. Проблематика діагностики булевих функцій та систем.
Розділ 3. Розробка алгоритму ефективної побудови контрольних тестів булевих функцій.
3.1. Постановка задачі та основна ідея підходу.
3.2. Реалізація.
3.3. Тестовий проклад.
Висновки
Список використаних джерел
Вступ.
Прогрес людського суспільства пов'язаний з розв'язком великої кількості задач з постійним зростанням їх складності. Серед усіх задач виділяють великий клас так званих оптимізаційних задач. Ці задачі знаходять оптимальну стратегію дій серед досить великої кількості варіантів, та мають своє практичне застосування у господарській діяльності (складання оптимальних маршрутів, складання планів та контроль над їх виконанням, мінімізація різних об'єктів тощо). Для переважної більшості задач існують алгоритми їх розв'язання, наявність яких набагато спрощує сам процес розв'язання, вимоги до особи, що розв'язує (якщо це людина), та уможливлює одержання результату за допомогою обчислювальної техніки. Алгоритми класифікуються за складністю: існують прості алгоритми, що дозволяють швидко знайти результат, також існують складні за виконанням алгоритми, які потребують багато часу та потужних обчислювальних ресурсів, що значно ускладнює, а іноді і унеможливлює їх використання.
Нажаль для багатьох так званих складних оптимізаційних задач не існує (або наразі не знайдено) простого алгоритму їх розв'язання. Тому наразі є дуже актуальною задачею знаходження нових підходів до розв'язання складних задач. Одним з таких підходів є використання еволюційних алгоритмів (генетичні алгоритми, нейронні сітки тощо). Еволюційні алгоритми показали свою ефективність при розв'язанні багатьох складних задач: вони швидкі за виконанням, гнучкі до модифікації та дають не поганий (але не завжди найкращий) результат.
З усіх складних оптимізаційних задач ми обрали дуже цікаву, актуальну та важливу задачу ефективної побудови контрольних тестів булевих функцій. Ця задача має не лише теоритичний інтерес, але і практичну цінність у диагностиці технічної апаратури. За розв'язання цієї задачі ми вирішили використати еволюційний (конкретно, генетичний) алгоритм. Таким чином, головна мета нашої роботи - дослідити можливість використання генетичного алгоритму до розв'язку задачі побудови контрольних тестів булевих функцій та розробити і програмно реалізувати цей алгоритм. Відповідно до мети в роботі розглядаються такі задачі :
-
Розглянути історію виникнення та основну структуру еволюційних алгоритмів.
-
Розглянути основні види оптимізаційних задач та алгоритми їх розв'язання.
-
Розглянути основні підходи до тестування булеіих функцій.
-
Скласти та програмно реалізувати генетичний алгоритм ефективної побудови контрольних тестів булевих функцій.
Об'єктом нашого дослідження є еволюційні задачі, предметом -побудова за реальний час контрольних тестів булевих функцій. Під час дослідження були використані різноманітні методи дослідження: аналіз наукової літератури, моделювання та експериментування, оцінка результату.
Гіпотеза нашого дослідження полягає в тому, що за допомогою генетичних алгоритмів ми можемо ефективно розв'язати задачу побудови контрольних тестів булевих функцій.
Практичне значення роботи полягає у подальшому використанні складеної програми у електротехніці при побудові контрольних тестів булевих функцій, теорії алгоритмів, як приклад розв'язку складних задач еволюційними методами та у інформатиці, як приклад складання програм із використанням різних видів структур даних (циклів, процедур, функцій тощо).
Дипломна робота складається із вступу, трьох розділів, розбитих на підрозділи, висновків та списку використаних джерел. Загальний обсяг роботи 54 сторінки. Список використаних джерел включає 25 найменувань.
Розділ 1. Необхідні теоритичні відомості.
1.1 Еволюційні алгоритми.
Основна теза підходу, що дістав назву еволюційного моделювання [2, 8, 11, 12] є заміна процесу моделювання складного об'єкту моделюванням його еволюції. Цей процес направлений на вживання механізмів природної еволюції при синтезі складних систем обробки інформації. У своїй теорії походження видів Ч. Дарвін відкрив і обґрунтував основний закон розвитку органічного світу, охарактеризувавши його взаємодією трьох наступних чинників:
1) спадковій мінливості;
2) боротьби за існування;
3) природного відбору.
Дарвінівська теорія отримала підтвердження і розвиток в генетиці і інших науках. Одним з найбільших еволюціоністів І.І. Шмальгаузеном були висунуті наступні необхідні і достатні умови, що визначають неминучість еволюції:
1) спадкова мінливість, тобто мутації як передумова еволюції, її матеріал;
2) боротьба за існування як контролюючий і направляючий чинник;
3) природний відбір як перетворюючий чинник.
Поняття «Еволюційне моделювання» сформувалося в роботах Л. Фогеля, А. Оуені, М. Уолша. У 1966 році вийшла їх спільна книга «Штучний інтелект і еволюційне моделювання».
Термін «еволюційні обчислення» зазвичай використовують для загального опису алгоритмів пошуку, оптимізації або навчання, заснованих на формалізованих принципах природного еволюційного процесу. Еволюційні методи призначені для пошуку переважних розв'язків і засновані на статистичному підході до дослідження ситуацій і ітераційному наближенні до шуканого стану систем. На відміну від точних методів математичного програмування еволюційні методи дозволяють знаходити розв'язки, що є близькими до оптимальних, за прийнятний час, а на відміну від відомих евристичних методів оптимізації характеризуються істотно меншою залежністю від особливостей додатка (тобто більш універсальні) і у багатьох випадках забезпечують кращу міру наближення до оптимального розв'язку. Основна перевага еволюційних методів оптимізації полягає в можливості розв'язування багатомодульних (що мають декілька локальних екстремумів) задач з великою розмірністю за рахунок поєднання елементів випадковості і детермінованої точно так, як і це відбувається в природному середовищі. Детермінованість цих методів полягає в моделюванні природних процесів відбору, розмноження і спадкоємства, що відбуваються по строго певних правилах, основних з яких є закон еволюції: «виживає сильніший». Іншим важливим чинником ефективності еволюційних обчислень є моделювання процесів розмноження і спадкоємства. Існуючі варіанти розв'язків можуть за певним правилом породжувати нові розв'язки, які успадковуватимуть кращі риси своїх «предків».
Як випадковий елемент в методах еволюційних обчислень використовується моделювання процесу мутації. З її допомогою характеристики того або іншого розв'язку можуть бути випадково змінені, що приведе до нового напряму в процесі еволюції розв'язків і може прискорити процес вироблення кращого розв'язку.
Сформулюємо переваги і недоліки еволюційних обчислень. Переваги еволюційних досліджень полягають у:
-
широкій сфері застосування;
-
можливості проблемно-орієнтованого кодування розв'язків;
-
підборі початкової популяції, комбінуванні еволюційних обчислень з не еволюційними алгоритмами, продовження процесу еволюції до тих пір, поки є необхідні ресурси;
-
придатності для пошуку в складному просторі розв'язків великої розмірності;
-
відсутності обмежень цільової функції;
-
ясності схеми і базових принципів еволюційних обчислень;
-
інтегрованості еволюційних обчислень з іншими некласичними парадигмами штучного інтелекту, такими як штучні нейромережі і нечітка логіка.
Окрім переваг можливо виділити наступні недоліки еволюційних обчислень:
-
евристичний характер еволюційних обчислень не гарантує оптимальності отриманого розв'язку (правда, на практиці, найчастіше потрібно за заданий час отримати одне або декілька субоптимальних альтернативних розв'язків, тим більше що вихідні дані в завданні можуть динамічно мінятися, бути неточними або неповними);
-
відносно висока обчислювальна трудомісткість, яка проте долається за рахунок розпаралелювання на рівні організації еволюційних обчислень і на рівні їх безпосередньої реалізації в обчислювальній системі; відносно невисока ефективність на завершальних фазах моделювання еволюції (оператори пошуку в еволюційних алгоритмах не орієнтовані на швидке попадання в локальний оптимум); невирішеність питань само адаптації.
Історія еволюційних обчислень почалася з розробки ряду різних незалежних моделей еволюційного процесу. Серед цих моделей можна виділити декілька основних парадигм:
• генетичні алгоритми;
• генетичне програмування;
• еволюційні стратегії;
• еволюційне програмування.
Найважливішим частим випадком еволюційних методів є генетичні методи, засновані на пошуку кращих рішень за допомогою спадкоємства і посилення корисних властивостей множини об'єктів певного застосування в процесі імітації їх еволюції.
Генетичні алгоритми (ГА) [3, 6, 15, 19] це стохастичні, евристичні оптимізаційні методи, вперше запропоновані Холландом у 1975 році. Ідея генетичних алгоритмів запозичена в живої природи і полягає в організації еволюційного процесу, кінцевою метою якого є здобуття розв'язок в складній задачі оптимізації. Розробник генетичних алгоритмів виступає в даному випадку як "творець", який повинен правильно встановити закони еволюції, аби досягти бажаної мети щонайшвидше. Вперше ці нестандартні ідеї були застосовані до розв'язку оптимізаційних задач в середині 70-х років минулого століття. Приблизно через десять років з'явилися перші теоретичні обґрунтування цього підходу. На сьогоднішній день генетичні алгоритми довели свою конкурентоспроможність при розв'язку багатьох важких задач і особливо в практичних застосуваннях, де математичні моделі мають складну структуру і вживання стандартних методів типа гілок і меж, динамічне або лінійне програмування вкрай затруднено.
Мета в оптимізації за допомогою ГА полягає в тому, щоб знайти кращий можливий розв'язок, що відповідає деяким критеріям. Для реалізації генетичного алгоритму потрібно спочатку вибрати відповідну структуру для представлення цих розв'язків. У постановці задачі пошуку об'єкт цієї структури даних представляє собою точку в просторі пошуку всіх можливих розв'язків. Властивості об'єктів представлені значеннями параметрів, що об'єднуються в запис, який в еволюційних методах називають хромосомою. У генетичних методах оперують хромосомами, що відносяться до множини об'єктів популяції. Імітація генетичних принципів імовірнісний вибір батьків, серед членів популяції, схрещування їх хромосом, відбір нащадків для включення в нові покоління об'єктів на основі оцінки цільової функції веде до еволюційного поліпшення значень цільової функції (функції пристосованості) від покоління до покоління.
Найчастіше хромосома це бітовий рядок. Проте ГА не обмежені бінарним зображенням даних. Деякі реалізації використовують цілочисельне кодування. Незважаючи на те, що для багатьох реальних задач частіше використовують рядки змінної довжини, в даний час структури фіксованої довжини найбільш поширені і вивчені. Ми обмежимося лише структурами, які є одиночними рядками по n біт.
Кожна хромосома (рядок) є конкатенацією ряду підкомпонентів, які називаються генами. Гени розташовуються в різних позиціях або локусах хромосоми і набувають значень, які називають аллелями. У вставках з бінарними рядками ген є бітом, локусом є його позиція в рядку, а аллеллю - його значення (0 або 1). Біологічний термін "генотип" відноситься до повної генетичної моделі особини і відповідає структурі в ГА. Термін "фенотип" відноситься до зовнішніх спостережуваних ознак і відповідає вектору в просторі параметрів. Надзвичайно простим, але ілюстративним прикладом використання цих ознак є задача максимізації наступної функції два змінних:
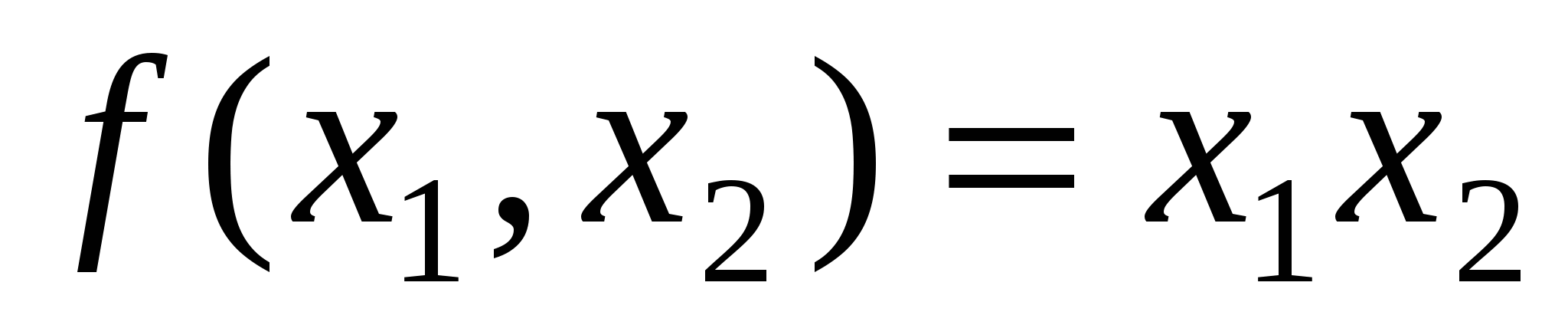 , де 0 <= x1 < =1 і 0 < = x2 <= 1.
, де 0 <= x1 < =1 і 0 < = x2 <= 1.
Зазвичай методика кодування реальних змінних 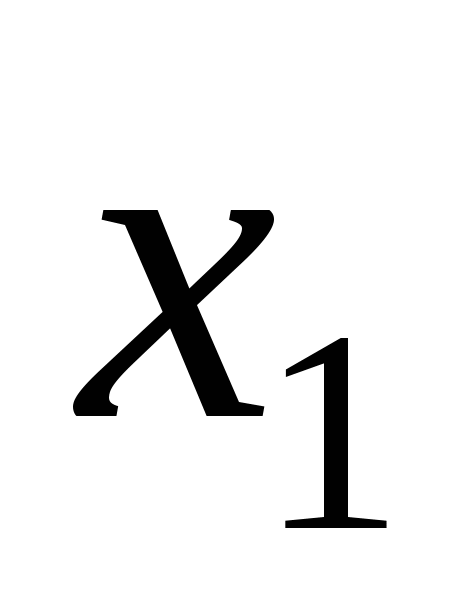 і
і 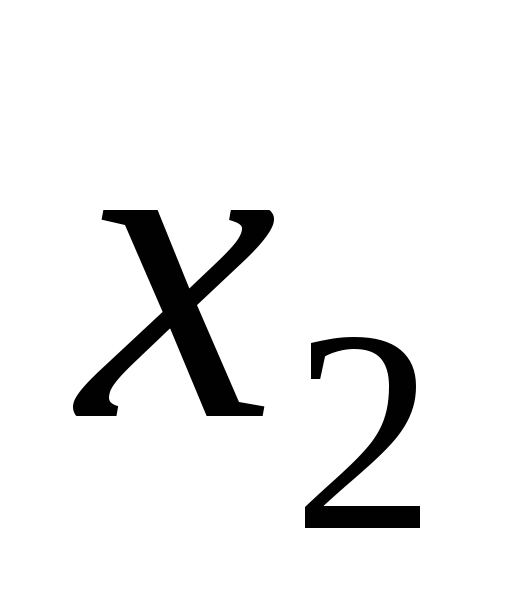 полягає в їх перетворенні в двійкові цілочисельні рядки достатньої довжини для забезпечення бажаної точності. Передбачимо, що 10-розрядне кодування достатнє і для і . Встановити відповідність між генотипом і фенотипом закодованих особин можна, розділивши відповідне двійковому зображенню ціле число на значення
полягає в їх перетворенні в двійкові цілочисельні рядки достатньої довжини для забезпечення бажаної точності. Передбачимо, що 10-розрядне кодування достатнє і для і . Встановити відповідність між генотипом і фенотипом закодованих особин можна, розділивши відповідне двійковому зображенню ціле число на значення ![]() . Наприклад, код [0000000000] відповідає значенню 0/1023 або 0, тоді як код [1111111111] відповідає 1023/1023 або 1. Структура даних, що оптимізується, є 20-бітовим рядком, що представляє конкатенацію кодувань і . Змінна розміщується в крайніх лівих 10-розрядах, а розміщується в правій частині генотипу особини. Генотип є точкою в 20-мірному бінарному просторі, досліджуваному ГА. Фенотип є точкою в двовимірному просторі параметрів.
. Наприклад, код [0000000000] відповідає значенню 0/1023 або 0, тоді як код [1111111111] відповідає 1023/1023 або 1. Структура даних, що оптимізується, є 20-бітовим рядком, що представляє конкатенацію кодувань і . Змінна розміщується в крайніх лівих 10-розрядах, а розміщується в правій частині генотипу особини. Генотип є точкою в 20-мірному бінарному просторі, досліджуваному ГА. Фенотип є точкою в двовимірному просторі параметрів.
Після того, як вибрані параметри, їх число і розрядність, необхідно вирішити, як безпосередньо записувати дані. Можна використовувати звичайне кодування, коли, наприклад, 10112=1110, або коди Гріючи, коли 1011G = 11102 = 1410. Не дивлячись на те, що коди Гріючи неминуче призводять до кодування/декодування даних, вони дозволяють уникнути деяких проблем, які виникають в результаті звичайного кодування. Можна лише сказати, що перевага кодів Гріючи в тому, що якщо два числа є послідовними при кодуванні, то і їх двійкові коди розрізняються лише на один розряд, а в двійкових кодах це не так. Варто відзначити, що кодувати і декодувати в коди Гріючи можна так: спочатку копіюється самий старший розряд, потім виконується:
• з двійкового коди в код Гріючи: G[i]= XOR(B[i+1], B[i]);
• з коду Гріючи в двійковий код: B[i]= XOR(B[i+1], G[i]).
