- Преподавателю
- Информатика
- Работа по теме Методы сортировки массивов
Работа по теме Методы сортировки массивов
| Раздел | Информатика |
| Класс | 11 класс |
| Тип | Другие методич. материалы |
| Автор | Капитунова С.Г. |
| Дата | 07.07.2015 |
| Формат | doc |
| Изображения | Есть |

Тема : «Методы сортировки массивов»
Автор работы - Капитунова Светлана Гордеевна
Содержание
Содержание 1
Введение 2
1.Теоретические основы структуры данных в Pascal. Массив 3
1.1.Описание структурного типа в Pascal «Массив» 3
1.2. Двухмерные и многомерные массивы 7
1.3.Основные действия с массивами в Паскале 10
2.Сортировка массива в Паскале. Методы сортировки. 13
2.1.Методы внутренней сортировки 14
2.1.1.Сортировка включением 15
2.1.2.Обменная сортировка или «Метод пузырька» 17
2.1.3.Сортировка выбором 21
2.1.4.Сортировка разделением (Quicksort) или быстрая сортировка 22
2.1.5.Сортировка с помощью дерева (Heapsort) 26
2.1.6.Сортировка со слиянием 27
2.2. Методы внешней сортировки 30
2.2.1. Прямое слияние. Алгоритм Боуза - Нельсона 31
2.2.2.Естественное слияние 35
2.2.3.Сбалансированное многопутевое слияние 38
2.2.4.Многофазная сортировка 38
3.Программа 41
Заключение 47
Список используемых источников 49
Введение
Необходимость отсортировать какие-либо величины возникает в программировании очень часто. К примеру, входные данные подаются «вперемешку», а вашей программе удобнее обрабатывать упорядоченную последовательность. Существуют ситуации, когда предварительная сортировка данных позволяет сократить содержательную часть алгоритма в разы, а время его работы - в десятки раз.
В данной работе поставлена цель: изучить методы сортировок в Paskal. Для этого необходимо решить следующие задачи:
-
Рассмотреть теоретические основы структуры данных в Pascal.
-
Рассмотреть методы внутренней и внешней сортировки.
-
Составить программу, используя полученные теоретические данные.
Работа ведется на основании трудов отечественных и зарубежных ученых, современных электронных учебников. В курсовой работе используются схемы и таблицы для более наглядного использования материала.
-
Теоретические основы структуры данных в Pascal. Массив
-
Описание структурного типа в Pascal «Массив»
-
Язык Паскаль относится к парадигме структурного программирования. Это значит, что понятие «структура» входит в программу не только на уровне общего ее построения, но и предусматривает структурирование самой логики и оперируемых данных. Прежде всего, данный принцип нашел свое применение в типизации языка, т.е. наделении его строгой системой предопределенных типов, комбинируя которые программист мог создавать свои собственные типы, причем уже не только простые (атомарные), но и представляющие собой сложные конструкции - структуры данных.
Это было очень важно, поскольку моделирование всевозможных реальных процессов становилось одной из основных областей применения ЭВМ. Моделирование приводило к абстракции, т.е. к упрощенному (или обобщенному) представлению объектов, их свойств и отношений в зависимости от поставленной задачи. Некоторые такие абстрактные объекты из-за своих полезных качеств стали необычайно «популярны». Они получили точную спецификацию и с тех пор стали называться абстрактными типами данных (или АТД). Однако абстракция на то и абстракция, чтобы абстрагироваться от многих несущественных факторов, в том числе и от того, как этот абстрактный объект представить в ЭВМ. Этим и занялись языки программирования, которые, по сути, являются неким переходником между идеями человека и возможностями машины. И вот здесь как раз и пригодились вышеупомянутые структуры данных. [1, стр. - 234 стр.]
Структурные типы в Паскале:
-
Массив - это одно- или многомерная таблица данных одного типа. Каждая ячейка таблицы имеет свой индекс (в одномерном случае) или набор индексов (в многомерном).
-
Запись - связанная структура, состоящая из нескольких элементов (полей) разных (можно и одинаковых) типов.
-
Файл - динамическая структура данных, размер которой может меняться в процессе выполнения над ним каких-либо действий (он может быть равен нулю, что соответствует пустому файлу).
-
Динамические структуры. Хотя динамика и не является отличительной чертой языка Паскаль, все же существует возможность создавать динамические объекты и оперировать с ними. Динамический объект представляет собой область памяти без идентификатора.
-
Ключом называется поле, содержащее величину, используемую в правилах упорядочивания файла.
В данной работе будет рассматриваться такой тип структурных данных, как «Массив». Как уже говорилось, массивы - это совокупности однотипных элементов. Характеризуются они следующим:
-
каждый компонент массива может быть явно обозначен и к нему имеется прямой доступ;
-
число компонент массива определяется при его описании и в дальнейшем не меняется.
Для обозначения компонент массива используется имя переменной-массива и так называемые индексы, которые обычно указывают желаемый элемент. Тип индекса может быть только порядковым (кроме longint). Чаще всего используется интервальный тип (диапазон).
Описание типа массива задается следующим образом:
type
имя типа = array[ список индексов ] of тип
Здесь: имя типа - правильный идентификатор; список индексов - список одного или нескольких индексных типов, разделенных запятыми; тип - любой тип данных.
Вводить и выводить массивы можно только поэлементно.
Пример 1. Ввод и вывод одномерного массива. (рис. 1)
Program primer1;
const n = 5;
type mas = array[1..n] of integer;
var a: mas;
i: byte;
begin
writeln('введите элементы массива');
for i:=1 to n do readln(a[i]);
writeln('вывод элементов массива:');
for i:=1 to n do writeln(a[i]:5);
end.
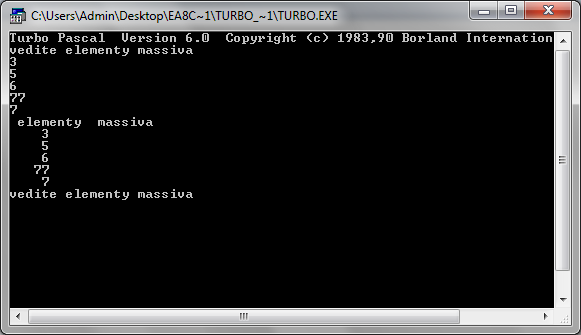
Рисунок 1. Результат программы по созданию одномерного массива
Определить переменную как массив можно и непосредственно при ее описании, без предварительного описания типа массива, например:
var a,b,c: array[1..10] of integer;
Если массивы a и b описаны как:
var
a = array[1..5] of integer;
b = array[1..5] of integer;
То переменные a и b считаются разных типов. Для обеспечения совместимости применяйте описание переменных через предварительное описание типа. Если типы массивов идентичны, то в программе один массив может быть присвоен другому. В этом случае значения всех переменных одного массива будет присвоены соответствующим элементам второго массива.