Тут, G[i] i-й розряд коду Гріючи, а B[i] - i-й розряд бінарного коду. Наприклад, послідовність чисел від 0 до 7 в двійковому коді: {000, 001, 010, 011, 100, 101, 110, 111}, а в кодах Гріючи: {000, 001, 011, 010, 110, 111, 101, 100}.
Загальна схема генетичного алгоритму може бути записана таким чином.
1. Формування початкової популяції.
2. Оцінка особин популяції.
3. Відбір (селекція).
4. Схрещування.
5. Мутація.
6. Формування нової популяції.
7. Якщо популяція не зійшлася, то 2. Інакше - завершення роботи.
Зупинимося детальніше на всіх етапах цього алгоритму.
Стандартний генетичний алгоритм починає свою роботу з формування початкової популяції 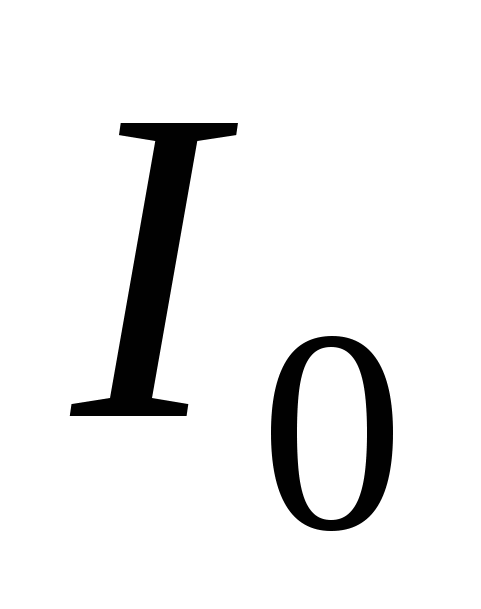 - скінченого набору допустимих розв'язків задачі. Ці розв'язки можуть бути вибрані випадковим чином або отримані за допомогою простих наближених алгоритмів. Вибір початкової популяції не має значення для збіжності процесу в асимптотиці, проте формування "хорошої" початкової популяції (наприклад, з множини локального оптимуму) може помітно скоротити час досягнення глобального оптимуму. Якщо відсутні припущення про місце розташування глобального оптимуму, то індивіди з початкової популяції бажано розподілити рівномірно по всьому простору пошуку розв'язку.
- скінченого набору допустимих розв'язків задачі. Ці розв'язки можуть бути вибрані випадковим чином або отримані за допомогою простих наближених алгоритмів. Вибір початкової популяції не має значення для збіжності процесу в асимптотиці, проте формування "хорошої" початкової популяції (наприклад, з множини локального оптимуму) може помітно скоротити час досягнення глобального оптимуму. Якщо відсутні припущення про місце розташування глобального оптимуму, то індивіди з початкової популяції бажано розподілити рівномірно по всьому простору пошуку розв'язку.
Для оптимізації будь-якої структури з використанням ГА, потрібно задати міру якості для кожного індивіда в просторі пошуку. Для цієї мети використовується функція пристосованості. У завданнях максимізації цільова функція часто сама виступає як функція пристосованості (наприклад, як в розглянутому раніше двовимірному прикладі); для завдань мінімізації цільову функцію слід інвертувати. Якщо задача, що розв'язується, має обмеження, виконання яких неможливо контролювати алгоритмічно, то функція пристосованості, як правило, включає також штрафи за невиконання обмежень (вони зменшують її значення).
На кожному кроці еволюції за допомогою імовірнісного оператора селекції (відбору) вибираються два розв'язки - батьки для їх подальшого схрещування. Серед операторів селекції найбільш поширеними є два імовірнісні оператори пропорційної і турнірної селекції. В деяких випадках також застосовується відбір усіканням.
Простий пропорційний відбір рулетка відбирає особини за допомогою n "запусків" рулетки. Колесо рулетки містить по одному сектору для кожного i-го члена популяції. Розмір i-го сектора пропорційний відповідній величині P(i). При такому відборі члени популяції з вищою пристосованістю з більшою вірогідністю частіше вибиратимуться, чим особини з низькою пристосованістю.
Турнірний відбір може бути описаний таким чином: з популяції, що містить m рядків (особин), вибирається випадковим чином t рядків і кращий рядок записується в проміжний масив (між вибраними рядками проводиться турнір). Ця операція повторюється m разів. Рядки в отриманому проміжному масиві потім використовуються для схрещування (також випадковим чином). Розмір групи рядків, що відбираються для турніру, часто рівний 2. В цьому випадку говорять про парний турнір. Взагалі ж t називається чисельністю турніру.
Дана стратегія використовує відсортовану за спадом популяцію. Число особин для схрещування вибирається відповідно до порогу 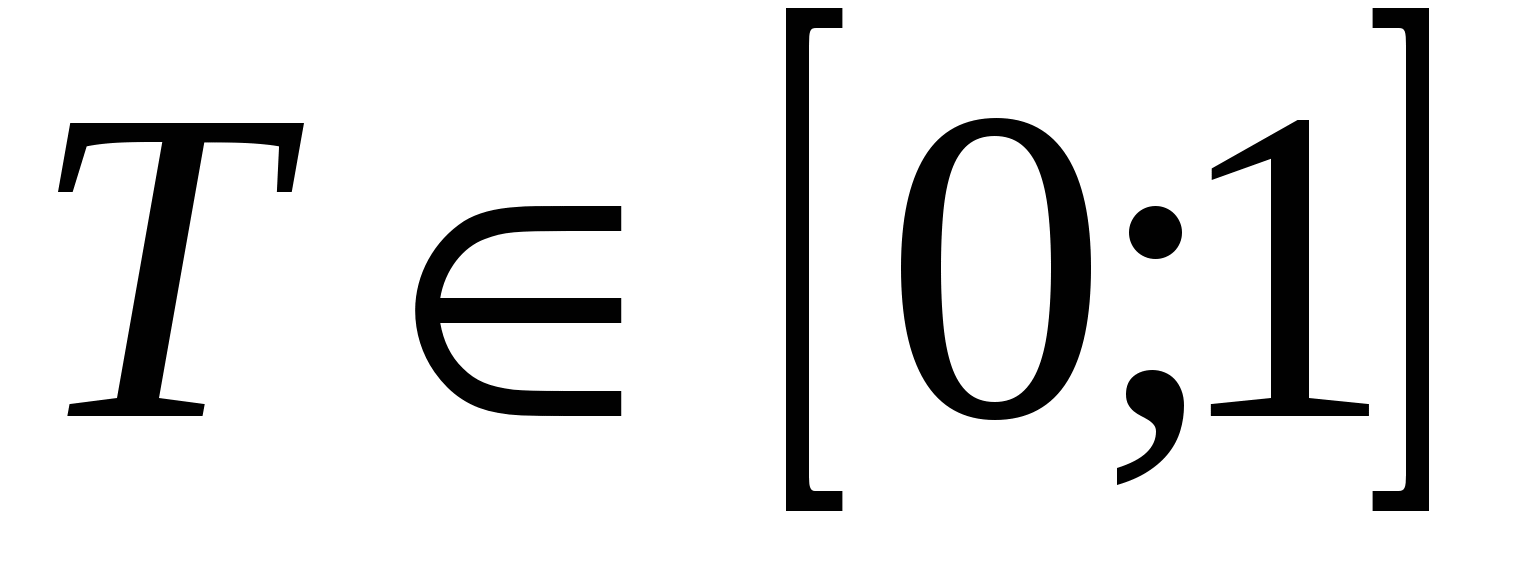 . Поріг визначає, яка доля особин, починаючи з найпершої, братиме участь у відборі. В принципі, поріг можна задати і рівним 1, тоді всі особини поточної популяції будуть допущені до відбору. Серед особин, допущених до схрещування випадковим чином m/2 разів вибираються батьківські пари, нащадки яких утворюють нову популяцію.
. Поріг визначає, яка доля особин, починаючи з найпершої, братиме участь у відборі. В принципі, поріг можна задати і рівним 1, тоді всі особини поточної популяції будуть допущені до відбору. Серед особин, допущених до схрещування випадковим чином m/2 разів вибираються батьківські пари, нащадки яких утворюють нову популяцію.
Як тільки два рішення-батька вибрано, до них застосовується імовірнісний оператор схрещування (crossover), який будує на їх основі нові (1 або 2) розв'язки-нащадка. Відібрані особини піддаються кросоверу (інколи званому рекомбінацією) із заданою вірогідністю 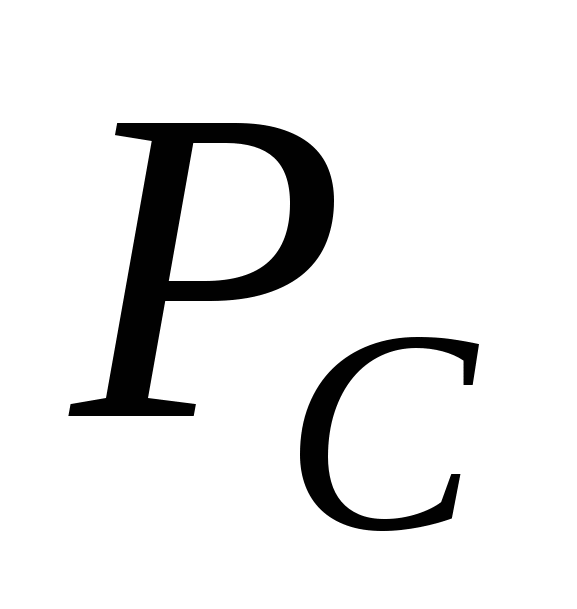 . Якщо кожна пара батьків породжує двох нащадків, для відтворення популяції необхідно схрестити m/2 пари. Для кожної пари з вірогідністю застосовується кросовер. Відповідно, з вірогідністю
. Якщо кожна пара батьків породжує двох нащадків, для відтворення популяції необхідно схрестити m/2 пари. Для кожної пари з вірогідністю застосовується кросовер. Відповідно, з вірогідністю 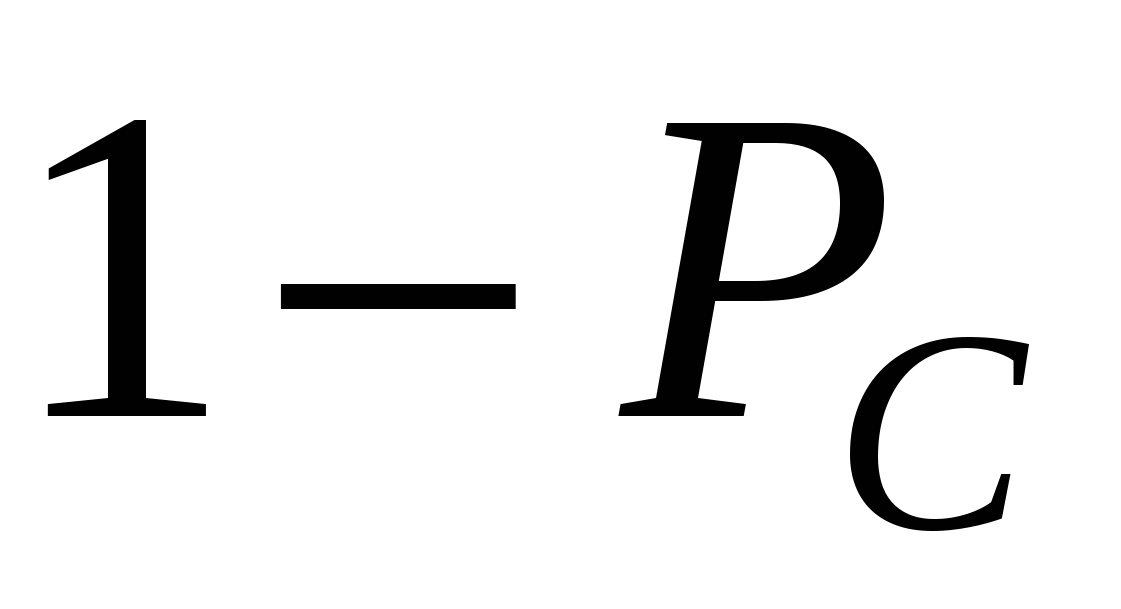 кросовер не відбувається і тоді незмінені особини переходять на наступну стадію (мутації).
кросовер не відбувається і тоді незмінені особини переходять на наступну стадію (мутації).
Існує велика кількість різновидів оператора схрещування. Простий одноточковий кросовер працює таким чином. Спочатку випадковим чином вибирається одна з можливих точок розриву. (Точка розриву ділянка між сусідніми бітами в рядку.) Обоє батьківської структури розриваються на два сегменти по цій крапці. Потім відповідні сегменти різних батьків склеюються і виходять два генотипи нащадків, як показано на мал. 3.
1
0
0
1
0
1
1
0
1
0
0
1
0
1
0
0
0
1
1
0
0
1
1
1
Батько 1
Батько 2
1
0
0
1
0
1
1
0
0
1
1
1
0
1
0
0
0
1
1
0
1
0
0
1
Нащадок 1
Нащадок 2
Мал. 3. Приклад роботи одноточечного кросовера
Наразі дослідники ГА пропонують багато інших операторів схрещування. Двоточковий кросовер і рівномірний кросовер сповна гідні альтернативи одноточковому операторові. У двоточковому кросовері вибираються дві точки розриву, і батьківські хромосоми обмінюються сегментом, який знаходиться між двома цими крапками. У рівномірному кросовері кожен біт першого нащадка випадковим чином успадковується від одного з батьків; другому нащадкові дістається біт іншого батька.
Після того, як закінчиться стадія кросовера, нащадки можуть піддаватися випадковим модифікаціям, званим мутаціями. У простому випадку в кожній хромосомі, яка піддається мутації, кожен біт з вірогідністю  змінюється на протилежний - так звана одноточкова мутація, що показана на мал. 4.
змінюється на протилежний - так звана одноточкова мутація, що показана на мал. 4.
-
1
0
0
1
0
1
1
0
0
1
1
1
-
1
0
0
1
0
1
0
0
0
1
1
1
Мал. 4. Приклад дії мутації
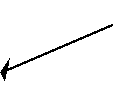
Складнішим різновидом мутації є оператори інверсії і транслокації. Інверсія - це перестановка генів в зворотному порядку усередині навдогад вибраної ділянки хромосоми. Приклад дії інверсії зображено на мал. 5.
-
 1
1 0
0
1
1
1
1
0
0
1
1
1
-
1
0
0
1
0
0
1
1
1
1
1
1
Мал. 5. Приклад дії інверсії
Варто відзначити, що всі перераховані генетичні оператори (одноточковий і багатоточковий кросовер, одноточечна мутація, інверсія) мають схожі біологічні аналоги.
У деяких роботах пропонується використовувати стратегію інцеста як механізму самоадаптации оператора мутації. Вона полягає в тому, що вірогідність мутації кожного гена визначається для кожного нащадка на підставі генетичної близькості його батьків. Наприклад, це може бути відношення числа співпадаючих генів батьків до загального числа генів хромосоми. Це наводить до цікавого ефекту при високій різноманітності генофонду популяції наслідку мутації будуть мінімальними, що дозволяє операторові схрещування працювати без стороннього втручання. У разі ж пониження різноманітності, що виникає в основному при застряванні алгоритму в локальному оптимумі, наслідки мутації стають відчутнішими, а при повному сходженні популяції алгоритм просто стає стахостическим, що збільшує вірогідність виходу популяції з локального оптимуму.
Інколи з метою підвищення середньої пристосованості популяції допустимо здійснювати направлені мутації, тобто після кожної зміни хромосоми перевіряти, чи підвищилася в результаті цієї мутації її пристосованість і, якщо немає, повертати хромосому до вихідного стану.
Після схрещування і мутації особин необхідно визначити, які з нових особин увійдуть до наступного покоління, а які - ні, і що робити з їх предками. Є два найбільш поширених способу.
1. Нові особини (нащадки) займають місця своїх батьків. Після чого настає наступний етап, в якому нащадки оцінюються, відбираються, дають потомство і поступаються місцем своїм "дітям".
2. Наступна популяція включає як батьків, так і їх нащадків.
У другому випадку необхідно додатково визначити, які з особин батьків і нащадків попадуть в нове покоління. У простому випадку, в нього після кожного схрещування включаються дві кращі особини з четвірки батьків і їх нащадків. Ефективнішим є механізм витіснення, який реалізується таким чином, що прагне видаляти «схожі» хромосоми з популяції і залишати що відрізняються. При цьому використовують принцип «елітизму». Суть цього принципу полягає в тому, що в нове покоління завжди включаються кращі батьківські особини. Їх число може бути від 1 і більше. Використання «елітизму» дозволяє не втратити хороший проміжний розв'язок, але в той же час через це алгоритм може "застрягти" в локальному екстремумі. В більшості випадків «елітизм» не шкодить пошуку розв'язку, і головним завданням є це надання алгоритму можливості аналізу різних хромосом з простору пошуку.
Робота ГА є ітераційним процесом, який продовжується до тих пір, поки не пройде задане число поколінь або не виконається який-небудь інший критерій останову. У оптимізаційних завданнях традиційними критеріями останову алгоритму є, наприклад, тривала відсутність прогресу в сенсі поліпшення значення середньої (або кращою) пристосованості популяції, мала різниця між кращим і гіршим значенням пристосованості для поточної популяції і тому подібне.
1.2. Оптимізаційні задачі.
В даний час оптимізація знаходить застосування в науці, техніці і в будь-якій іншій області людської діяльності.
Оптимізація - цілеспрямована діяльність, що полягає в отриманні якнайкращих результатів за відповідних умов.
Пошуки оптимальних рішень привели до створення спеціальних математичних методів і вже в 18 столітті були закладені математичні основи оптимізації (варіаційне числення, чисельні методи і др). Проте до другої половини 20 століть методи оптимізації в багатьох областях науки і техніки застосовувалися дуже рідко, оскільки практичне використання математичних методів оптимізації вимагало величезної обчислювальної роботи, яку без ЕОМ реалізувати було украй важко, а у ряді випадків - неможливо.
Постановка завдання оптимізації припускає існування конкуруючих властивостей процесу, наприклад:
кількість продукції - витрата сировини
кількість продукції - якість продукції
Вибір компромиcного варіанту для вказаних властивостей і є процедурою рішення оптимізаційної задачі.
При постановці завдання оптимізації необхідно:
1. Наявність об'єкту оптимізації і мети оптимізації. При цьому формулювання кожного завдання оптимізації повинне вимагати екстремального значення лише однієї величини, тобто одночасно системі не повинно приписуватися два і більш за критерії оптимізації, оскільки практично завжди екстремум одного критерію не відповідає екстремуму іншого. Приведемо приклади.
Типовий приклад неправильної постановки завдання оптимізації:
«Отримати максимальну продуктивність при мінімальній собівартості».
Помилка полягає в тому, що ставиться завдання пошуку оптимальності 2-х величин, що суперечать один одному за своєю суттю.
Правильна постановка завдання могла бути наступна:
а) отримати максимальну продуктивність при заданій собівартості;
б) отримати мінімальну собівартість при заданій продуктивності;
У першому випадку критерій оптимізації - продуктивність а в другому - собівартість.
2. Наявність ресурсів оптимізації, під якими розуміють можливість вибору значень деяких параметрів об'єкту, що оптимізується.
3. Можливість кількісної оцінки величини, що оптимізується, оскільки тільки в цьому випадку можна порівнювати ефекти від вибору тих або інших дій, що управляють.
4. Облік обмежень.
Величина, що зазвичай оптимізується, пов'язана з економічністю роботи даного об'єкту (апарат, цех, завод). Варіант роботи об'єкту, що оптимізується, повинен оцінюватися якоюсь кількісною мірою - критерієм оптимальності.
Критерієм оптимальності називається кількісна оцінка якості об'єкту, що оптимізується.
На підставі вибраного критерію оптимальності складається цільова функція, що є залежністю критерію оптимальності від параметрів, що впливають на її значення. Вид критерію оптимальності або цільової функції визначається конкретним завданням оптимізації.
Таким чином, завдання оптимізації зводиться до знаходження екстремуму цільової функції.
Залежно від своєї постановки, будь-яке із завдань оптимізації може вирішуватися різними методами, і навпаки - будь-який метод може застосовуватися для вирішення багатьох завдань. Методи оптимізації можуть бути скалярними (оптимізація проводиться по одному критерію), векторними (оптимізація проводиться по багатьом критеріям), пошуковими (включають методи регулярного і методи випадкового пошуку), аналітичними (методи диференціального числення, методи варіаційного числення і ін.), обчислювальними (засновані на математичному програмуванні, яке може бути лінійним, нелінійним, дискретним, динамічним, стохастичним, евристичним і т.д.), теоретико-імовірнісними, теоретико-ігровими і ін. Піддаватися оптимізації можуть завдання як з обмеженнями, так і без них.
Лінійне програмування - один з перших і найбільш детально вивчених розділів математичного програмування. Саме лінійне програмування з'явилося тим розділом, з якого початку розвиватися сама дисципліна «математичне програмування». Термін «програмування» в назві дисципліни нічого спільного з терміном «програмування (тобто складання програм) для ЕОМ» не має, оскільки дисципліна «лінійне програмування» виникла ще до того часу, коли ЕОМ стали широко застосовуватися при рішенні математичних, інженерних, економічних і ін. завдань. Термін «лінійне програмування» виник в результаті неточного перекладу англійського «linear programming». Одне із значень слова «programming» - складання планів, планування. Отже, правильним перекладом «Linear programming» було б не «лінійне програмування», а «лінійне планування», що точніше відображає зміст дисципліни. Проте, термін лінійне програмування, нелінійне програмування і т.д. в наший літературі стали загальноприйнятими.
Отже, лінійне програмування виникло після Другої Світової Війни і став швидко розвиватися, привертаючи увагу математиків, економістів і інженерів завдяки можливості широкого практичного застосування, а так само математичній «стрункості».
Можна сказати, що лінійне програмування застосовне для побудови математичних моделей тих процесів, в основу яких може бути покладена гіпотеза лінійного представлення реального миру: економічних завдань, завдань управління і планування, оптимального розміщення устаткування і ін.
Завданнями лінійного програмування називаються завдання, в яких лінійні як цільова функція, так і обмеження у вигляді рівності і нерівностей. Стисло завдання лінійного програмування можна сформулювати таким чином: знайти вектор значень змінних, що доставляють екстремум лінійної цільової функції при m обмеженнях у вигляді лінійної рівності або нерівностей.
Лінійне програмування є найбільш часто використовуваним методом оптимізації. До завдань лінійного програмування можна віднести завдання:
-
раціонального використання сировини і матеріалів; завдання оптимізації розкроу;
-
оптимізації виробничої програми підприємств;
-
оптимального розміщення і концентрації виробництва;
-
складання оптимального плану перевезень, роботи транспорту;
-
управління виробничими запасами;
-
і багато інших, що належать сфері оптимального планування.
Так, по оцінках американських експертів, близько 75% від загального числа вживаних оптимізаційних методів доводиться на лінійне програмування. Близько чверті машинного часу, витраченого останніми роками на проведення наукових досліджень, була відведена рішенню завдань лінійного програмування і їх численних модифікацій.
Перші постановки завдань лінійного програмування були сформульовані відомим радянським математиком Л.В. Канторовичем, якому за ці роботи була присуджена Нобелівська премія по економіці.
Значний розвиток теорія і алгоритмічний апарат лінійного програмування отримали з винаходом і розповсюдженням ЕОМ і формулюванням американським математиком Дж. Данцингом симплекс-метода.
В даний час лінійне програмування є одним з найбільш споживаних апаратів математичної теорії оптимального ухвалення рішення. Для вирішення завдань лінійного програмування розроблено складне програмное забезпечення, що дає можливість ефективно і надійно вирішувати практичні завдання великих об'ємів. Ці програми і системи забезпечені розвиненими системами підготовки початкових даних, засобами їх аналізу і представлення отриманих результатів.
У розвиток і вдосконалення цих систем вкладена праця і талант багатьох математиків, закумульований досвід рішення тисяч завдань. Володіння апаратом лінійного програмування необхідне кожному фахівцеві в області математичного програмування. Лінійне програмування тісно пов'язане з іншими методами математичного програмування (наприклад, нелінійного програмування, де цільова функція нелінійна).
Завдання з нелінійною цільовою функцією і лінійними обмеженнями називають завданнями нелінійного програмування з лінійними обмеженнями. Оптимізаційні завдання такого роду можна класифікувати на основі структурних особливостей нелінійних цільових функцій. Якщо цільова функція Е - квадратична функція, то ми маємо справу із завданням квадратичного програмування; якщо Е - це відношення лінійних функцій, то відповідне завдання носить назву завдання лінійного для дробу програмування, і т.д. Ділення оптимізаційних завдань на ці класи представляє значний інтерес, оскільки специфічні особливості тих або інших завдань грають важливу роль при розробці методів їх рішення.
Сучасні методи лінійного програмування досить надійно вирішують завдання загального вигляду з декількома тисячами обмежень і десятками тисяч змінних. Для вирішення надвеликих завдань використовуються вже, як правило, спеціалізовані методи.
Розділ 2. Побудова контрольних тестів булевих функцій.
2.1. Реалізація булевих функцій.
Для ефективного опису схем, за якими конструюють сполучення різних вентилів, потрібний особливий тип алгебри, у якій всі змінні й функції можуть приймати тільки два значення: 0 і 1. Така алгебра називається булевою алгеброю. Вона названа на честь англійського математика Джорджа Буля (1815-1864). Насправді в цьому випадку ми говоримо про особливий тип булевої алгебри, а саме про алгебру релейних схем, але термін "булева алгебра" дуже часто використається в значенні "алгебра релейних схем", тому ми не будемо їх розрізняти.
Як і у звичайній алгебрі, в булевій алгебрі є свої функції. Булева функція [1, 4, 5, 9, 13] має одну або кілька змінних і видає результат, що залежить тільки від значень цих змінних. Можна визначити просту функцію f, сказавши, що f(A)=l, якщо А=0, і f(A)=0, якщо А=1. Така функція буде функцією НЕ (див. рис. 2, а).
Булева функція від N змінних має 2N можливих комбінацій значень змінних, таку функцію можна повністю описати в таблицею з 2N рядками. У кожному рядку буде даватися значення функції для різних комбінацій значень змінних. Така таблиця називається таблицею істинності. Домовимося завжди розташовувати рядки таблиці істинності порядку номерів, тобто для двох змінних в порядку 00, 01, 10, 11, то функцію можна повністю описати 2-бітним двійковим числом, що виходить якщо зчитувати по вертикалі колонку результатів у таблиці істинності. Таким чином, НЕ-І - це 1110, НЕ- АБО - 1000, І - 0001 та АБО - 0111. Очевидно, що існує тільки 16 булевих функцій від двох змінних, котрим відповідають 16 можливих 4-бітних ланцюгів. У звичайній алгебрі існує нескінченне число функцій від двох змінних, і жодну з них не можна описати, давши таблицю значень цієї функції.
На рис. 1 (а) показана таблиця істинності для булевої функції від трьох змінних: M = f(A, В, С). Це функція більшості, що приймає значення 0, якщо більшість змінних дорівнює 0 та 1 якщо більшість змінних дорівнює 1. Хоча будь-яка булева функція може бути визначена за допомогою таблиці істинності, зі зростанням кількості змінних такий тип запису стає громіздким. Тому замість таблиць істинності часто використається інший тип запису. Щоб побачити, яким чином здійснюється цей інший тип запису, відмітимо що будь-яку булеву функцію можна визначити, вказавши, які комбінації значень змінних дають значення функції 1. Для функції, наведеної на рис. 1(б) існує 4 комбінації змінних, які дають значення функції 1.
Заперечення змінної 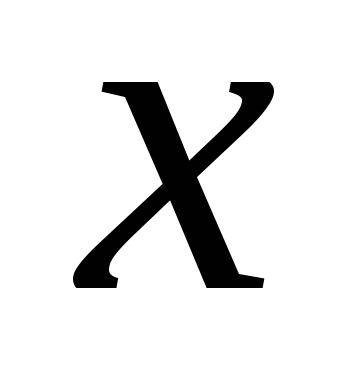 позначатимемо
позначатимемо ![]() . Крім того, ми будемо використати знак
. Крім того, ми будемо використати знак  або
або  для зазначення булевої функції "І" та знак
для зазначення булевої функції "І" та знак  для позначення булевой функції АБО. Наприклад,
для позначення булевой функції АБО. Наприклад, 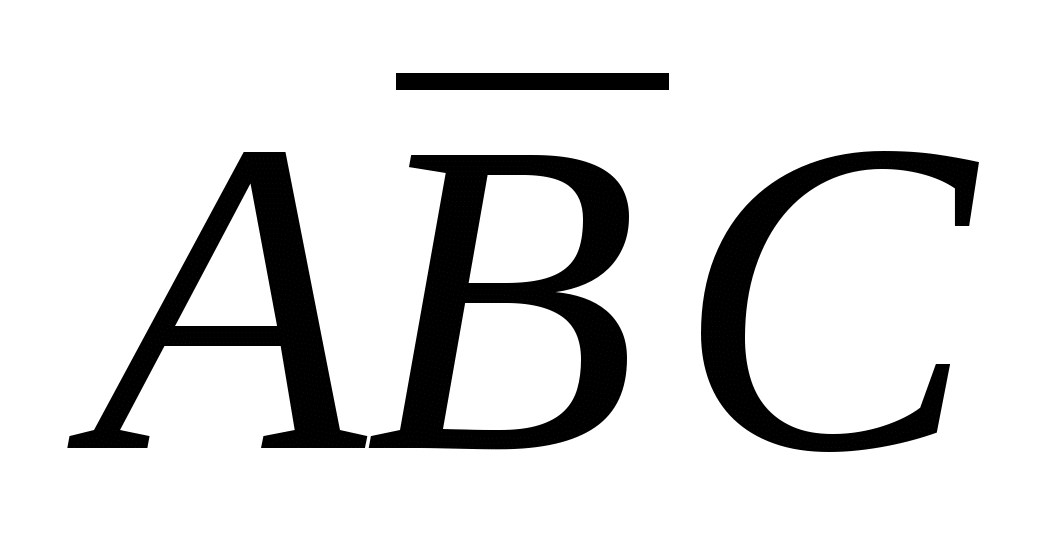 приймає значення 1, тільки якщо А=1, В=0 та С=1.