Вместе с тем, над массивами не определены операции отношения. Сравнивать два массива можно только поэлементно. Так как тип, идущий за ключевым словом of в описании массива, - любой тип Турбо Паскаль, то он может быть и другим массивом. Например:
type
mas = array[1..5] of array[1..10] of integer;
Такую запись можно заменить более компактной:
type
mas = array[1..5, 1..10] of integer;
Таким образом возникает понятие многомерного массива. Глубина вложенности массивов произвольная, поэтому количество элементов в списке индексных типов (размерность массива) не ограничена, однако не может быть более 65520 байт. [2 - стр. 543]
-
Двухмерные и многомерные массивы
Многомерный массив (массив массивов) предоставляет в распоряжение программиста более эффективные средства для хранения информации, требующей дополнительного структурирования. Создать многомерный массив несложно - просто добавьте дополнительную пару квадратных скобок, чтобы вывести массив в новое измерение:
$chessboard [1] [4] = "King"; // Двухмерный массив
$capitals["USA"] ["Ohio"] = "Columbus": // Двухмерный массив
$streets["USA"]["Ohio"]["Columbus"] = "Harrison"; // Трехмерный массив
Пример 2. В качестве примера рассмотрим массив, в котором хранится информация о десертах и особенностях их приготовления. Обойтись одномерным массивом было бы довольно трудно, но двухмерный массив подходит как нельзя лучше:
$desserts = аrrау["Fruit Cup" => array["calories" => "low",
"served" => "cold",
"preparation" => "10 minutes"],
"Brownies" => array["calories" => "high",
"served" => "piping hot",
"preparation" => "45 minutes"]];
Присваивание значений элементам многомерных массивов выполняется так же, как и в одномерных массивах:
$desserts["Cake"]["calories"] = "too many";
// Присваивает свойству "calories" объекта "Cake" значение "too many"
Хотя в многомерных массивах появляются новые уровни логической организации данных, многомерные массивы создаются практически так же, как и одномерные. Впрочем, ссылки на многомерные массивы в строках требуют особого внимания; этой теме посвящен следующий раздел. [1, стр. - 259]
Работа с многомерными массивами почти всегда связана с организацией вложенных циклов. Так, чтобы заполнить двумерный массив (матрицу) случайными числами, используют конструкцию вида:
for i:=1 to m do
for j:=1 to n do a[i,j]:=random(10);
Для "красивого" вывода матрицы на экран используйте такой цикл:
for i:=1 to m do begin
for j:=1 to n do write(a[i,j]:5);
writeln;
end;
После создания массива к его элементам можно обращаться по соответствующим ключам:
$desserts["Fruit Cup"]["preparation"] // возвращает "10 minutes" $desserts["Brownies"]["calories"] // возвращает "high"
-
Основные действия с массивами в Паскале
Как известно, определение типа данных означает ограничение области допустимых значений, внутреннее представление в ЭВМ, а также набор допустимых операций над данными этого типа. Уже был определен тип данных как массив Паскаля. Какие же операции определены над этим типом данных?
Как известно, определение типа данных означает ограничение области допустимых значений, внутреннее представление в ЭВМ, а также набор допустимых операций над данными этого типа. Мы определили тип данных как массив Паскаля. Какие же операции определены над этим типом данных? Единственное действие, которое можно выполнять над массивами целиком, причем только при условии, что массивы однотипны, - это присваивание. Если в программе описаны две переменные одного типа, как, например:
Var a , b : array [1..10] of real ;,то можно переменной a присвоить значение переменной b ( a := b ). При этом каждому элементу массива a будет присвоено соответствующее значение из массива b. Все остальные действия над массивами Паскаля производятся поэлементно.
Ввод массива Паскаля. Для того чтобы ввести значения элементов массива, необходимо последовательно изменять значение индекса, начиная с первого до последнего, и вводить соответствующий элемент. Для реализации этих действий удобно использовать цикл с заданным числом повторений, т.е. простой арифметический цикл, где параметром цикла будет выступать переменная - индекс массива Паскаля. Значения элементов могут быть введены с клавиатуры или определены с помощью оператора присваивания. [2, стр. - 560]
Пример 3.
Пример фрагмента программы ввода массива Паскаля
Var A : array [1..10] of integer ;
I : byte ; {переменная I вводится как индекс массива}
Begin
For i:=1 to 10 do Readln (a[i]); { ввод i- го элемента производится с клавиатуры }
Рассмотрим теперь случай, когда массив Паскаля заполняется автоматически случайными числами, для этого будем использовать функцию random(N). Пример фрагмента программы заполнения массива Паскаля случайными числами:
Var A: array [1..10] of integer;
I : byte ; {переменная I вводится как индекс массива}
Begin
For i :=1 to 10 do A [ i ]:= random (10); { i -му элементу массива присваивается «случайное» целое число в диапазоне от 0 до 10}
Вывод массива Паскаля. Вывод массива в Паскале осуществляется также поэлементно, в цикле, где параметром выступает индекс массива, принимая последовательно все значения от первого до последнего.
Пример фрагмента программы вывода массива Паскаля:
Var A: array [1..10] of integer;
I : byte ; {переменная I вводится как индекс массива}
Begin
For i :=1 to 10 do Write ( a [ i ],' '); {вывод массива осуществляется в строку, после каждого элемента печатается пробел}
Вывод можно осуществить и в столбик с указанием соответствующего индекса. Но в таком случае нужно учитывать, что при большой размерности массива все элементы могут не поместиться на экране и будет происходить скроллинг, т.е. при заполнении всех строк экрана будет печататься очередной элемент, а верхний смещаться за пределы экрана.
Пример программы вывода массива Паскаля в столбик:
Var A: array [1..10] of integer;
I : byte ; {переменная I вводится как индекс массива}
Begin
For i:=1 to 10 do Writeln ('a[', i,']=', a[i]); { вывод элементов массива в столбик }
На экране мы увидим, к примеру, следующие значения:
a[1]=2
a[2]=4
a[3]=1 и т.д.
-
Сортировка массива в Паскале. Методы сортировки.
Для решения многих задач удобно сначала упорядочить данные по определенному признаку, так можно ускорить поиск некоторого объекта. Например, в преферансе игроки раскладывают карты по мастям и по значению. Так легче определить, каких карт не хватает. Или возьмем любой энциклопедический словарь - статьи в нем упорядочены в алфавитном порядке.