приймає значення 1, тільки якщо А=1, В=0 та С=1. 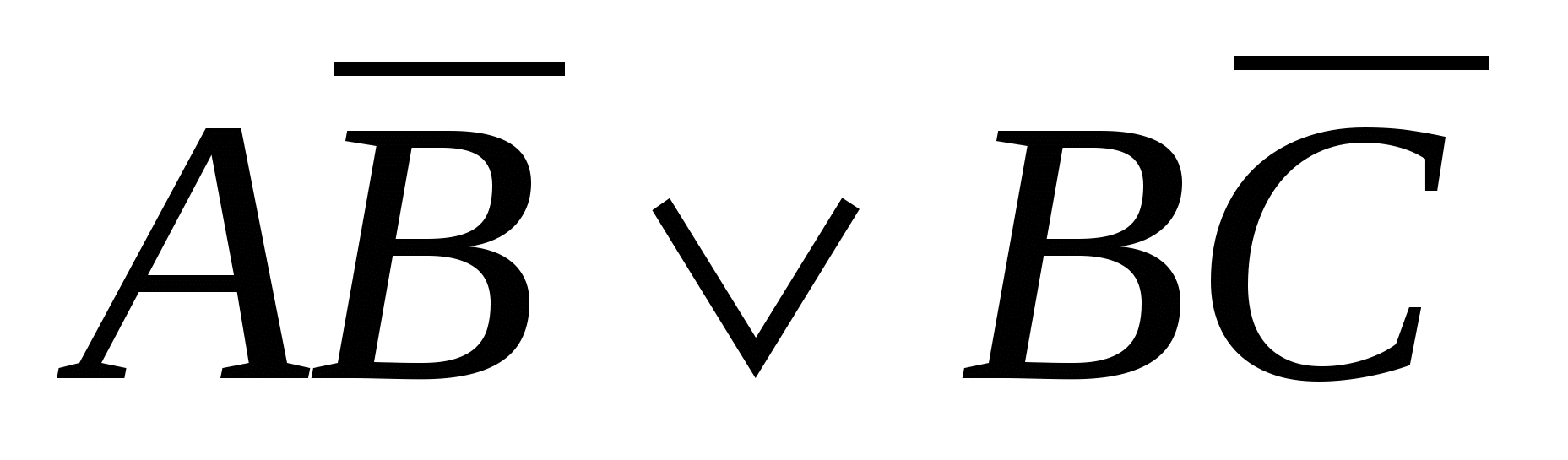 приймає значення 1, тільки якщо (А=1 і В=0) або (В=1 і С=0). У таблиці на рис. 1(а) функція приймає значення 1 у чотирьох рядках:
приймає значення 1, тільки якщо (А=1 і В=0) або (В=1 і С=0). У таблиці на рис. 1(а) функція приймає значення 1 у чотирьох рядках: 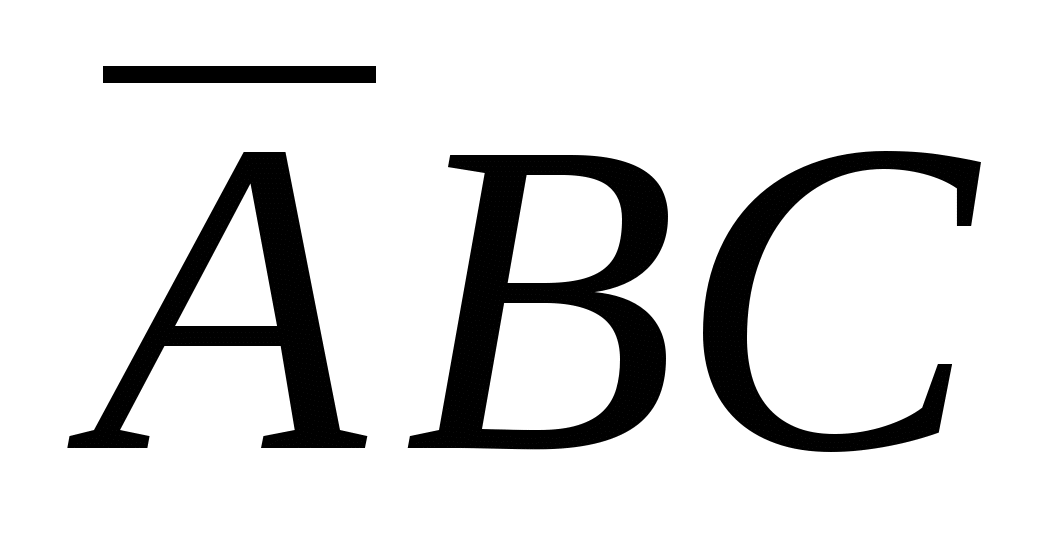 , ,
, , 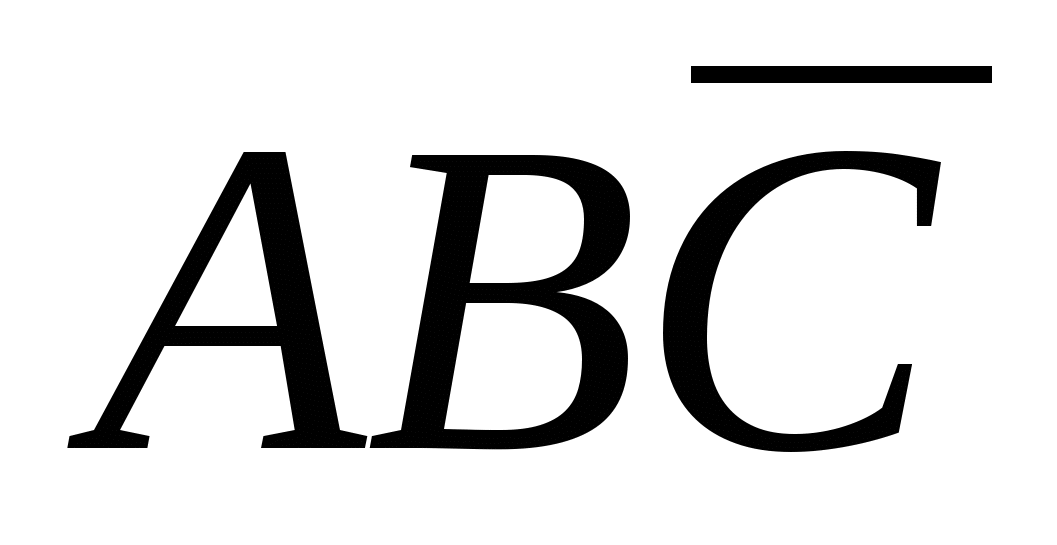 , та
, та 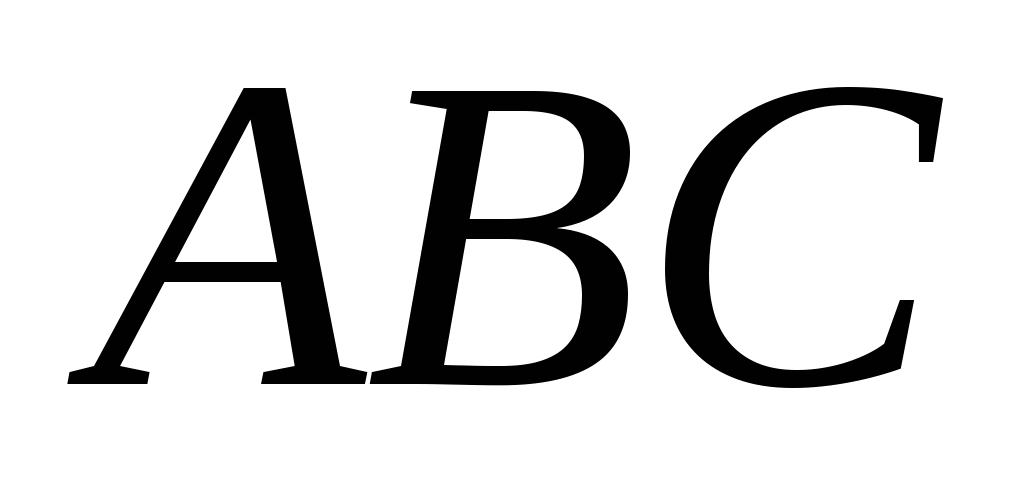 . Функція М приймає значення істини (тобто 1), якщо одне із цих чотирьох умов істинно. Отже, ми можемо написати
. Функція М приймає значення істини (тобто 1), якщо одне із цих чотирьох умов істинно. Отже, ми можемо написати 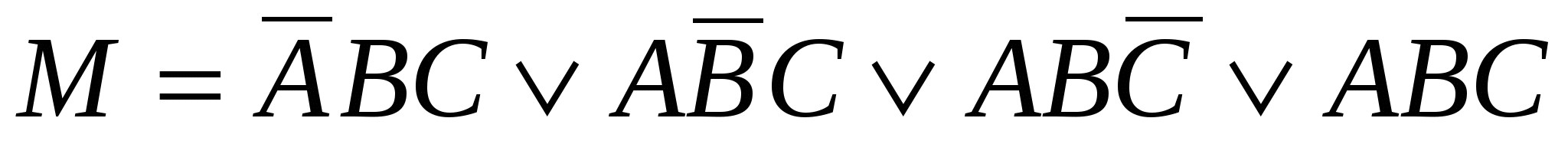 .
.
Це компактний запис таблиці істинності. Важливо розуміти розходження між абстрактної булевою функцією та її реалізацією за допомогою електронної схеми. Булева функція складається зі змінних, наприклад А, В та С, та операторів І, АБО та НЕ. Булева функція описується за допомогою таблиці істинності або спеціального запису, наприклад, 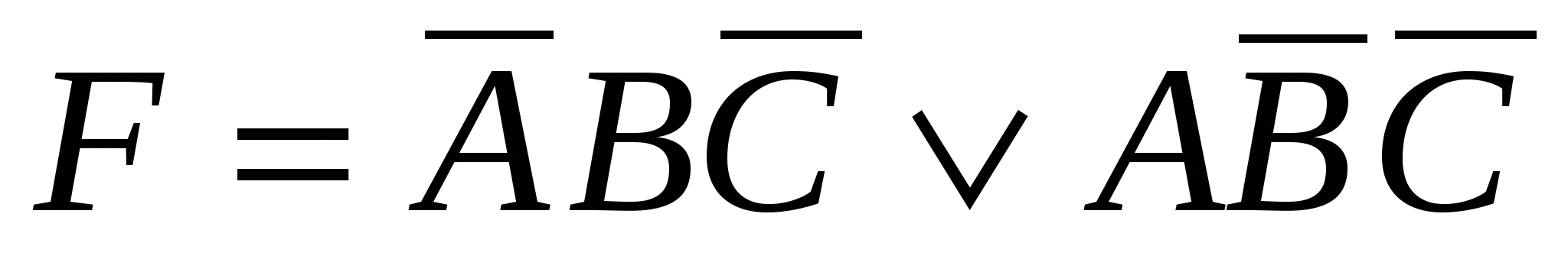 .
.
Булева функція може реалізовуватися за допомогою електронної схеми (часто різними способами) з використанням сигналів, які представляють вхідні та вихідні змінні, та вентилів, наприклад - І, АБО та НЕ.
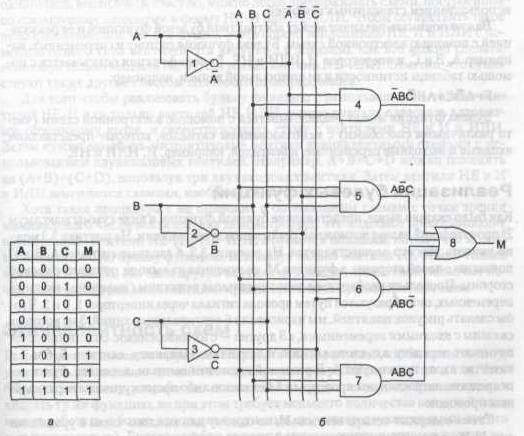
Рис. 1. Таблиця істинності для функції більшості від трьох
змінних (а); схема для цієї функції (б)
Як було сказано вище, представлення булевої функції у вигляді суми максимум 2N добутків дає можливість реалізації цієї функції.
На малюнку 3.3 можна побачити, як здійснюється реалізації функції у вигляді суми добутків. Вхідні сигнали А, В та С показано з лівої сторони, а функція М, отримана на виході, показана із правої сторони. Оскільки необхідні додаткові величини (інверсії) вхідних змінних, вони утворюються шляхом проведення сигналу через інвертори 1,2 і 3. Щоб зробити малюнок зрозумілим, намалюємо 6 вертикальних ліній, 3 з яких пов'язані із вхідними змінними, а 3 інших - з їхніми інверсіями. Ці лінії забезпечують передачу вхідного сигналу до вентилів.
Схема містить чотири вентилі "І", по одному для кожного члена в рівнянні для М (тобто по одному для кожного рядка в таблиці істинності з результатом 1). Кожний вентиль "І" обчислює однин із зазначених рядків таблиці істинності. Зрештою всі дані добутків сумуються (мається на увазі операція АБО) для одержання кінцевого результату.
Будемо використати наступне позначення: якщо дві лінії на малюнку перетинаються, зв'язок мається на увазі тільки в тому випадку, якщо на перетинанні зазначена жирна крапка. Наприклад, вихід вентиля 3 перетинає всі 6 вертикальних ліній, але зв'язаний він тільки із С.
Таким чином, будемо використовувати наступну схему реалізації будь-якої булевой функції:
-
Скласти таблицю істинності для даної функції.
-
Забезпечити інвертори, щоб породжувати інверсії для кожного вхідного сигналу.
-
Намалювати вентиль "І" для кожного рядка таблиці істинності з результатом.
-
З'єднати вентилі "І" з відповідними вхідними сигналами.
-
Вивести виходи всіх вентилів "І" в вентиль АБО.
Таким чином реалізовується будь-яка булева функцію з використанням вентилів НЕ, І та АБО. Однак набагато зручніше будувати схеми з використанням одного типу вентилів. Виявляється, можна легко перетворити схеми, побудовані по попередньому алгоритмі, у форму НЕ-І або НЕ-АБО.
Для того, щоб здійснити таке перетворення, потрібно вказати спосіб втілення операцій НЕ, І и АБО за допомогою одного типу вентилів. На рис. 2 показано, як це можна зробити, використовуючи тільки вентилі НЕ-І або тільки вентилі НЕ-АБО. Для того щоб реалізувати булеву функцію з використанням тільки вентилів НЕ-І або тільки вентилів НЕ-АБО, можна спочатку слідувати алгоритму, описаному вище, і сконструювати схему з вентилями НЕ, І та АБО.
Потім потрібно замінити багатовхідні вентилі еквівалентними схемами з використанням двохвхідних вентилів. Наприклад,  можна поміняти на
можна поміняти на  , використовуючи три двохвхідні вентилі. Потім вентилі НЕ, І та АБО заміняються схемами, зображеними на рис. 2. Хоча така процедура й не приводить до оптимальних схем з погляду мінімального числа вентилів, вона демонструє, що подібне перетворення може бути здійснено. Вентилі НЕ-І та НЕ-АБО вважаються повними, тому що можна
, використовуючи три двохвхідні вентилі. Потім вентилі НЕ, І та АБО заміняються схемами, зображеними на рис. 2. Хоча така процедура й не приводить до оптимальних схем з погляду мінімального числа вентилів, вона демонструє, що подібне перетворення може бути здійснено. Вентилі НЕ-І та НЕ-АБО вважаються повними, тому що можна
обчислити будь-яку булеву функцію, використовуючи тільки вентилі НЕ-І або тільки вентилі НЕ-АБО. Жоден інший вентиль не має такої властивості, це причиною того, що ці два типи вентилів кращі при побудові схем.
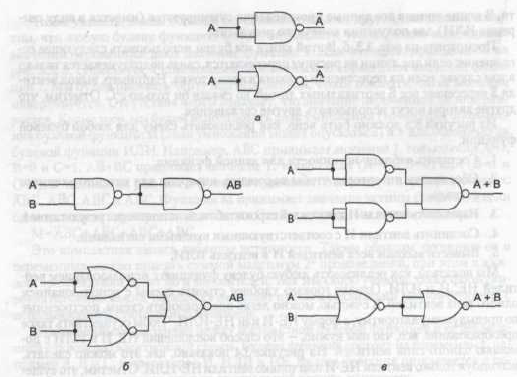
Рис.2. Конструювання вентилів НЕ (а), І (б) та АБО (в) з використанням
тільки вентилів НЕ-І або тільки вентилів НЕ-АБО
2.2. Проблематика діагностики булевих функцій та систем.
Розглянемо основні результати в області математичної теорії контролю справності і діагностики несправностей керуючих систем.
Нехай S деяка схема з функціональних елементів з одним виходом, що реалізовує булеву функцію. Елементи схеми S можуть приходити в несправний стан, внаслідок чого схема може реалізовувати функцію, відмінну від функції f.
Для забезпечення надійного функціонування схеми S необхідно розв'язати задачу контролю справності її елементів. Для розв'язку цієї завдання С.В.Яблонським [23,24] запропоновано логічні методи контролю, суть яких полягає в тому, що на входи схеми S подаються деякі спеціальним чином підібрані "перевіряючі" набори значень змінних 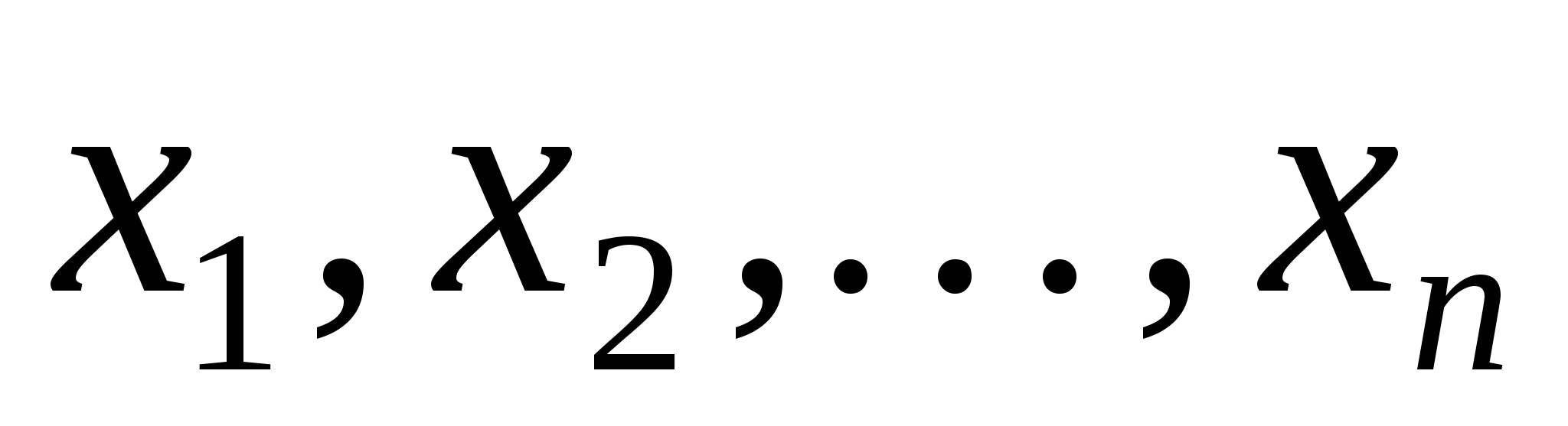 і на основі вихідних значень схеми робиться висновок про її справність і характер несправностей (при їх наявності).
і на основі вихідних значень схеми робиться висновок про її справність і характер несправностей (при їх наявності).
Функція, що реалізовується на виході схеми за наявності в схемі несправних елементів, називається функцією несправності. Будь-яка множина T вхідних наборів схеми S називається повним перевіряючим тестом для цієї схеми, якщо для будь-якої функції несправності g(x ), не дорівнює тотожньо f(x), тобто в T знайдеться хоч би один такий набір значень , що 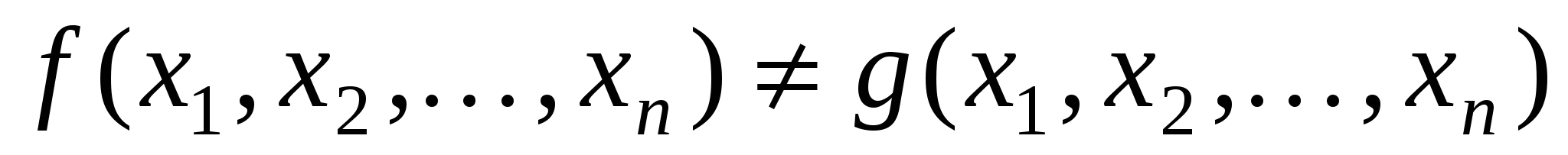 . Кількість наборів, що складають тест, називається довжиною тесту. За тривіальний завжди можна узяти тест, що містить всі
. Кількість наборів, що складають тест, називається довжиною тесту. За тривіальний завжди можна узяти тест, що містить всі 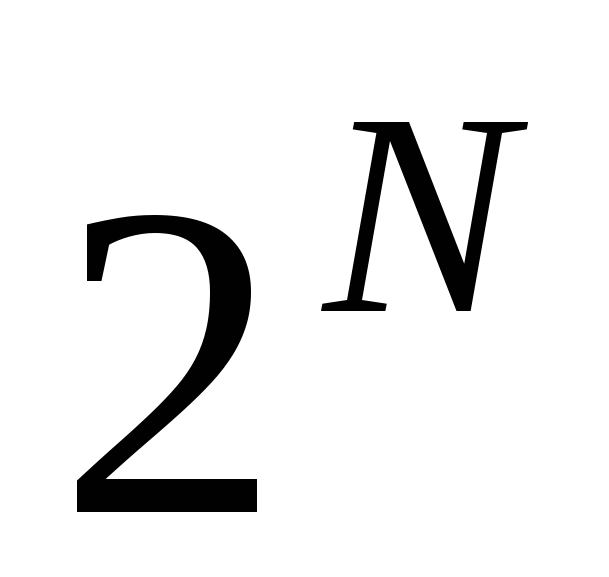 наборів значень змінних булевої функції від
наборів значень змінних булевої функції від 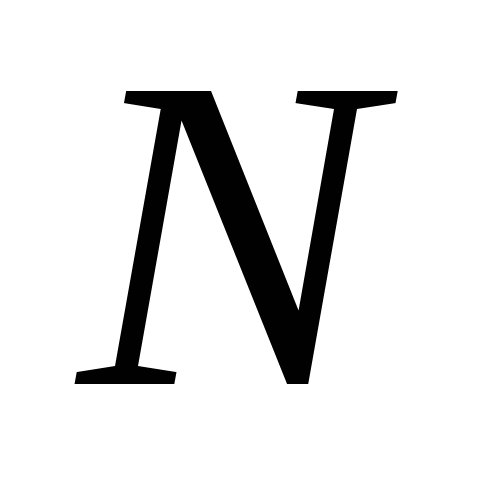 змінних.
змінних.
Але перш за все цікавою та важливою є задача побудови мінімальних тестів, тобто тестів мінімальної довжини. У простому випадку розв'язок задачі зводиться до перебору, що скрутно при зростанні . Відмітимо, що довжина мінімального тесту може істотно залежати і від вигляду схеми, що реалізовує задану функцію.
Нехай D(T) довжина тесту T; 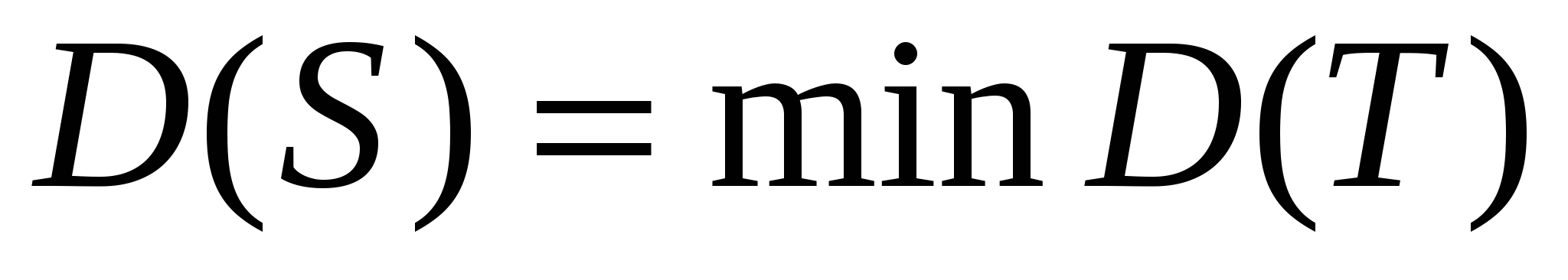 , де мінімум береться по всіх повних перевіряючих тестах T для схеми S;
, де мінімум береться по всіх повних перевіряючих тестах T для схеми S; 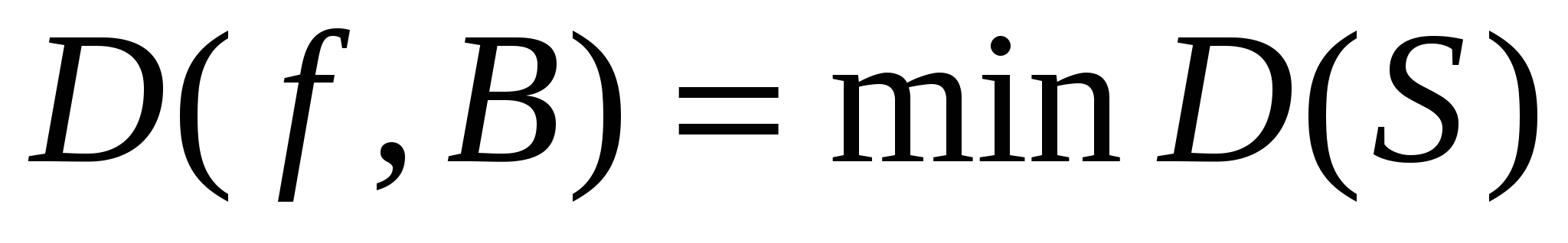 , де мінімум береться за всіма схемами S в даному базисі B, що реалізовує функцію f; тоді виконується:
, де мінімум береться за всіма схемами S в даному базисі B, що реалізовує функцію f; тоді виконується:
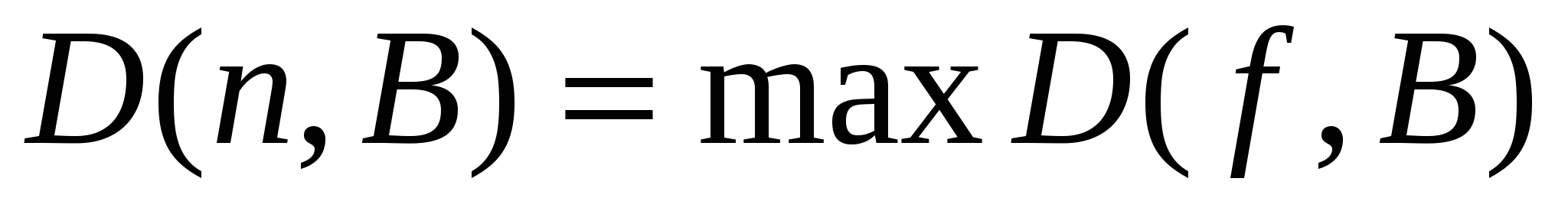 ,
,
де максимум береться по всіх булевих функціях f від змінних. Функція D(, B) називається функцією Шеннона довжини повного перевірюючого тесту для базису B.
Окрім перевіряючих тестів, розглядаються ще так звані діагностичні тести. Множина T вхідних наборів схеми S називається повним діагностичним тестом для цієї схеми, якщо T є повним перевіряючим тестом для S і для будь-яких двох різних функцій несправності 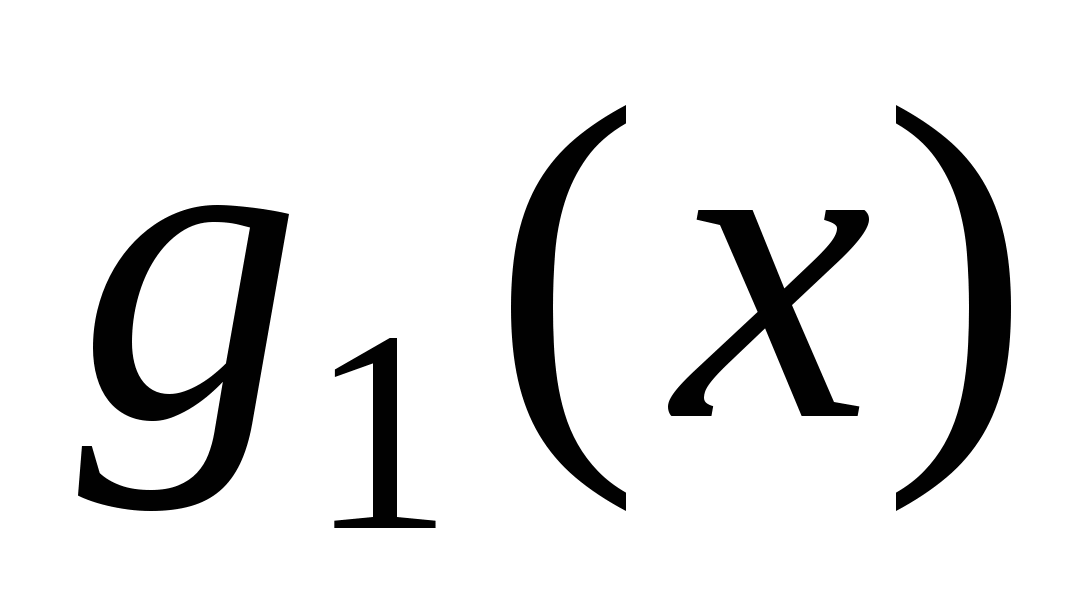 і
і 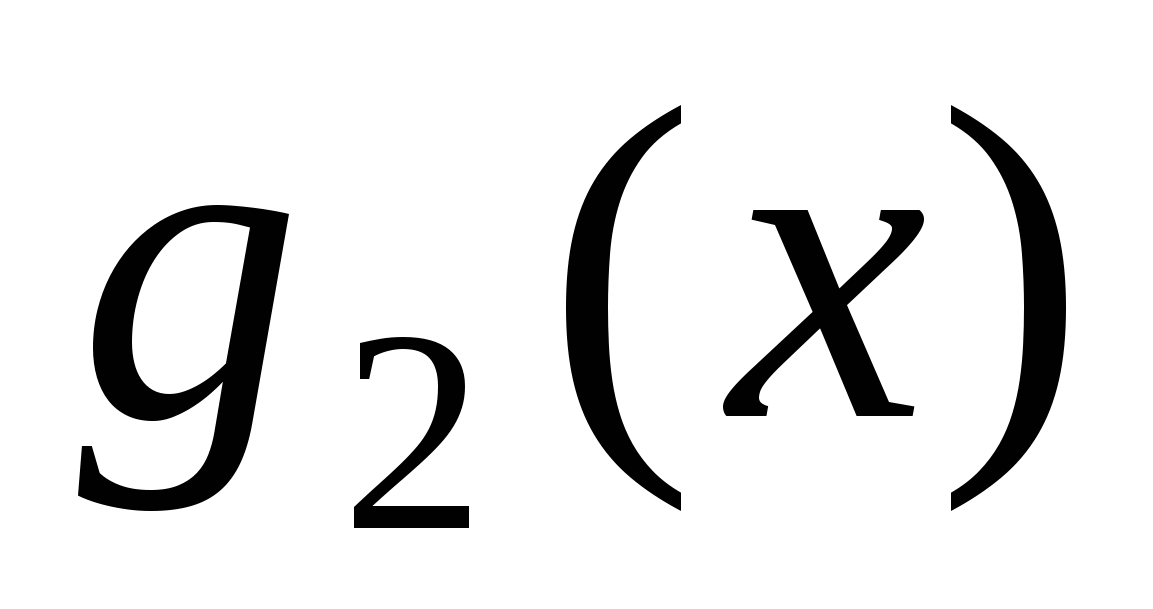 в T знайдеться такий набір значень , що
в T знайдеться такий набір значень , що 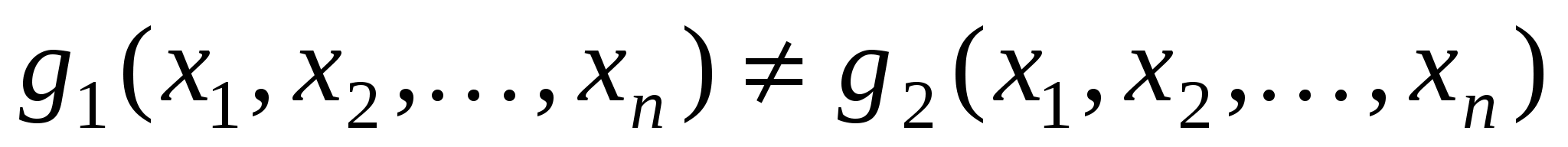 . Для довжин повних діагностичних тестів також визначається функція Шенона D(
. Для довжин повних діагностичних тестів також визначається функція Шенона D(![]() , B) в заданому базисі B.
, B) в заданому базисі B.
Наразі час завдання логічного контролю справності схем з функціональних елементів часто формулюються так: оцінити зверху і знизу (у ідеалі - знайти точні значення) величин D(f, B) і D(,B) для різних базисів B. Представляють інтерес також оцінки "проміжних" величин 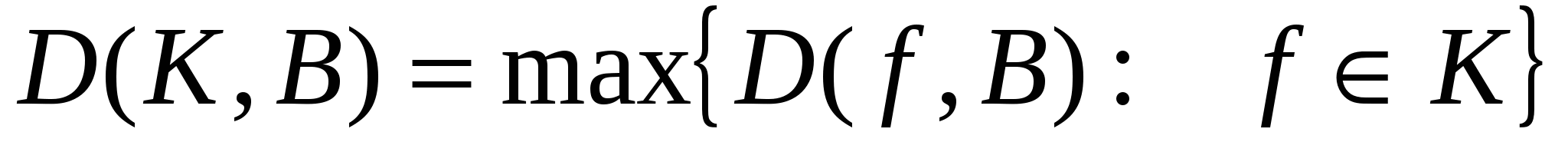 , де K деякий виділений клас булевих функцій від n змінних.
, де K деякий виділений клас булевих функцій від n змінних.
Для спрощення вирішення цих завдань існують наступні шляхи: обмеження типів можливих несправностей і їх кількості; вибір схем певного типа; вибір класу K булевих функцій; синтез легкотестуємих схем.
В даний час виділяються три основні типи несправностей: константні, однотипні константні і інверсні. Несправності кожного з вказаних типів можуть передбачатися або на входах, або на виходах елементів схеми. Константна несправність типа  (де дорівнює 0 або 1) на вході або виході елементу означає, що на цей вхід подається константа (відповідно, значення на виході цього елементу завжди дорівнює ). У загальному випадку значення може бути своїм в кожного несправного елементу. В разі однотипних константних несправностей значення є одним і тим же для всіх несправних елементів. Інверсна несправність на вході елементу означає, що значення, що подається на цей несправний вхід, протилежне до значення, що подається на справний вхід; інверсна несправність на виході означає, що значення на виході несправного елементу протилежно значенню на виході справного елементу.
(де дорівнює 0 або 1) на вході або виході елементу означає, що на цей вхід подається константа (відповідно, значення на виході цього елементу завжди дорівнює ). У загальному випадку значення може бути своїм в кожного несправного елементу. В разі однотипних константних несправностей значення є одним і тим же для всіх несправних елементів. Інверсна несправність на вході елементу означає, що значення, що подається на цей несправний вхід, протилежне до значення, що подається на справний вхід; інверсна несправність на виході означає, що значення на виході несправного елементу протилежно значенню на виході справного елементу.
Число несправних елементів в схемі може передбачатися або будь-яким, або не більшим за N. У останньому випадку зазвичай вважають N=1, та говорять про одиничні несправності даного типа і, відповідно, про довжину одиничного перевіряючого тесту або довжину одиничного діагностичного тесту.
При синтезі легкотестуємих схем головною метою є побудова схеми (із скільки завгодно великою складністю, без яких-небудь обмежень на порядок галуження виходів і так далі) з мінимально можливою довжиною перевіряючого тесту.
Основоположник математичної теорії тестів С.В.Яблонський і ряд його учнів і послідовників в основному розробляли логічні методи контролю контактних схем. Надалі істотна увага стала приділятися схемам з функціональних елементів, проте відповідна теорія для схем з функціональних елементів все ще далека від завершеності. Ряд важливих результатів в оцінюванні довжин тестів для схем з функціональних елементів при різних типах несправностей отриманий в роботах В.Н. Носкова [14], Н.П. Редькина [16 - 18], С.В. Коваценко [10], В.Г. Хахуліна [21].
Для одиничних константних несправностей на виходах елементів Редді довів, що для базису Жегалкина  . при будь-якому натуральному n функція Шенона D(n,B) довжини одиничного перевіряючого тесту в разі константних несправностей на виходах елементів задовольняє нерівності
. при будь-якому натуральному n функція Шенона D(n,B) довжини одиничного перевіряючого тесту в разі константних несправностей на виходах елементів задовольняє нерівності 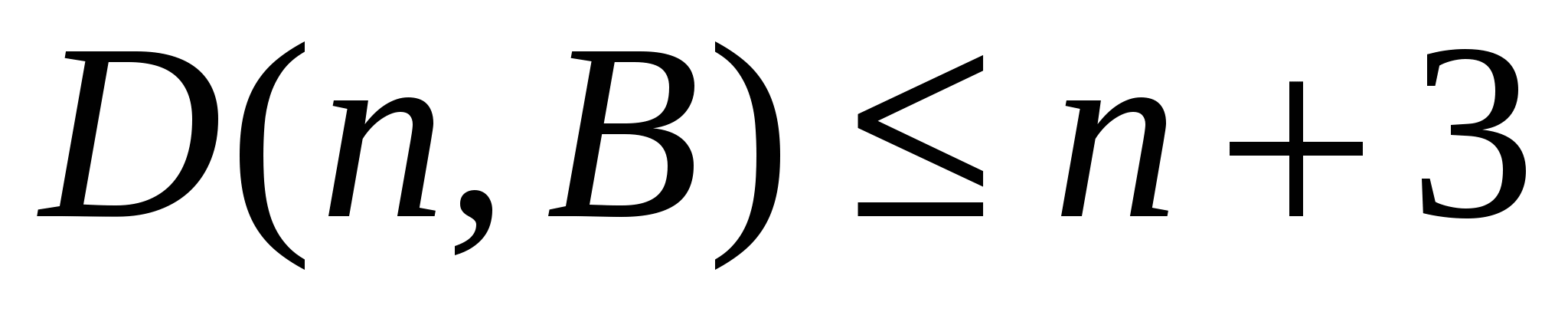 .
.