Перегруппирование заданного множества объектов в определенном порядке называют сортировкой.
Почему сортировке уделяется большое внимание? Вы это поймете, прочитав цитаты двух великих людей:
-
"Даже если бы сортировка была почти бесполезна, нашлась бы масса причин заняться ею! Изобретательные методы сортировки говорят о том, что она и сама по себе интересна как объект исследования." [Д. Кнут]
-
"Создается впечатление, что можно построить целый курс программирования, выбирая примеры только из задач сортировки." [Н. Вирт]
Отличительной особенностью сортировки является то обстоятельство, что эффективность алгоритмов, реализующих ее, прямо пропорциональна сложности понимания этого алгоритма. Другими словами, чем легче для понимания метод сортировки массива, тем ниже его эффективность.
Сортировкой или упорядочением массива называется расположение его элементов по возрастанию (или убыванию). Если не все элементы различны, то надо говорить о неубывающем (или невозрастающем) порядке. [3, стр. - 260]
Вообще говоря, это большая и сложная тема, в которой известно много различных алгоритмов. Критерии оценки эффективности этих алгоритмов могут включать следующие параметры:
-
количество шагов алгоритма, необходимых для упорядочения;
-
количество сравнений элементов;
-
количество перестановок, выполняемых при сортировке.
Сегодня существует множество методов сортировки, но для понимания сути сортировки рассмотрим некоторые из них. Методы упорядочения подразделяются на внутренние (обрабатывающие массивы) и внешние (занимающиеся только файлами). Для внутренней и внешней сортировки требуются существенно разные методы.
-
Методы внутренней сортировки
Как уже указывалось, задачей сортировки является преобразование исходной последовательности в последовательность, содержащую те же записи, но в порядке возрастания (или убывания) значений ключа. Метод сортировки называется устойчивым, если при его применении не изменяется относительное положение записей с равными значениями ключа.
Естественным условием, предъявляемым к любому методу внутренней сортировки является то, что эти методы не должны требовать дополнительной памяти: все перестановки с целью упорядочения элементов массива должны производиться в пределах того же массива. Мерой эффективности алгоритма внутренней сортировки являются число требуемых сравнений значений ключа (C) и число перестановок элементов (M). Итак, рассмотрим некоторые из методов внутренней сортировки.
-
Сортировка включением
Идея данного метода состоит в том, что каждый раз, имея уже упорядоченный массив из K элементов, мы добавляем еще один элемент, включая его в массив таким образом, чтобы упорядоченность не нарушилась. Сортировка может производиться одновременно со вводом массива.
В начале сортировки упорядоченная часть массива содержит только один элемент, который вводится отдельно или, если массив уже имеется, считается единственным, стоящим на нужном месте. Различные методы поиска места для включаемого элемента приводят к различным модификациям сортировки включением.
Пример 4. Сортировка по возрастанию массива A из N целых чисел включением с линейным поиском.(рис. 2)
program Sort_Include1;
var A:array[1..100] of integer;
N,i,k,x : integer;
begin
write('количество элементов массива ');
read(N);
read(A[1]); {for i:=1 to n do read(A[i]);}
{k - количество элементов в упорядоченной части массива}
for k:=1 to n-1 do
begin
read(x); {x:=A[k+1];}
i:=k;
while (i>0)and(A[i]>x) do
begin
A[i+1]:=A[i];
i:=i-1;
end;
A[i+1]:=x;
end;
for i:=1 to n do write(A[i],' '); {упорядоченный массив}
end.

Рисунок 2. Результат программы по выполнению сортировки по возрастанию массивов
-
Обменная сортировка или «Метод пузырька»
Простой алгоритм сортировки. Для понимания и реализации этот алгоритм - простейший, но эффективен он лишь для небольших массивов. Сложность алгоритма: O(n²).
Алгоритм считается учебным и практически не применяется вне учебной литературы, вместо него на практике применяются более эффективные алгоритмы сортировки. В то же время метод сортировки обменами лежит в основе некоторых более совершенных алгоритмов, таких как шейкерная сортировка, пирамидальная сортировка и быстрая сортировка.
работает следующим образом. Начиная с конца массива сравниваются два соседних элемента (a[n] и a[n-1]). Если выполняется условие a[n-1] > a[n], то значения элементов меняются местами. Процесс продолжается для a[n-1] и a[n-2] и т.д., пока не будет произведено сравнение a[2] и a[1]. Понятно, что после этого на месте a[1] окажется элемент массива с наименьшим значением. На втором шаге процесс повторяется, но последними сравниваются a[3] и a[2]. И так далее. На последнем шаге будут сравниваться только текущие значения a[n] и a[n-1]. Понятна аналогия с пузырьком, поскольку наименьшие элементы (самые "легкие") постепенно "всплывают" к верхней границе массива. Пример сортировки методом пузырька показан в таблице 2.1.
Таблица 2.1. Пример сортировки методом пузырька
Начальное состояние массива
8 23 5 65 44 33 1 6
Шаг 1
8 23 5 65 44 33 1 6
8 23 5 65 44 1 33 6
8 23 5 65 1 44 33 6
8 23 5 1 65 44 33 6
8 23 1 5 65 44 33 6
8 1 23 5 65 44 33 6
1 8 23 5 65 44 33 6
Шаг 2
1 8 23 5 65 44 6 33
1 8 23 5 65 6 44 33
1 8 23 5 6 65 44 33
1 8 23 5 6 65 44 33
1 8 5 23 6 65 44 33
1 5 8 23 6 65 44 33
Шаг 3
1 5 8 23 6 65 33 44
1 5 8 23 6 33 65 44
1 5 8 23 6 33 65 44
1 5 8 6 23 33 65 44
1 5 6 8 23 33 65 44
Шаг 4
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
Шаг 5
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
Шаг 6
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
Шаг 7
1 5 6 8 23 33 44 65
Пример 5.
Упорядочить по возрастанию сгенерированный случайным образом массив из 10 целых чисел с использованием метода "пузырька" (рис. 3)
Текст программы
Program upcase;
Uses crt;
Const n =10; k1=10; k2=2*k1+1;
Type vec=array[1..n] of integer;
Var a,b :vec;
k,i,f,r :integer;
ch :char;
l :Boolean;
Begin
Repeat
ClrScr;
Randomize;
Write('Исходный массив a[i]=');
For i:=1 to n do
Begin
f:=Random(k2);
a[i]:=k1-f;
Write(a[i]:3);
End;
Writeln;
b:=a;
Repeat
l:=true;
for i:=1 to n-1 do
If b[i]>b[i+1] then
Begin
r:=b[i];b[i]:=b[i+1]; b[i+1]:=r; l:=false;
End;
Until l;
Write('Упорядоченный массив b[i]=');
For i:=1 to n do Write(b[i]:3);
Readln;
ch:=ReadKey;
Until ch=#27;
End.