Для довільного повного скінченого базису B в разі константних несправностей на виходах елементів Н.П. Редькин одержав оцінку ![]() функції Шенона для довжини повного перевіряючого тесту. Він також же отримав асимптотичні оцінки функції Шенона довжини повного перевіряючого тесту в разі константних несправностей на входах елементів схем в стандартному базисі
функції Шенона для довжини повного перевіряючого тесту. Він також же отримав асимптотичні оцінки функції Шенона довжини повного перевіряючого тесту в разі константних несправностей на входах елементів схем в стандартному базисі 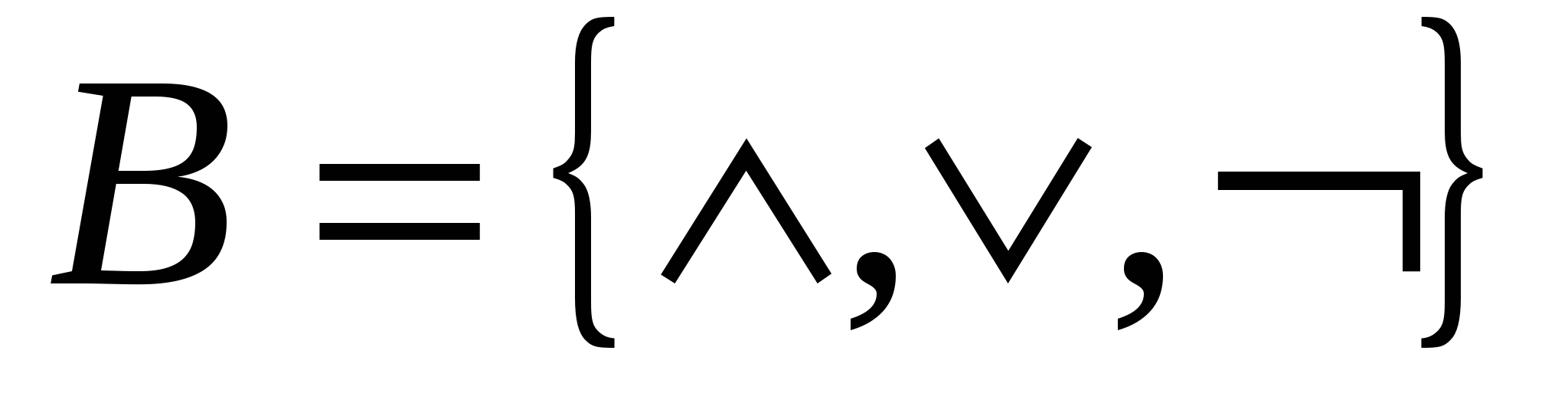 . В.Г.Хахулін оцінював довжини повних перевіряючих тестів в разі константних несправностей на входах елементів для реалізацій функції лічильника парності в довільному базисі.
. В.Г.Хахулін оцінював довжини повних перевіряючих тестів в разі константних несправностей на входах елементів для реалізацій функції лічильника парності в довільному базисі.
В разі однотипних константних несправностей верхні оценки функцій Шенона знайдені Н.П. Редькиним: при будь-якому натуральном n функція Шенона 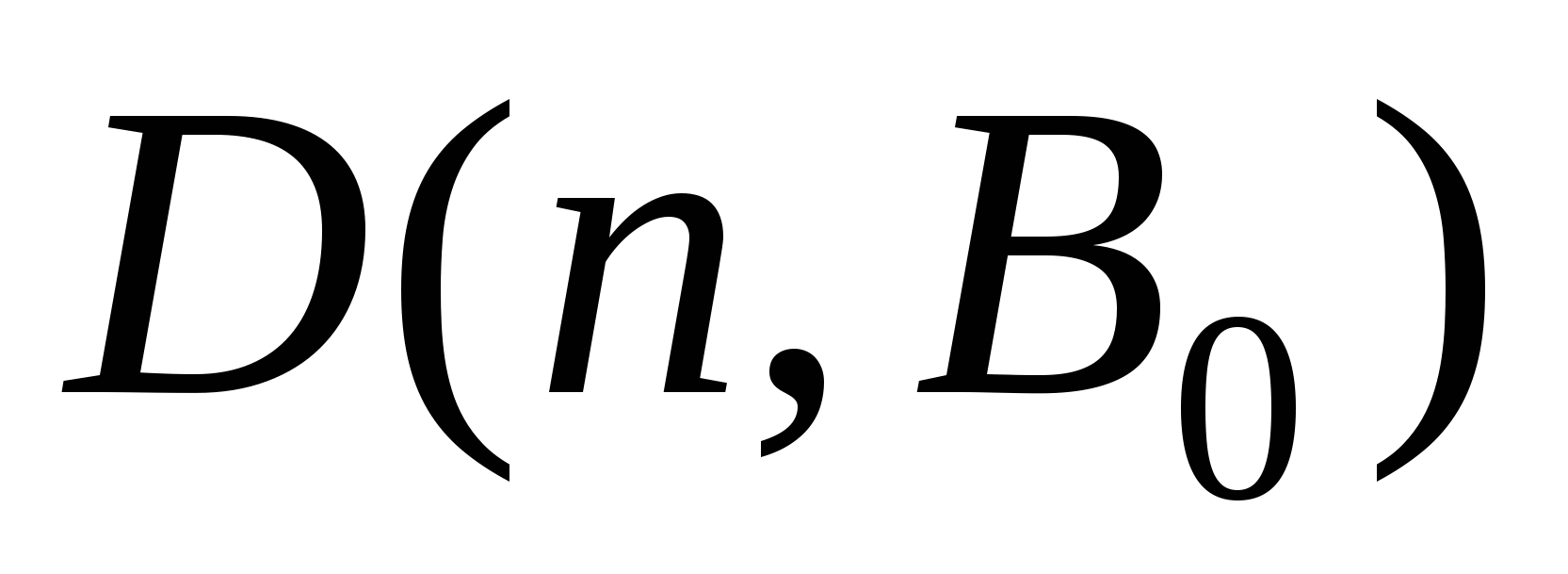 довжини повного перевіряючого тесту в разі однотипних константних несправностей на виходах елементів задовольняє нерівності
довжини повного перевіряючого тесту в разі однотипних константних несправностей на виходах елементів задовольняє нерівності 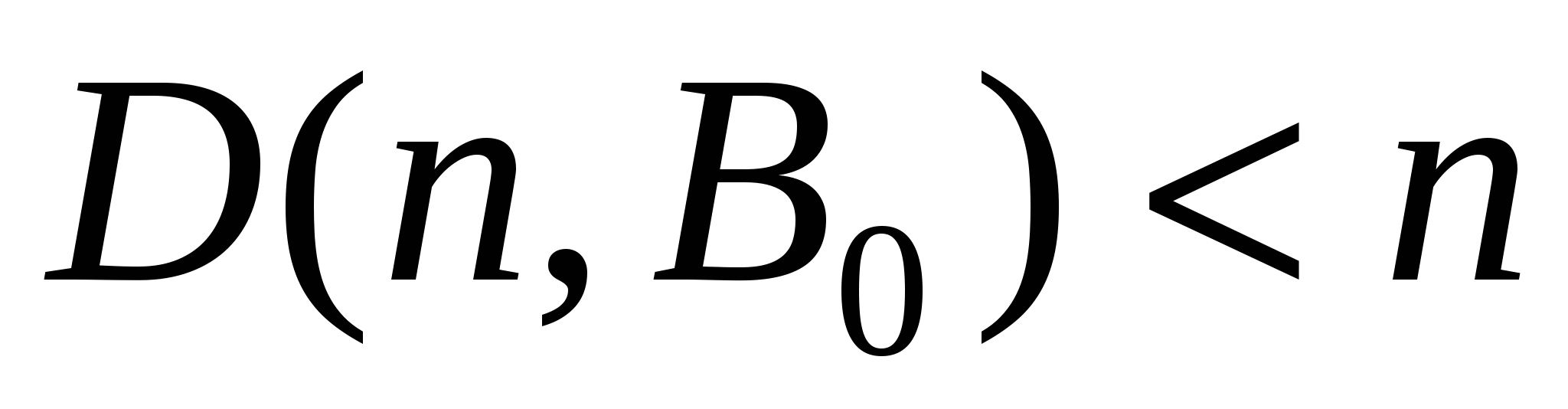 .
.
Крім того, для стандартного базису 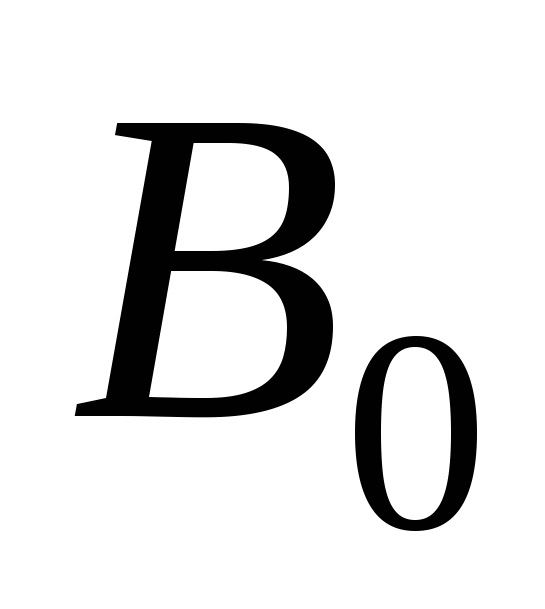 Н.П. Редькиним одержані оцінки довжин тестів у разі ж однотипних константних неполадки на входах елементів, а також довжин одиничних діагностичних тестів в разі однотипних константних несправностей на входах або на виходах елементів.
Н.П. Редькиним одержані оцінки довжин тестів у разі ж однотипних константних неполадки на входах елементів, а також довжин одиничних діагностичних тестів в разі однотипних константних несправностей на входах або на виходах елементів.
Для інверсних несправностей на виходах елементів оцінки функций Шенона довжин різних тестів отримані Н.П. Редькиним і С.В.Коваценко.
У серії робіт В.Н. Носкова запропоновані декілька інші методи логічного контролю схем з функціональних елементів (і загальніших логічних пристроїв).
Розділ 3. Розробка алгоритму ефективної побудови контрольних тестів булевих функцій.
3.1. Постановка задачі та основна ідея підходу.
За умовою задачі задається еталонна та тестова булеві функції. Необхідно з'ясувати, чи є , та потрібно вияснити чи вони еквівалентними.
Ця задача буде реалізуватися в програмному середовищі Delphi, з основами роботи в якому можна ознайомитися в [7, 20].
При розв'язку задачі ми порівнюємо ці дві функції на великій кількості наборів, і якщо їхня поведінка однакова на всіх цих наборах, то будемо вважати що ці функції еквівалентні. Формувати тестувальні набори будемо за допомогою генетичних операцій кросовер, мутації та здвигу.
Спочатку формуємо еталону та тестову функцію. Далі генеруємо набір тестових даних, за допомогою яких будемо перевіряти функції на еквівалентність. Якщо функції різні то в таблиці будуть різні результати. Але якщо вони однакові то вони на всі тести будуть реагувати однаково.
3.2. Реалізація.
Розглянемо програмну реалізацію алгоритму.
Формуємо тестову функцію, та записуємо її чисельне та буквені значення .
unit Unit1;
interface
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms,
Dialogs, StdCtrls, Grids, Menus, Buttons, ComCtrls;
type
TForm1 = class(TForm)
Button1: TButton;
StringGrid1: TStringGrid;
Button4: TButton;
Button5: TButton;
StringGrid2: TStringGrid;
Edit1: TEdit;
Button2: TButton;
Button7: TButton;
Edit2: TEdit;
Edit3: TEdit;
Edit4: TEdit;
Edit5: TEdit;
UpDown1: TUpDown;
Label1: TLabel;
Label2: TLabel;
StringGrid3: TStringGrid;
StringGrid4: TStringGrid;
Label3: TLabel;
Button8: TButton;
Edit6: TEdit;
UpDown2: TUpDown;
UpDown3: TUpDown;
Edit7: TEdit;
Label5: TLabel;
Label6: TLabel;
Button6: TButton;
Label7: TLabel;
Button9: TButton;
Button10: TButton;
Button11: TButton;
Button12: TButton;
Button3: TButton;
procedure Button12Click(Sender: TObject);
procedure Button11Click(Sender: TObject);
procedure Button10Click(Sender: TObject);
procedure Button6Click(Sender: TObject);
procedure Button3Click(Sender: TObject);
procedure kollt(Sender: TObject);
procedure kolld(Sender: TObject);
procedure Edit4Change(Sender: TObject);
procedure Button1Click(Sender: TObject);
procedure Button5Click(Sender: TObject);
procedure FormCreate(Sender: TObject);
procedure Button4Click(Sender: TObject);
procedure Button2Click(Sender: TObject);
procedure Button7Click(Sender: TObject);
procedure Button8Click(Sender: TObject);
procedure Button9Click(Sender: TObject);
procedure avto;
private
{ Private declarations }
public
{ Public declarations }
end;
const a1=64;a2=64;
var
Form1: TForm1;
hohl,hohlt,hohl1,hohl2,mohl,mohlt,mohl1,mohl2:string;
k,n,c,i,s:byte;
kolvo,zz,j,z,h,h1,h2,hi,kold,kolt:integer;
m1:array[1..8] of string;
m2,m3:array[1..100] of string;
implementation
uses Unit3;
{$R *.dfm}
procedure TForm1.Button10Click(Sender: TObject);
var n1,n2: integer;
begin
for I := 1 to 8 do begin
StringGrid2.Cells[1,i]:='';
StringGrid2.Cells[2,i]:='';
StringGrid4.Cells[1,i]:='';
StringGrid4.Cells[2,i]:='';
end;
n1:=kolvo div 2; //из первой таблицы делает вторую
for I:=1 to n1 do //меняет первые половины
begin
StringGrid3.Cells[i,1]:=StringGrid1.Cells[i,2];
StringGrid3.Cells[i,2]:=StringGrid1.Cells[i,1];
StringGrid3.Cells[i,3]:=StringGrid1.Cells[i,4];
StringGrid3.Cells[i,4]:=StringGrid1.Cells[i,3];
StringGrid3.Cells[i,5]:=StringGrid1.Cells[i,6];
StringGrid3.Cells[i,6]:=StringGrid1.Cells[i,5];
StringGrid3.Cells[i,7]:=StringGrid1.Cells[i,8];
StringGrid3.Cells[i,8]:=StringGrid1.Cells[i,7];
end;
for I:=n1+1 to kolvo do //дописует вторые половины как были
begin
StringGrid3.Cells[i,1]:=StringGrid1.Cells[i,1];
StringGrid3.Cells[i,2]:=StringGrid1.Cells[i,2];
StringGrid3.Cells[i,3]:=StringGrid1.Cells[i,3];
StringGrid3.Cells[i,4]:=StringGrid1.Cells[i,4];
StringGrid3.Cells[i,5]:=StringGrid1.Cells[i,5];
StringGrid3.Cells[i,6]:=StringGrid1.Cells[i,6];
StringGrid3.Cells[i,7]:=StringGrid1.Cells[i,7];
StringGrid3.Cells[i,8]:=StringGrid1.Cells[i,8];
end;
//из второй таблицы делает первую
for I:=1 to n1 do //меняет первые половины
begin
StringGrid1.Cells[i,1]:=StringGrid3.Cells[i,2];
StringGrid1.Cells[i,2]:=StringGrid3.Cells[i,1];
StringGrid1.Cells[i,3]:=StringGrid3.Cells[i,4];
StringGrid1.Cells[i,4]:=StringGrid3.Cells[i,3];
StringGrid1.Cells[i,5]:=StringGrid3.Cells[i,6];
StringGrid1.Cells[i,6]:=StringGrid3.Cells[i,5];
StringGrid1.Cells[i,7]:=StringGrid3.Cells[i,8];
StringGrid1.Cells[i,8]:=StringGrid3.Cells[i,7];
end;
for I:=n1+1 to kolvo do //дописует вторые половины как были
begin
StringGrid1.Cells[i,1]:=StringGrid3.Cells[i,1];
StringGrid1.Cells[i,2]:=StringGrid3.Cells[i,2];
StringGrid1.Cells[i,3]:=StringGrid3.Cells[i,3];
StringGrid1.Cells[i,4]:=StringGrid3.Cells[i,4];
StringGrid1.Cells[i,5]:=StringGrid3.Cells[i,5];
StringGrid1.Cells[i,6]:=StringGrid3.Cells[i,6];
StringGrid1.Cells[i,7]:=StringGrid3.Cells[i,7];
StringGrid1.Cells[i,8]:=StringGrid3.Cells[i,8];
end;
end;
procedure TForm1.Button11Click(Sender: TObject);
var n2:integer;
begin
for I:=1 to kolvo do //копирует
begin
StringGrid3.Cells[i,1]:=StringGrid1.Cells[i,1];
StringGrid3.Cells[i,2]:=StringGrid1.Cells[i,2];
StringGrid3.Cells[i,3]:=StringGrid1.Cells[i,3];
StringGrid3.Cells[i,4]:=StringGrid1.Cells[i,4];
StringGrid3.Cells[i,5]:=StringGrid1.Cells[i,5];
StringGrid3.Cells[i,6]:=StringGrid1.Cells[i,6];
StringGrid3.Cells[i,7]:=StringGrid1.Cells[i,7];
StringGrid3.Cells[i,8]:=StringGrid1.Cells[i,8];
end;
for I := 1 to 8 do
begin
n2:=random(kolvo-1)+1;
if StringGrid3.Cells[n2,I]='0' then StringGrid3.Cells[n2,I]:='1' else StringGrid3.Cells[n2,I]:='0';//меняет случайный елемент
end;
for I:=1 to kolvo do //копирует
begin
StringGrid1.Cells[i,1]:=StringGrid3.Cells[i,1];
StringGrid1.Cells[i,2]:=StringGrid3.Cells[i,2];
StringGrid1.Cells[i,3]:=StringGrid3.Cells[i,3];
StringGrid1.Cells[i,4]:=StringGrid3.Cells[i,4];
StringGrid1.Cells[i,5]:=StringGrid3.Cells[i,5];
StringGrid1.Cells[i,6]:=StringGrid3.Cells[i,6];
StringGrid1.Cells[i,7]:=StringGrid3.Cells[i,7];
StringGrid1.Cells[i,8]:=StringGrid3.Cells[i,8];
end;
for I := 1 to 8 do
begin
n2:=random(kolvo-1)+1;
if StringGrid1.Cells[n2,I]='0' then StringGrid1.Cells[n2,I]:='1' else StringGrid1.Cells[n2,I]:='0';//меняет случайный елемент
end;
end;
procedure TForm1.Button12Click(Sender: TObject);
var n1:integer;
begin
for I := 1 to 8 do
StringGrid3.Cells[1,I]:=StringGrid1.Cells[kolvo-1,I]; //
for I := 1 to 8 do
for n1 := 1 to kolvo-1 do
StringGrid3.Cells[n1+1,I]:=StringGrid1.Cells[n1,I]
end;
procedure TForm1.Button1Click(Sender: TObject);
begin
j:=1;
Edit1.Text:=''; Edit5.Text:='';
mohl1:='';
for j:=1 to kolt do
begin
mohlt:='';
for z:=1 to kolvo-1 do
begin
mohl2:= inttostr(random(2));
mohlt:=mohlt+mohl2;
mohl:=mohl+mohl2;
if (z=1) and (mohl2='0')
then mohl1:=mohl1+'A'
else if (z=1) and (mohl2='1')
then mohl1:=mohl1+'a';
if (z=2) and (mohl2='0')
then mohl1:=mohl1+'B'
else if (z=2) and (mohl2='1')
then mohl1:=mohl1+'b';
if (z=3) and (mohl2='0')
then mohl1:=mohl1+'C'
else if (z=3) and (mohl2='1')
then mohl1:=mohl1+'c';
if (z=4) and (mohl2='0')
then mohl1:=mohl1+'D'
else if (z=4) and (mohl2='1')
then mohl1:=mohl1+'d';
if (z=5) and (mohl2='0')
then mohl1:=mohl1+'E'
else if (z=5) and (mohl2='1')
then mohl1:=mohl1+'e';
if (z=6) and (mohl2='0')
then mohl1:=mohl1+'F'
else if (z=6) and (mohl2='1')
then mohl1:=mohl1+'f';
if (z=7) and (mohl2='0')
then mohl1:=mohl1+'G'
else if (z=7) and (mohl2='1')
then mohl1:=mohl1+'g';
if (z=8) and (mohl2='0')
then mohl1:=mohl1+'H'
else if (z=8) and (mohl2='1')
then mohl1:=mohl1+'h';
if (z=9) and (mohl2='0')
then mohl1:=mohl1+'I'
else if (z=9) and (mohl2='1')
then mohl1:=mohl1+'i';
if (z=10) and (mohl2='0')
then mohl1:=mohl1+'J'
else if (z=10) and (hohl2='1')
then mohl1:=mohl1+'j';
m3[j]:=mohlt;
end;
if j=1 then
begin
Edit1.Text:=Edit1.Text+mohl;
Edit5.Text:=Edit5.Text+mohl1;
end else
begin
Edit1.Text:=Edit1.Text+' V '+mohl;
Edit5.Text:=Edit5.Text+' V '+mohl1;
end;
mohl:=''; mohl1:='';
end;
end;
procedure TForm1.FormCreate(Sender: TObject);
begin
StringGrid2.Cells[1,0]:='Fэталон';
StringGrid2.Cells[2,0]:='Fтестовая';
StringGrid1.Cells[1,0]:='A';
StringGrid1.Cells[2,0]:='B';
StringGrid1.Cells[3,0]:='C';
StringGrid1.Cells[4,0]:='D';
StringGrid1.Cells[5,0]:='E';
StringGrid1.Cells[6,0]:='F';
StringGrid1.Cells[7,0]:='G';
StringGrid1.Cells[8,0]:='H';
StringGrid1.Cells[9,0]:='I';
StringGrid1.Cells[10,0]:='J';
StringGrid4.Cells[1,0]:='Fэталон';
StringGrid4.Cells[2,0]:='Fтестовая';
StringGrid3.Cells[1,0]:='A';
StringGrid3.Cells[2,0]:='B';
StringGrid3.Cells[3,0]:='C';
StringGrid3.Cells[4,0]:='D';
StringGrid3.Cells[5,0]:='E';
StringGrid3.Cells[6,0]:='F';
StringGrid3.Cells[7,0]:='G';
StringGrid3.Cells[8,0]:='H';
StringGrid3.Cells[9,0]:='I';
StringGrid3.Cells[10,0]:='J';
for i:=1 to a1 do
begin
StringGrid1.Cells[0,i]:='T'+IntToStr(i);
end;
for i:=1 to a2 do
begin
StringGrid2.Cells[0,i]:='T'+IntToStr(i);
end;
for i:=1 to a1 do
begin
StringGrid3.Cells[0,i]:='T'+IntToStr(i);
end;
for i:=1 to a2 do
begin
StringGrid4.Cells[0,i]:='T'+IntToStr(i);
end;
hi:=1;
end;
procedure TForm1.kolld(Sender: TObject);
begin
begin
kold:=StrToInt(Edit6.Text);
end;
end;
procedure TForm1.kollt(Sender: TObject);
begin
kolt:=StrToInt(Edit7.Text);
end;
procedure TForm1.Button5Click(Sender: TObject);
var sg:string;
begin
for i:=1 to kolvo do
begin
StringGrid1.Cells[i,1]:=IntToStr(random(2));
StringGrid1.Cells[i,2]:=IntToStr(random(2));
StringGrid1.Cells[i,3]:=IntToStr(random(2));
StringGrid1.Cells[i,4]:=IntToStr(random(2));
StringGrid1.Cells[i,5]:=IntToStr(random(2));
StringGrid1.Cells[i,6]:=IntToStr(random(2));
StringGrid1.Cells[i,7]:=IntToStr(random(2));
StringGrid1.Cells[i,8]:=IntToStr(random(2));
end;
for j:=1 to 8 do begin
sg:='';
for i := 1 to kolvo-1 do
sg:=sg+StringGrid1.Cells[i,j];
m1[j]:=sg;
end;
hi:=1;
Label2.Caption:=inttostr(hi)+' покление';
for j:=1 to 8 do
for i:=1 to kolvo do
begin
StringGrid3.Cells[i,j]:='';
Label3.Caption:='';
end;
end;
procedure TForm1.Button6Click(Sender: TObject);
var ie,ien,it,itn:integer;
se,se1,st,st1:string;
begin
se1:=Edit2.Text;
st1:=Edit1.Text; ien:=1;itn:=1;
for ie := 1 to kold do
begin m2[ie]:=Copy(se1,ien,kolvo-1);
ien:=ien+5+kolvo-1;
end;
for it := 1 to kolt do
begin m3[it]:=Copy(st1,itn,kolvo-1);
itn:=itn+5+kolvo-1;
end;
end;
procedure TForm1.Button4Click(Sender: TObject);
var flag,flag2,n2:integer;
begin
for k := 1 to 8 do
begin
flag:=0;
for I := 1 to kold do
begin
flag2:=1;
for j := 1 to kolvo - 1 do
if (m2[i][j]<>m1[k][j]) and (m2[i][j]<>'_')
then flag2:=0;
if flag2=1 then flag:=1;
end;
StringGrid2.Cells[1,k]:=inttostr(flag);
end;
for k := 1 to 8 do
begin
flag:=0;
for I := 1 to kolt do
begin
flag2:=1;
for j := 1 to kolvo - 1 do
if (m3[i][j]<>m1[k][j])
then flag2:=0;
if flag2=1 then flag:=1;
end;
StringGrid2.Cells[2,k]:=inttostr(flag);
end;
for k:=1 to 8 do
if StringGrid2.Cells[1,k]<>StringGrid2.Cells[2,k] then n2:=1;
if n2=1 then
ShowMessage('тесты '+inttostr(hi)+'-го поколения показали что функции не еквивалентны')
else
ShowMessage('тесты '+inttostr(hi)+'-го поколения показали что функции еквивалентны');
end;
procedure TForm1.Button2Click(Sender: TObject);
var n1,n2: integer;
sg:string;
begin
for I := 1 to 8 do begin
StringGrid2.Cells[1,i]:='';
StringGrid2.Cells[2,i]:='';
StringGrid4.Cells[1,i]:='';
StringGrid4.Cells[2,i]:='';
end;
i:=0;
n1:=kolvo div 2; //кросинговер
for i:=0 to n1 do //меняет первые половины
begin
StringGrid3.Cells[i,1]:=StringGrid1.Cells[i,1];
StringGrid3.Cells[i,7]:=StringGrid1.Cells[i,7];
StringGrid3.Cells[i,4]:=StringGrid1.Cells[i,4];
StringGrid3.Cells[i,5]:=StringGrid1.Cells[i,5];
for i:=n1 to kolvo do //дописует вторые половины как были
begin
StringGrid3.Cells[i,1]:=StringGrid1.Cells[i,7];
StringGrid3.Cells[i,7]:=StringGrid1.Cells[i,1];
StringGrid3.Cells[i,4]:=StringGrid1.Cells[i,5];
StringGrid3.Cells[i,5]:=StringGrid1.Cells[i,4];
end;
for i:=0 to kolvo do //мутация
begin //копирует
StringGrid3.Cells[i,2]:=StringGrid1.Cells[i,2];
StringGrid3.Cells[i,6]:=StringGrid1.Cells[i,6];
end;
n1:=random(kolvo-1)+1; //меняет случайный елемент
n2:=random(kolvo-1)+1;
if StringGrid3.Cells[n1,2]='0' then StringGrid3.Cells[n1,2]:='1' else StringGrid3.Cells[n1,2]:='0';
if StringGrid3.Cells[n2,6]='0' then StringGrid3.Cells[n2,6]:='1' else StringGrid3.Cells[n2,6]:='0';
StringGrid3.Cells[1,8]:=StringGrid1.Cells[kolvo,8]; //сдвиг
StringGrid3.Cells[1,3]:=StringGrid1.Cells[kolvo,3];
StringGrid3.Cells[0,3]:=StringGrid1.Cells[0,3];
for i:=2 to kolvo do
begin
StringGrid3.Cells[i,8]:=StringGrid1.Cells[i-1,8];
StringGrid3.Cells[i,3]:=StringGrid1.Cells[i-1,3];
end;
for j:=1 to 8 do begin
sg:='';
for i := 1 to kolvo-1 do
sg:=sg+StringGrid3.Cells[i,j];
m1[j]:=sg;
end;
end;
hi:=hi+1;
Label2.Caption:=inttostr(hi)+' поколение';
n1:=kolvo div 2; //кросинговер
for i:=0 to n1 do //меняет первые половины
begin
StringGrid1.Cells[i,1]:=StringGrid3.Cells[i,1];
StringGrid1.Cells[i,7]:=StringGrid3.Cells[i,7];
StringGrid1.Cells[i,4]:=StringGrid3.Cells[i,4];
StringGrid1.Cells[i,5]:=StringGrid3.Cells[i,5];
for i:=n1 to kolvo do //дописует вторые половины как были
begin
StringGrid1.Cells[i,1]:=StringGrid3.Cells[i,7];
StringGrid1.Cells[i,7]:=StringGrid3.Cells[i,1];
StringGrid1.Cells[i,4]:=StringGrid3.Cells[i,5];
StringGrid1.Cells[i,5]:=StringGrid3.Cells[i,4];
end;
for i:=0 to kolvo do //мутация
begin //копирует
StringGrid1.Cells[i,2]:=StringGrid3.Cells[i,2];
StringGrid1.Cells[i,6]:=StringGrid3.Cells[i,6];
end;
n1:=random(kolvo-1)+1; //меняет случайный елемент
n2:=random(kolvo-1)+1;
if StringGrid1.Cells[n1,2]='0' then StringGrid1.Cells[n1,2]:='1' else StringGrid3.Cells[n1,2]:='0';
if StringGrid1.Cells[n2,6]='0' then StringGrid1.Cells[n2,6]:='1' else StringGrid3.Cells[n2,6]:='0';
StringGrid1.Cells[1,8]:=StringGrid3.Cells[kolvo,8]; //сдвиг
StringGrid1.Cells[1,3]:=StringGrid3.Cells[kolvo,3];
StringGrid1.Cells[0,3]:=StringGrid3.Cells[0,3];
for i:=2 to kolvo do
begin
StringGrid1.Cells[i,8]:=StringGrid3.Cells[i-1,8];
StringGrid1.Cells[i,3]:=StringGrid3.Cells[i-1,3];
end;
end;
hi:=hi+1;
Label3.Caption:=inttostr(hi)+' покление';
end;
procedure TForm1.Button3Click(Sender: TObject);
begin
Button3.Caption:=m3[strtoint(Edit6.text)];
end;
procedure TForm1.Button7Click(Sender: TObject);
begin
j:=1;
Edit2.Text:=''; Edit3.Text:='';
hohl1:='';
for j:=1 to kold do
begin
hohlt:='';
for z:=1 to kolvo-1 do
begin
hohl2:= inttostr(random(3));
if hohl2='2' then hohl2:='_';
hohl:=hohl+hohl2; hohlt:=hohlt+hohl2;
if (z=1) and (hohl2='0')
then hohl1:=hohl1+'A'
else if (z=1) and (hohl2='1')
then hohl1:=hohl1+'a';
if (z=2) and (hohl2='0')
then hohl1:=hohl1+'B'
else if (z=2) and (hohl2='1')
then hohl1:=hohl1+'b';
if (z=3) and (hohl2='0')
then hohl1:=hohl1+'C'
else if (z=3) and (hohl2='1')
then hohl1:=hohl1+'c';
if (z=4) and (hohl2='0')
then hohl1:=hohl1+'D'
else if (z=4) and (hohl2='1')
then hohl1:=hohl1+'d';
if (z=5) and (hohl2='0')
then hohl1:=hohl1+'E'
else if (z=5) and (hohl2='1')
then hohl1:=hohl1+'e';
if (z=6) and (hohl2='0')
then hohl1:=hohl1+'F'
else if (z=6) and (hohl2='1')
then hohl1:=hohl1+'f';
if (z=7) and (hohl2='0')
then hohl1:=hohl1+'G'
else if (z=7) and (hohl2='1')
then hohl1:=hohl1+'g';
if (z=8) and (hohl2='0')
then hohl1:=hohl1+'H'
else if (z=8) and (hohl2='1')
then hohl1:=hohl1+'h';
if (z=9) and (hohl2='0')
then hohl1:=hohl1+'I'
else if (z=9) and (hohl2='1')
then hohl1:=hohl1+'i';
if (z=10) and (hohl2='0')
then hohl1:=hohl1+'J'
else if (z=10) and (hohl2='1')
then hohl1:=hohl1+'j';
end;
for zz := 1 to kolvo do
if hohl[zz]='2'
then hohl[zz]:='_';
m2[j]:=hohlt;
if j=1 then
begin
Edit2.Text:=Edit2.Text+hohl;
Edit3.Text:=Edit3.Text+hohl1;
end
else
begin
Edit2.Text:=Edit2.Text+' V '+hohl;
Edit3.Text:=Edit3.Text+' V '+hohl1;
end;
hohl:=''; hohl1:='';
end;
end;
procedure TForm1.Edit4Change(Sender: TObject);
begin
kolvo:=StrToInt(Edit4.Text)+1;
StringGrid1.colCount:=kolvo;
StringGrid3.colCount:=kolvo;
end;
procedure TForm1.Button8Click(Sender: TObject);
var flag,flag2,n2:integer;
begin
for k := 1 to 8 do
begin
flag:=0;
for I := 1 to kold do
begin
flag2:=1;
for j := 1 to kolvo - 1 do
if (m2[i][j]<>m1[k][j]) and (m2[i][j]<>'_')
then flag2:=0;
if flag2=1 then flag:=1;
end;
StringGrid4.Cells[1,k]:=inttostr(flag);
end;
for k := 1 to 8 do
begin
flag:=0;
for I := 1 to kolt do
begin
flag2:=1;
for j := 1 to kolvo - 1 do
if (m3[i][j]<>m1[k][j])
then flag2:=0;
if flag2=1 then flag:=1;
end;
StringGrid4.Cells[2,k]:=inttostr(flag);
end;
for k:=1 to 8 do
if StringGrid4.Cells[1,k]<>StringGrid4.Cells[2,k] then n2:=1;
if n2=1 then
ShowMessage('тесты '+inttostr(hi)+'-го поколения показали что функции не еквивалентны')
else
ShowMessage('тесты '+inttostr(hi)+'-го поколения показали что функции еквивалентны');
end;
procedure TForm1.Button9Click(Sender: TObject);
var schet:integer;
begin
avto;
for schet:=1 to 4 do
begin
avto
end;
end;
procedure TForm1.avto;
var n1,n2: integer;
sg:string;
begin
for I := 1 to 8 do begin
StringGrid2.Cells[1,i]:='';
StringGrid2.Cells[2,i]:='';
StringGrid4.Cells[1,i]:='';
StringGrid4.Cells[2,i]:='';
end;
i:=0;
n1:=kolvo div 2; //кросинговер
for i:=0 to n1 do //меняет первые половины
begin
StringGrid3.Cells[i,1]:=StringGrid1.Cells[i,1];
StringGrid3.Cells[i,7]:=StringGrid1.Cells[i,7];
StringGrid3.Cells[i,4]:=StringGrid1.Cells[i,4];
StringGrid3.Cells[i,5]:=StringGrid1.Cells[i,5];
for i:=n1 to kolvo do //дописует вторые половины как были
begin
StringGrid3.Cells[i,1]:=StringGrid1.Cells[i,7];
StringGrid3.Cells[i,7]:=StringGrid1.Cells[i,1];
StringGrid3.Cells[i,4]:=StringGrid1.Cells[i,5];
StringGrid3.Cells[i,5]:=StringGrid1.Cells[i,4];
end;
for i:=0 to kolvo do //мутация
begin //копирует
StringGrid3.Cells[i,2]:=StringGrid1.Cells[i,2];
StringGrid3.Cells[i,6]:=StringGrid1.Cells[i,6];
end;
n1:=random(kolvo-1)+1; //меняет случайный елемент
n2:=random(kolvo-1)+1;
if StringGrid3.Cells[n1,2]='0' then StringGrid3.Cells[n1,2]:='1' else StringGrid3.Cells[n1,2]:='0';
if StringGrid3.Cells[n2,6]='0' then StringGrid3.Cells[n2,6]:='1' else StringGrid3.Cells[n2,6]:='0';
StringGrid3.Cells[1,8]:=StringGrid1.Cells[kolvo,8]; //сдвиг
StringGrid3.Cells[1,3]:=StringGrid1.Cells[kolvo,3];
StringGrid3.Cells[0,3]:=StringGrid1.Cells[0,3];
StringGrid3.Cells[0,3]:=StringGrid1.Cells[0,3];
for i:=2 to kolvo do
begin
StringGrid3.Cells[i,8]:=StringGrid1.Cells[i-1,8];
StringGrid3.Cells[i,3]:=StringGrid1.Cells[i-1,3];
end;
for j:=1 to 8 do begin
sg:='';
for i := 1 to kolvo-1 do
sg:=sg+StringGrid3.Cells[i,j];
m1[j]:=sg;
end;
end;
hi:=hi+1;
Label2.Caption:=inttostr(hi)+' поколение';
n1:=kolvo div 2; //кросинговер
for i:=0 to n1 do //меняет первые половины
begin
StringGrid1.Cells[i,1]:=StringGrid3.Cells[i,1];
StringGrid1.Cells[i,7]:=StringGrid3.Cells[i,7];
StringGrid1.Cells[i,4]:=StringGrid3.Cells[i,4];
StringGrid1.Cells[i,5]:=StringGrid3.Cells[i,5];
for i:=n1 to kolvo do //дописует вторые половины как были
begin
StringGrid1.Cells[i,1]:=StringGrid3.Cells[i,7];
StringGrid1.Cells[i,7]:=StringGrid3.Cells[i,1];
StringGrid1.Cells[i,4]:=StringGrid3.Cells[i,5];
StringGrid1.Cells[i,5]:=StringGrid3.Cells[i,4];
end;
for i:=0 to kolvo do //мутация
begin //копирует
StringGrid1.Cells[i,2]:=StringGrid3.Cells[i,2];
StringGrid1.Cells[i,6]:=StringGrid3.Cells[i,6];
end;
n1:=random(kolvo-1)+1; //меняет случайный елемент
n2:=random(kolvo-1)+1;
if StringGrid1.Cells[n1,2]='0' then StringGrid1.Cells[n1,2]:='1' else StringGrid3.Cells[n1,2]:='0';
if StringGrid1.Cells[n2,6]='0' then StringGrid1.Cells[n2,6]:='1' else StringGrid3.Cells[n2,6]:='0';
StringGrid1.Cells[1,8]:=StringGrid3.Cells[kolvo,8]; //сдвиг
StringGrid1.Cells[1,3]:=StringGrid3.Cells[kolvo,3];
StringGrid1.Cells[0,3]:=StringGrid3.Cells[0,3];
StringGrid1.Cells[0,3]:=StringGrid3.Cells[0,3];
for i:=2 to kolvo do
begin
StringGrid1.Cells[i,8]:=StringGrid3.Cells[i-1,8];
StringGrid1.Cells[i,3]:=StringGrid3.Cells[i-1,3];
end;
end;
hi:=hi+1;
Label3.Caption:=inttostr(hi)+' покление';
end;
end.