Рисунок 3. Результат упорядочения по возрастанию сгенерированных случайным образом массивов
Пары стоящих рядом элементов просматриваются в направлении снизу вверх и сравниваются. Если верхний элемент оказывается меньше нижнего по рисунку, то они меняются местами. Продолжая этот процесс циклически, мы в конце концов придем к отсортированному файлу. Файл расположен вертикально снизу вверх, чтобы эффект всплывающего пузырька выглядел более наглядно. Элементы с большим значением ключа "всплывают" наверх, после последовательных сравнений с соседними элементами.
Алгоритм имеет следующий вид.

-
Сортировка выбором
При сортировке массива a[1], a[2], ..., a[n] методом простого выбора среди всех элементов находится элемент с наименьшим значением a[i], и a[1] и a[i] обмениваются значениями. Затем этот процесс повторяется для получаемых подмассивов a[2], a[3], ..., a[n], ... a[j], a[j+1], ..., a[n] до тех пор, пока мы не дойдем до подмассива a[n], содержащего к этому моменту наибольшее значение. Работа алгоритма иллюстрируется примером в таблице 2.5.
Таблица 2.2. Пример сортировки простым выбором
Начальное состояние массива
8 23 5 65 44 33 1 6
Шаг 1
1 23 5 65 44 33 8 6
Шаг 2
1 5 23 65 44 33 8 6
Шаг 3
1 5 6 65 44 33 8 23
Шаг 4
1 5 6 8 44 33 65 23
Шаг 5
1 5 6 8 33 44 65 23
Шаг 6
1 5 6 8 23 44 65 33
Шаг 7
1 5 6 8 23 33 65 44
Шаг 8
1 5 6 8 23 33 44 65
Для метода сортировки простым выбором требуемое число сравнений - nx(n-1)/2. Порядок требуемого числа пересылок (включая те, которые требуются для выбора минимального элемента) в худшем случае составляет O(n2). Однако порядок среднего числа пересылок есть O(n?ln n), что в ряде случаев делает этот метод предпочтительным.
-
Сортировка разделением (Quicksort) или быстрая сортировка
Метод сортировки разделением был предложен Чарльзом Хоаром (он любит называть себя Тони) в 1962 г. Этот метод является развитием метода простого обмена и настолько эффективен, что его стали называть "методом быстрой сортировки - Quicksort".
Основная идея алгоритма состоит в том, что случайным образом выбирается некоторый элемент массива x, после чего массив просматривается слева, пока не встретится элемент a[i] такой, что a[i] > x, а затем массив просматривается справа, пока не встретится элемент a[j] такой, что a[j] < x. Эти два элемента меняются местами, и процесс просмотра, сравнения и обмена продолжается, пока мы не дойдем до элемента x. В результате массив окажется разбитым на две части - левую, в которой значения ключей будут меньше x, и правую со значениями ключей, большими x. Далее процесс рекурсивно продолжается для левой и правой частей массива до тех пор, пока каждая часть не будет содержать в точности один элемент. Понятно, что как обычно, рекурсию можно заменить итерациями, если запоминать соответствующие индексы массива. Проследим этот процесс на примере нашего стандартного массива (таблица 2.6).
Таблица 2.3. Пример быстрой сортировки
Начальное состояние массива
8 23 5 65 |44| 33 1 6
Шаг 1 (в качестве x выбирается a[5])
|--------|
8 23 5 6 44 33 1 65
|---|
8 23 5 6 1 33 44 65
Шаг 2 (в подмассиве a[1], a[5] в качестве x выбирается a[3])
8 23 |5| 6 1 33 44 65
|--------|
1 23 5 6 8 33 44 65
|--|
1 5 23 6 8 33 44 65
Шаг 3 (в подмассиве a[3], a[5] в качестве x выбирается a[4])
1 5 23 |6| 8 33 44 65
|----|
1 5 8 6 23 33 44 65
Шаг 4 (в подмассиве a[3], a[4] выбирается a[4])
1 5 8 |6| 23 33 44 65
|--|
1 5 6 8 23 33 44 65
На самом деле, в большинстве утилит, выполняющих сортировку массивов, используется именно этот алгоритм.
Пример 6. Быстрая сортировка.(рис.4)
program Quitsort;
uses
crt;
Const
N=10;
Type
Mas=array[1..n] of integer; { тип переменой вводим }
var
a: mas; {переменная а типа массива }
k: integer;
function Part(l, r: integer):integer; { описывается функция }
var
v, i, j, b: integer;
begin
V:=a[r];
I:=l-1;
j:=r;
repeat { цикл с постусловием (пока условие не наступило мы работаем в цикле)}
repeat
dec(j) { функция уменьшаем на 1}
until (a[j]<=v) or (j=i+1); {конец цикла (перебор)}
repeat
inc(i) {увеличиваем на 1}
until (a[i]>=v) or (i=j-1); {конец цикла (увеличение на 1 и)}
b:=a[i];
a[i]:=a[j]; {замена во внешнем цикле}
a[j]:=b;
until i>=j;
a[j]:=a[i];
a[i]:= a[r];
a[r]:=b;
part:=i; {присваиваем самой функции значение i}
end;
procedure QuickSort(l, t: integer); { процедура быстрой сортировки}
var i: integer;
begin
if l<t then
begin
i:=part(l, t);
QuickSort(l,i-1);
QuickSort(i+1,t);
end;
end;
begin
clrscr;
randomize; {запускаем генератор случайных чисел}
for k:=1 to 10 do
begin
a[k]:=random(100); {формируем массив случайных чисел и выдаем их }
write(a[k]:3);
end;
QuickSort(1,n); { происходит сортировка}
writeln; {оставляем пустую строку}
for k:=1 to n do
write(a[k]:3);
readln; {приостановка}
end.
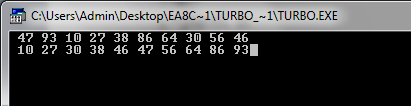
Рисунок 4. Результат создания быстрой сортировки.
Основная стратегия ускорения алгоритмов сортировка - обмены между как можно более дальними элементами исходного файла - в методе быстрой сортировки реализована за счет того, что один из ключей в исходном файле используется для разделения его на два подфайла так, чтобы слева от выбранного элемента находились только элементы с меньшими ключами, а справа - только с большими. Элемент, разделяющий файл, помещается между его двумя подфайлами и процедура выполняется рекурсивно для каждой половины до тех пор, пока в очередном новом подфайле не окажется меньше, чем М элементов, где М - заранее выбранное число. Рассмотрим схему алгоритма.
-
Сортировка с помощью дерева (Heapsort)
Сортировка пирамидой использует сортирующее дерево. Сортирующее дерево - это такое двоичное дерево, у которого выполнены условия:
-
Каждый лист имеет глубину либо d, либо d − 1, d - максимальная глубина дерева.
-
Значение в любой вершине больше, чем значения её потомков.
Удобная структура данных для сортирующего дерева - такой массив Array, что Array[1] - элемент в корне, а потомки элементаArray[i] - Array[2i] и Array[2i+1].
Алгоритм сортировки будет состоять из двух основных шагов:
1. Выстраиваем элементы массива в виде сортирующего дерева:
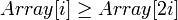
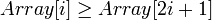
при  .
.
Этот шаг требует O(n) операций.
2. Будем удалять элементы из корня по одному за раз и перестраивать дерево. То есть на первом шаге обмениваем Array[1] иArray[n], преобразовываем Array[1], Array[2], … , Array[n-1] в сортирующее дерево. Затем переставляем Array[1] иArray[n-1], преобразовываем Array[1], Array[2], … , Array[n-2] в сортирующее дерево. Процесс продолжается до тех пор, пока в сортирующем дереве не останется один элемент. Тогда Array[1], Array[2], … , Array[n] - упорядоченная последовательность.
Этот шаг требует O(nlogn) операций.
-
Сортировка со слиянием
Сортировки со слиянием, как правило, применяются в тех случаях, когда требуется отсортировать последовательный файл, не помещающийся целиком в основной памяти. Методам внешней сортировки посвящается следующая часть книги, в которой основное внимание будет уделяться методам минимизации числа обменов с внешней памятью. Однако существуют и эффективные методы внутренней сортировки, основанные на разбиениях и слияниях.
Один из популярных алгоритмов внутренней сортировки со слияниями основан на следующих идеях (для простоты будем считать, что число элементов в массиве, как и в нашем примере, является степенью числа 2). Сначала поясним, что такое слияние. Пусть имеются два отсортированных в порядке возрастания массива p[1], p[2], ..., p[n] и q[1], q[2], ..., q[n] и имеется пустой массив r[1], r[2], ..., r[2?n], который мы хотим заполнить значениями массивов p и q в порядке возрастания. Для слияния выполняются следующие действия: сравниваются p[1] и q[1], и меньшее из значений записывается в r[1]. Предположим, что это значение p[1]. Тогда p[2] сравнивается с q[1] и меньшее из значений заносится в r[2]. Предположим, что это значение q[1]. Тогда на следующем шаге сравниваются значения p[2] и q[2] и т.д., пока мы не достигнем границ одного из массивов. Тогда остаток другого массива просто дописывается в "хвост" массива r.(Таблица 2.4)
Таблица 2.4. Пример сортировки со слиянием
Начальное состояние массива
8 23 5 65 44 33 1 6
Шаг 1
6 8 1 23 5 33 44 65
Шаг 2
6 8 44 65 1 5 23 33
Шаг 3
1 5 6 8 23 33 44 65
Пример7 . Простой пример сортировки 2х упорядоченных массивов слиянием. (рис.5)
uses crt;
var a,b,c:array[1..500] of integer;
n,m,i,j,k:integer;
begin
clrscr;
write('n=');readln(n);
write('m=');readln(m);
writeln('Massiv A:');
for i:=1 to n do
begin
a[i]:=2*i+1;{введем нечетные числа}
write(a[i],' ');{введем четные числа}
end;
writeln;
writeln('Massiv B:');
for i:=1 to m do
begin
b[i]:=2*i;
write(b[i],' ');
end;
writeln;
i:=1; j:=1; k:=1; {устанавливаем счётчики}
while (i<=n) or (j<=m) do {пока не дошли до конца каждого из массивов}
begin
if (i<=n) and (j<=m) then {если оба массива ещё не закончились}
begin
if a[i]
begin
c[k]:= a[i];
inc (i); {переходим к следующему элементу соответствующего массива}
inc (k); {переходим к следующему элементу конечного массива}
end
else
begin
c[k]:= b[j];
inc (j);
inc (k);
end
end
else if j>m then {иначе один из массивов уже закончился}
begin {и мы пишем из того, в котором ещё есть элементы}
c[k]:= a[i];
inc (i);
inc (k);
end
else if i>n then
begin
c[k]:= b[j];
inc (j);
inc (k);
end;
end;
writeln('Massiv C:');
for i:=1 to m+n do
write(c[i],' ');
readln
end.
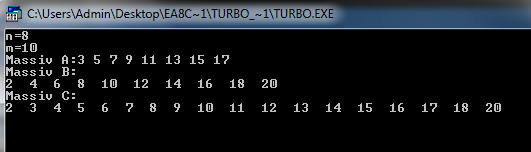
Рисунок 5. Результат создания сортировки слиянием
-
Методы внешней сортировки
Принято называть "внешней" сортировкой сортировку последовательных файлов, располагающихся во внешней памяти и слишком больших, чтобы можно было целиком переместить их в основную память и применить один из разделе методов внутренней сортировки. Наиболее часто внешняя сортировка применяется в системах управления базами данных при выполнении запросов, и от эффективности применяемых методов существенно зависит производительность СУБД.
Следует пояснить, почему речь идет именно о последовательных файлах, т.е. о файлах, которые можно читать запись за записью в последовательном режиме, а писать можно только после последней записи. Методы внешней сортировки появились, когда наиболее распространенными устройствами внешней памяти были магнитные ленты. Для лент чисто последовательный доступ был абсолютно естественным. Когда произошел переход к запоминающим устройствам с магнитными дисками, обеспечивающими "прямой" доступ к любому блоку информации, казалось, что чисто последовательные файлы потеряли свою актуальность. Однако это ощущение было ошибочным.
Все дело в том, что практически все используемые в настоящее время дисковые устройства снабжены подвижными магнитными головками. При выполнении обмена с дисковым накопителем выполняется подвод головок к нужному цилиндру, выбор нужной головки (дорожки), прокрутка дискового пакета до начала требуемого блока и, наконец, чтение или запись блока. Среди всех этих действий самое большое время занимает подвод головок. Именно это время определяет общее время выполнения операции. Единственным доступным приемом оптимизации доступа к магнитным дискам является как можно более "близкое" расположение на накопителе последовательно адресуемых блоков файла. Но и в этом случае движение головок будет минимизировано только в том случае, когда файл читается или пишется в чисто последовательном режиме. Именно с такими файлами при потребности сортировки работают современные СУБД.