3.3. Тестовий приклад.
Візьмемо для приклада дві еквівалентні булеві функції
Еталона функція
_110_ V _0110 V 11_10
Тестова функція
10110 V 01100 V 11010 V 01101 V 11100 V 11101 V 00110 V 11110
Спочатку виставимо потрібну кількість елементарних кон'юнкцій в еталонній та тестовій функції, та кількість змінних (мал. 6).
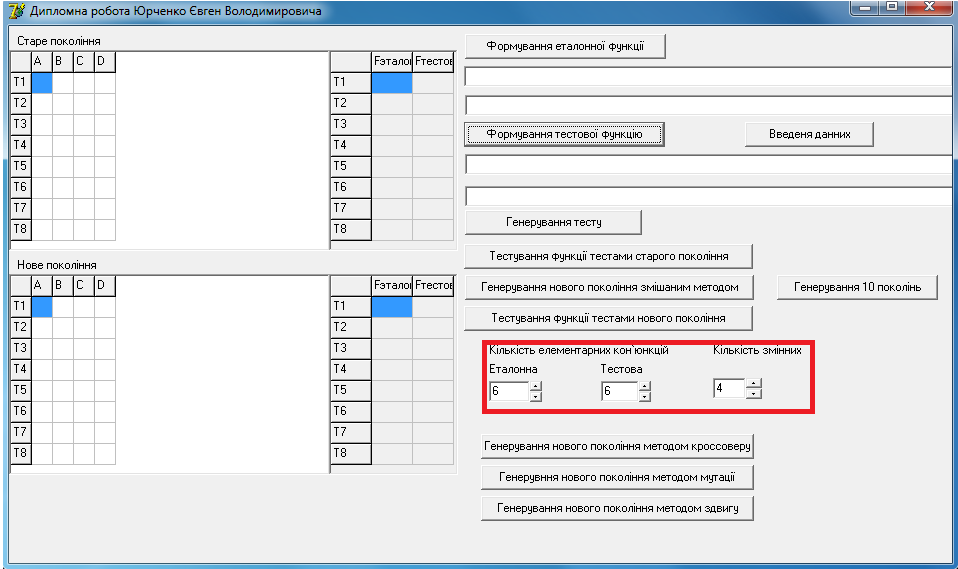
Мал. 6. Вибір кількості змінних та елементарних кон'юнкцій.
Вводимо тестові приклади до потрібних вікон з еталонною та тестовою функцією. Та натискаємо кнопку «Введення данних» (мал. 7).
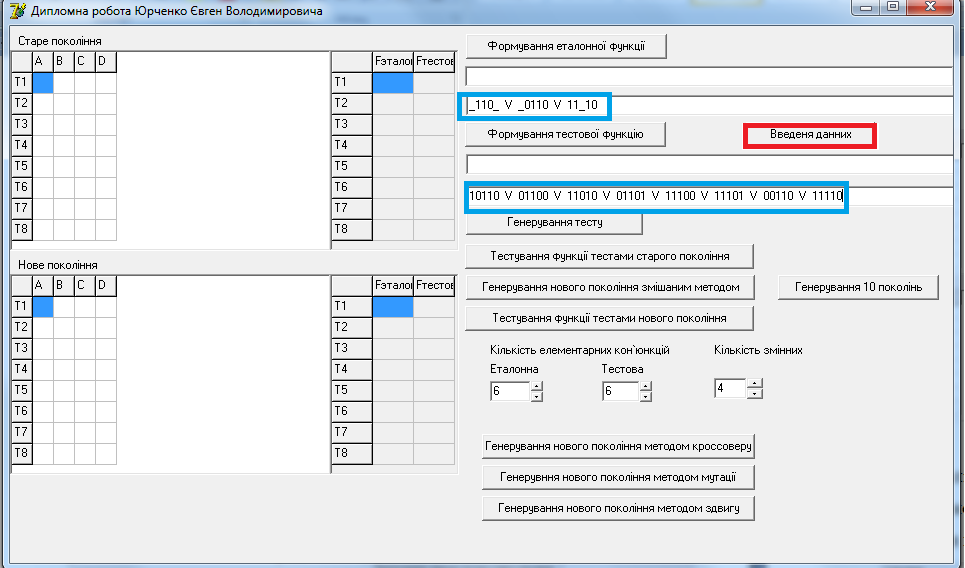
Мал. 7. Ведення еталонної та тестової функцій.
Далі генеруємо тестові набори якими будемо перевіряти функції, та натискаємо кнопку «Тестування функції тестами старого покоління». З'явиться повідомлення, еквівалентні функції чи ні (мал. 8).
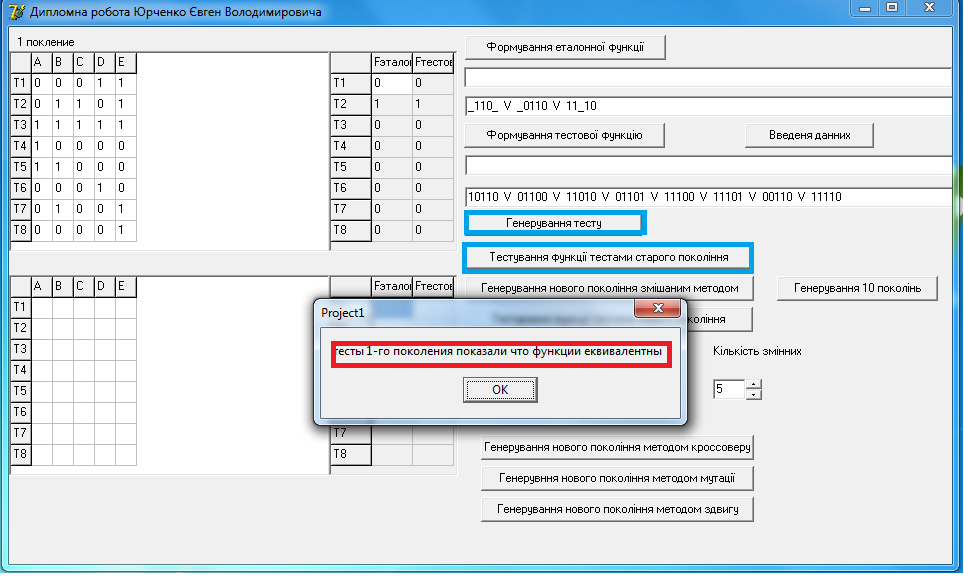
Мал. 8. Перевірка функцій тестами початкової генерації
Якщо на цих тестах значення функцій будуть попарно однаковими, то сформуємо тести нового покоління за допомогою генетичних способів. Для цього натискаємо кнопки «Генерувати 10-ь поколінь» та «Тестування функції тестами нового покоління». У повідомленні буде написано про еквівалентність функцій. (мал. 9)
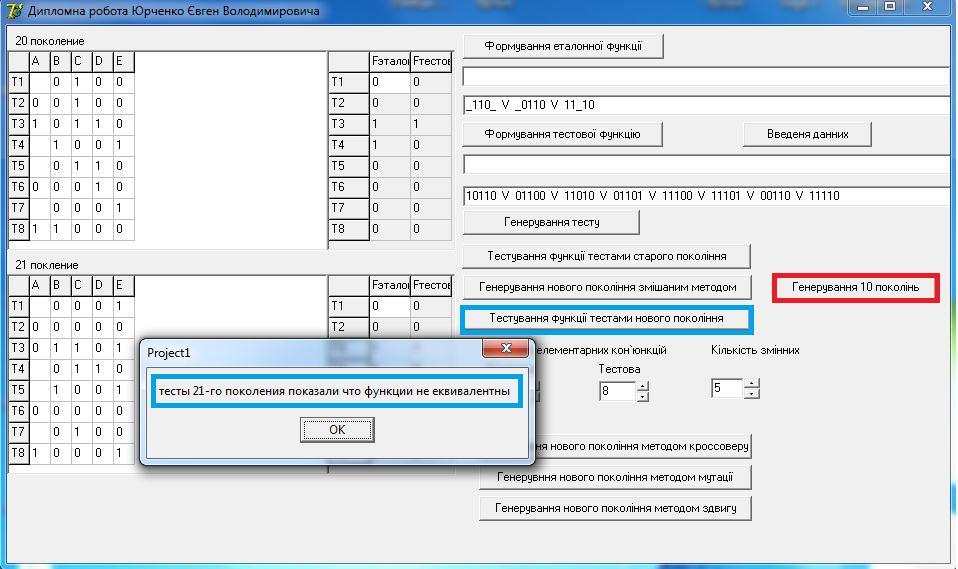
Мал. 9 Повідомлення про еквівалентність функцій.
Висновки.
В роботі проведено аналіз літератури щодо проблем, пов`язаних з побудовою контрольних тестів булевих функцій. Розглянуто історію виникнення генетичних алгоритмів та їх структура. Розроблено та програмно реалізовано алгоритм побудови ефективних контрольних тестів булевих функцій із використанням генетичних операцій.
Список використаних джерел
-
Андерсен Дж. Дискретная математика и комбинаторика. - Москва - С.Петербург - Киев.: Издат. дом "Вильямс", 2003 - 958с.
-
Афанасьев К.Е. и др. Многопроцессорные вычислительные системы и параллельное программирование. - Кемерово: Кузбассвузиздат, 2003.
-
Батищев Д.И. Генетические алгоритмы решения экстремальных задач: учеб. пособие. - Воронеж: ВГТУ, 1995. - 69 с.
-
М.Ф.Бондаренко, Н.В.Білоус, А.Г.Руткас. Комп'ютерна дискретна математика: Підручник. - Харків.: "Компанія СМІТ", 2004. - 480с.
-
А.И.Белоусов, С.Б.Ткачев. Дискретная математика. - Москва.: Изд-во МГТУ им. Баумана, 2001. - 744с.
-
Гладков Л.А. Генетические алгоритмы / Л.А. Гладков, В.В. Курейчик, В.М.Курейчик. -М : Физматлит, 2006. - 402 с.
-
Гофман В.Э., Хомоненко А.Д. Delphi. Быстрый старт - СПб.: БХВ - Санкт-Петербург, 2003. - 288с.
-
Емельянов В.В.Теория и практика эволюционного моделирования/ В.В. Емельянов, В.В. Курейчик, В.М. Курейчик. -М : Физматлит, 2003 г.- 431 с.
-
Ю.В.Капітонова та ін. Основи дискретної математики. - Київ.: Наукова думка, 2002. - 578с.
-
Коваценко С.В. Синтез легкотестируемых схем в базисе Жегалкина для инверсных несправностей // Вестник Московского университета. Серия 15. Вычислительная математика и кибернетика. - 2000. - №2. - С.45 - 47.
-
Кузюрин Н.Н., Фрумкин М.А. Параллельные вычисления: теория и алгоритмы // Программирование. - Москва.: Наука ,1991. - с. 3-19.
-
Немнюгин С.А., Стесик О.Л. Параллельное программирование для многопроцессорных систем.- СПБ. БХВ Петербург, 2002.-400 с.
-
Ф.А.Новиков. Дискретная математика для программистов. - С.Петербург.: Питер, 2002. - 304с.
-
Носков В.Н. Метод синтеза удобных для контроля комбинационных схем // Дискретная математика. - 1993. - Т.5, вып. 4. - С. 3 - 25.
-
Т.В. Панченко. Генетические алгоритмы: учебно-методическое пособие. - Астрахань: Издательский дом «Астраханский университет», 2007. - 88с.
-
Редькин Н.П. О схемах, допускающих короткие тесты // Вестник Московского университета. Серия 1. Математика. Механика. - 1988. - N 2. - С. 17-21
-
Редькин Н.П. О полных проверяющих тестах для схемы из функциональных элементов // Математические вопросы кибернетики. - Вып. 2. - 1989. - С. 198 - 222.
-
Редькин Н.П. О проверяющих тестах для схем при константних неисправностях на входах элементов // Вестник Московского университета. Серия 1. Математика. Механика. - 1997. - №1. - С. 12-18.
-
Рутковская Д. Нейронные сети, генетические алгоритмы и нечеткие системи / Д. Рутковская, М. Пилинский, Л. Рутковский. - М : Горячая линия - Телеком, 2006. - 452 с.
-
Фаронов В. Delphi 6. - СПб.: Питер, 2002. - 512с.
-
Хахулин В.Г. О проверяющих тестах для счетчика честности // Дискретная математика. - 1995. - Т.7, вып. 4. - С. 51 - 59.
-
Яблонский С. В. Введение в дискретную математику.- М.: Наука, 1979.
-
Яблонский С.В. Некоторые вопросы надежности и контроля управляющих систем // Математические вопросы кибернетики. - 1988. - № 1. - С.5-25