Следует также заметить, что на самом деле скорость выполнения внешней сортировки зависит от размера буфера (или буферов) основной памяти, которая может быть использована для этих целей.
А вот и сами методы сортировки:
-
Прямое слияние. Алгоритм Боуза - Нельсона
Алгоритм прямого слияния - простейший алгоритм внешней сортировки, основанный на процедуре слияния последовательностей, называемых серией и представляющих собой упорядоченные подпоследовательности из записей файлов.
Серия - несколько последовательно расположенных записей файла, упорядоченных по ключам. Количество записей в серии называется ее длиной.
Последняя серия может иметь длину меньшую, чем остальные серии файлов.
Суть алгоритма прямого слияния заключается в след.
В исходном состоянии все n записей делятся на 2 файла t1, t2. считается, что каждый из этих файлов состоит из серии длины t.
1. соответствующие серии файлов t1, t2 сливаются попарно и поочередно записываются в файлы g1, g2, организованные в виде серий удвоенной длины относительно t1, t2
После этого t1, t2 делаются пустыми.
2. Соответствие серии файлов g1, g2, попарно сливаются и поочередно записываются в t1, t2, организованные в виде серий удвоенной длины относительно g1, g2. После этого g1, g2 делаются пустыми.
3. Шаги 1 и 2 повторяются до тех пор, пока 1 из 2 файлов в любой паре не станет пустым, тогда другой файл этой пары будет содержать единственную серию длины n, т.е. отсортированный исходный файл.
Следует обратить внимание на необходимость копирования последней серии, которая может остаться без пары.
На каждом проходе (шаг 1 или 2) выполняется слияние серий с получением новых серий удвоенной длины и одновременно разделение исходного набора данных на 2 файла.
После выполнения i проходов получаем 2 файла состоящих из серий 2i
Окончание процесса происходит при выполнении условия:
2i> =n
Следовательно, процесс сортировки прямым слиянием требует порядка log2n проходов.
А методы прямой сортировки требуют не меньше n проходов. Отсюда заметна более высокая скорость сортировки слияния даже по сравнению с прямыми методами сортировки.
Но, для сортировки массивов процедура слияния не используется, т.к. здесь требуется 2n ячеек памяти.
Пример 8. Исходная последовательность
А = 44 55 12 42 94 18 06 67
1 b = 44 55 12 42
с = 94 18 06 67
а = 44 94' 18 55' 06 12' 42 67
2 b = 44 94' 18 55'
с =06 12' 42 67
а = 06 12 44 94' 18 42 55 67'
3 b = 06 12 44 94'
с = 18 42 55 67'
а = 06 12 18 42 44 55 67 94
Заметим, что для выполнения внешней сортировки методом прямого слияния в основной памяти требуется расположить всего лишь две переменные - для размещения очередных записей из файлов B и C. Файлы A, B и C будут O(log n) раз прочитаны и столько же раз записаны. Главным минусом сортировки слиянием является удвоение размера памяти, первоначально занятой сортируемыми данными. Рассмотрим алгоритм с рекурсивным актом слияния, предложенный Боузом и Нельсоном и не требующий резерва памяти.
Пример 9.
Const n=200;
Type
tipkl=word;
tip = Record
kl: tipkl;
z:Array[1..50] of real
End;
Var
A: Array[1..n] of tip;
j:word;
Procedure Bose (Var AA; voz:Boolean);
Var
m,j:word; x:tip; {tip - тип сортируемых записей}
A: Array [1..65520 div Sizeof(tip)] of tip Absolute AA;
Procedure Sli(j,r,m: word); { r - расстояние между началами
сливаемых частей, а m - их размер, j - наименьший номер записи}
Begin
if j+r<=n Then
If m=1 Then
Begin
If voz Xor (A[j].kl < A[j+r].kl) Then
Begin
x:=A[j];
A[j]:= A[j+r];
A[j+r]:=x
End
End
Else
Begin
m:=m div 2;
Sli(j,r,m); {Слияние "начал"}
If j+r+m<=n Then
Sli(j+m,r,m); {Слияние "концов"}
Sli(j+m,r-m,m) End {Слияние в центральной части}
End{блока Sli};
Begin
m:=1;
Repeat
j:=1; {Цикл слияния списков равного размера: }
While j+m<=n do
Begin
Sli(j,m,m);
j:=j+m+m
End;
m:=m+m {Удвоение размера списка перед началом нового прохода}
Until m >= n {Конец цикла, реализующего все дерево слияний}
End{блока Bose};
BEGIN
Randomize;
For j:=1 to n do
begin
A[j].kl:= Random(65535);
Write(A[j].kl:8);
end;
Readln;
Bose(A,true);
For j:=1 to n do
Write(A[j].kl:8);
Readln
END.
-
Естественное слияние
При использовании метода прямого слияния не принимается во внимание то, что исходный файл может быть частично отсортированным, т.е. содержать упорядоченные подпоследовательности записей. Серией называется подпоследовательность записей ai, a(i+1), ..., aj такая, что ak <= a(k+1) для всех i <= k < j, ai < a(i-1) и aj > a(j+1). Метод естественного слияния основывается на распознавании серий при распределении и их использовании при последующем слиянии.
Как и в случае прямого слияния, сортировка выполняется за несколько шагов, в каждом из которых сначала выполняется распределение файла A по файлам B и C, а потом слияние B и C в файл A. При распределении распознается первая серия записей и переписывается в файл B, вторая - в файл C и т.д. При слиянии первая серия записей файла B сливается с первой серией файла C, вторая серия B со второй серией C и т.д. Если просмотр одного файла заканчивается раньше, чем просмотр другого (по причине разного числа серий), то остаток недопросмотренного файла целиком копируется в конец файла A. Процесс завершается, когда в файле A остается только одна серия.
Пример 10.
Пусть даны ключи записей
5 7 8 3 9 4 1 7 6
Ищем подсписки
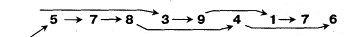
В один общий список соединяются 1-й, 3-й, 5-й и т. д. подсписки, в другой - 2-й, 4-й и т. д. подсписки. Произведем слияние 1 подсписка 1 списка и 1 подсписка 2 списка, 2 подсписка 1 списка и 2 подсписка 2 списка и т.д.
Будут получены следующие цепи
3 --> 5 --> 7 --> 8 --> 9 и 1 --> 4 --> 7
Подсписок, состоящий из записи "6", пары не имеет и "принудительно" объединяется с последней цепью, принимающей вид 1 --> 4--> 6 --> 7.
При нашем небольшом числе записей 2-й этап, на котором сливаются две цепи, окажется последним.
В общем случае на каждом этапе подсписок - результат слияния начальных подсписков 1 и 2 списка становится началом нового 1-го списка, а результат слияния следующих двух подсписков - началом 2-го списка. Следующие образуемые подсписки поочередно включаются в 1-й и во 2-й список. Для программной реализации заводят массив sp: элемент sp[i] - это номер записи, которая следует за i-й.
Последняя запись одного подсписка ссылается на первую запись другого, а для различения концов подсписков эта ссылка снабжается знаком минус.
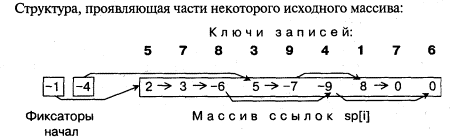
Repeat {Повторение актов слияний подсписков}
If A[j].kl < A[i].kl Then {Выбирается меньшая запись}
Begin sp[k]:=j; k:=j; j:=sp[j];
If j<=0 Then {Сцепление с остатком "i"- подсписка}
Begin sp[k]:=i; Repeat m:=i; i:=sp[i] Until i<=0 End
End
Else
Begin sp[k]:=i; k:=i; i:=sp[i];
If i<=0 Then {Сцепление с остатком "j"- подсписка}
Begin sp[k]:=j; Repeat m:=j; j:=sp[j] Until j<=0 End
End;
If j<=0 Then Begin sp[m]:= 0; sp[p]:=-sp[p]; i:=-i;
j:=-j; If j<>0 Then p:=r; k:=r; r:=m End
Until j=0;
{В конец сформированного подсписка всегда заносится нулевая ссылка (sp[m]:= 0), ибо он может оказаться последним.
Действие sp[p]:= -sp[p] обозначает минусом конец ранее построенного подсписка.
В переменных i,j ссылки на начала новых сливаемых подсписков - со знаком минус; его снимаем. Переход к новым подспискам требует обновления переменных p, k, r} [3, стр. - 169]
-
Сбалансированное многопутевое слияние
В основе метода внешней сортировки сбалансированным многопутевым слиянием является распределение серий исходного файла по m вспомогательным файлам B1, B2, ..., Bm и их слияние в m вспомогательных файлов C1, C2, ..., Cm. На следующем шаге производится слияние файлов C1, C2, ..., Cm в файлы B1, B2, ..., Bm и т.д., пока в B1 или C1 не образуется одна серия.
-
Многофазная сортировка
Идея многофазной сортировки состоит в том, что из имеющихся m вспомогательных файлов (m-1) файл служит для ввода сливаемых последовательностей, а один - для вывода образуемых серий. Как только один из файлов ввода становится пустым, его начинают использовать для вывода серий, получаемых при слиянии серий нового набора (m-1) файлов. Таким образом, имеется первый шаг, при котором серии исходного файла распределяются по m-1 вспомогательному файлу, а затем выполняется многопутевое слияние серий из (m-1) файла, пока в одном из них не образуется одна серия.
Очевидно, что при произвольном начальном распределении серий по вспомогательным файлам алгоритм может не сойтись, поскольку в единственном непустом файле будет существовать более, чем одна серия. Предположим, например, что используется три файла B1, B2 и B3, и при начальном распределении в файл B1 помещены 10 серий, а в файл B2 - 6. При слиянии B1 и B2 к моменту, когда мы дойдем до конца B2, в B1 останутся 4 серии, а в B3 попадут 6 серий. Продолжится слияние B1 и B3, и при завершении просмотра B1 в B2 будут содержаться 4 серии, а в B3 останутся 2 серии. После слияния B2 и B3 в каждом из файлов B1 и B2 будет содержаться по 2 серии, которые будут слиты и образуют 2 серии в B3 при том, что B1 и B2 - пусты. Тем самым, алгоритм не сошелся. [6]
Таблица 2.6. Пример начального распределения серий, при котором трехфазная внешняя сортировка не приводит к нужному результату
Число серий в файле B1
Число серий в файле B2
Число серий в файле B3
10
6
0
4
0
6
0
4
2
2
2
0
0
0
2
Попробуем понять, каким должно быть начальное распределение серий, чтобы алгоритм трехфазной сортировки благополучно завершал работу и выполнялся максимально эффективно. Для этого рассмотрим работу алгоритма в обратном порядке, начиная от желательного конечного состояния вспомогательных файлов. Нас устраивает любая комбинация конечного числа серий в файлах B1, B2 и B3 из (1,0,0), (0,1,0) и (0,0,1). Для определенности выберем первую комбинацию. Для того, чтобы она сложилась, необходимо, чтобы на непосредственно предыдущем этапе слияний существовало распределение серий (0,1,1). Чтобы получить такое распределение, необходимо, чтобы на непосредственно предыдущем этапе слияний распределение выглядело как (1,2,0) или (1,0,2). Опять для определенности остановимся на первом варианте. Чтобы его получить, на предыдущем этапе годились бы следующие распределения: (3,0,2) и (0,3,1). Но второй вариант хуже, поскольку он приводится к слиянию только одной серии из файлов B2 и B3, в то время как при наличии первого варианта распределения будут слиты две серии из файлов B1 и B3. Пожеланием к предыдущему этапу было бы наличие распределения (0,3,5), еще раньше - (5,0,8), еще раньше - (13,8,0) и т.д.
Это рассмотрение показывает, что метод трехфазной внешней сортировки дает желаемый результат и работает максимально эффективно (на каждом этапе сливается максимальное число серий), если начальное распределение серий между вспомогательными файлами описывается соседними числами Фибоначчи. Напомним, что последовательность чисел Фибоначчи начинается с 0, 1, а каждое следующее число образуется как сумма двух предыдущих:
(0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, ....)
Аналогичные (хотя и более громоздкие) рассуждения показывают, что в общем виде при использовании m вспомогательных файлов условием успешного завершения и эффективной работы метода многофазной внешней сортировки является то, чтобы начальное распределение серий между m-1 файлами описывалось суммами соседних (m-1), (m-2), ..., 1 чисел Фибоначчи порядка m-2. Последовательность чисел Фибоначчи порядка p начинается с p нулей, (p+1)-й элемент равен 1, а каждый следующий равняется сумме предыдущих p+1 элементов. Ниже показано начало последовательности чисел Фибоначчи порядка 4:
(0, 0, 0, 0, 1, 1, 2, 4, 8, 16, 31, 61, ...)
При использовании шести вспомогательных файлов идеальными распределениями серий являются следующие:
1 0 0 0 0
1 1 1 1 1
2 2 2 2 1
4 4 4 3 2
8 8 7 6 4
16 15 14 12 8
........
Понятно, что если распределение основано на числе Фибоначчи fi, то минимальное число серий во вспомогательных файлах будет равно fi, а максимальное - f(i+1). Поэтому после выполнения слияния мы получим максимальное число серий - fi, а минимальное - f(i-1). На каждом этапе будет выполняться максимально возможное число слияний, и процесс сойдется к наличию всего одной серии.
Поскольку число серий в исходном файле может не обеспечивать возможность такого распределения серий, применяется метод добавления пустых серий, которые в дальнейшем как можно более равномерного распределяются между промежуточными файлами и опознаются при последующих слияниях. Понятно, что чем меньше таких пустых серий, т.е. чем ближе число начальных серий к требованиям Фибоначчи, тем более эффективно работает алгоритм. [5]
-
Программа
Осуществить слияние файлов в один. (рис. 6)
program Project1;
const
Fn1 = 'file1.txt';
Fn2 = 'file2.txt';
Fn3 = 'file3.txt';
N = 100;
var
F1, F2, F3 : Text;
i, j, k, Num : Integer;
Arr : array[1..N] of Integer;
begin
(*Связываем файловые переменные с файлами.*)
Assign(F1, Fn1);
Assign(F2, Fn2);
Assign(F3, Fn3);
(*Записываем в первые 2 файла числа по возрастанию.*)
(*В первый файл записываем чётные числа: 0..10.*)
Rewrite(F1);
i := 0;
while i <= 10 do begin
(*Перед записью очередного числа выполняем переход на следующую строку.
Это действие не выполняем только для самого первого числа.*)
if i > 0 then Writeln(F1);
Write(F1, i);
i := i + 2;
end;
(*Записываем в файл содержимое файлового буфера. Это действие
выполняется только для текстовых файлов.*)
Flush(F1);
(*Во второй файл записываем нечётные числа: 1..9.*)
Rewrite(F2);
i := 1;
while i <= 10 do begin
if i > 1 then
Write(F2, i);
i := i + 2;
end;
Flush(F2);
(*Открываем первый файл, читаем из него числа и записываем их в массив Arr.*)
Reset(F1);
i := 0;
while not Eof(F1) do begin
i := i + 1;
Read(F1, Arr[i]);
end;
(*Теперь выполняем слияние на массиве. Для этого откроем второй файл.
Будем последовательно читать из него числа и искать позицию в массиве,
куда можно вставить очередное прочитанное число. Далее, вставляем
число в массив. При этом, если требуется, будем сдвигать остальные числа
массива на одну позицию вправо - чтобы освободить место для вставки.*)
Reset(F2);
while not Eof(F2) do begin
(*Читаем очередное число из второго файла.*)
Readln(F2, Num);
(*Ищем позицию в массиве, на которой расположено число большее или равное
тому, которое прочитано из файла. Если такое число найдётся в массиве, тогда
j будет содержать индекс этого числа. Если такое число
не найдётся, тогда j окажется на 1 больше, чем i. - Т. е. j будет указывать
на место, расположенное после последнего значимого элемента массива.*)
j := 1;
while (j <= i) and (Arr[j] < Num) do begin
j := j + 1;
end;
if j > i then begin
(*Вставляем прочитанное из файла число справа от последнего значимого
элемента массива.*)
Arr[j] := Num;
end else begin
(*Сдвигаем элементы массива, расположенные в позициях i..j
на 1 позицию вправо.*)
for k := i downto j do begin
Arr[k + 1] := Arr[k];
end;
(*Вставляем на освободившуюся позицию прочитанное из файла число.*)
Arr[j] := Num;
end;
(*Т. к. мы добавили в массив новое число, то количество значимых элементов
массива увеличилось на единицу.*)
i := i + 1;
end;
(*Теперь записываем элементы массива в третий файл.*)
Rewrite(F3);
for j := 1 to i do begin
if j > 1 then Writeln(F3);
Write(F3, Arr[j]);
end;
(*Так как далее следует закрытие файлов, то Flush() в данном случае
выполнять не обязательно.*)
Flush(F3);
Close(F1);
Close(F2);
Close(F3);
Writeln('Задача выполнена. Результаты записаны в файлы:');
Writeln(Fn1, ', ', Fn2, ', ', Fn3);
Readln;
end.

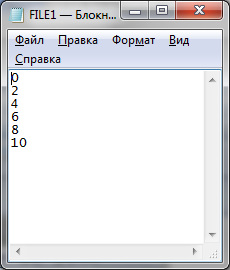
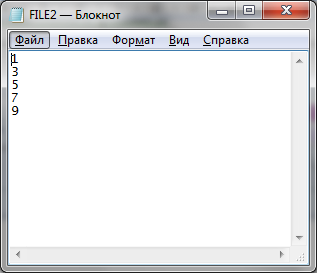
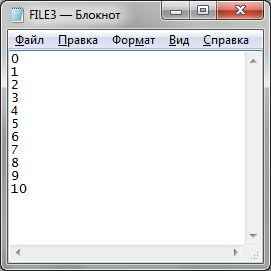
Рисунок 6. Результат слияния файлов с сортировкой элементов по ним
Заключение
В данной работе были рассмотрены способы сортировки массивов, что удовлетворяет цели ее написания. Данная цель полностью достигнута, так как в процессе написания были решены задачи:
-
Рассмотреть теоретические основы структуры данных в Pascal.
-
Рассмотреть методы внутренней и внешней сортировки.
-
Составить программу, используя полученные теоретические данные.
В заключении работы будет в полной мере изучен поднятый вопрос и локазан на практике.
Акцентируем внимание на том, какие алгоритмы сортировки массивов более удобны. Алгоритмы сортировки и поиска чрезвычайно широко распространены практически во всех задачах обработки информации. Различные сортировки массивов отличаются по быстродействию. Существуют простые методы сортировок, которые удобны для объяснения принципов сортировок, т.к. имеют простые и короткие алгоритмы. Усложненные методы требуют меньшего числа операций, но сами операции более сложные, поэтому для небольших массивов простые методы более эффективны. Однако, простые методы сортировки являются в тоже время менее экономичными. Самый известный алгоритм - пузырьковая сортировка. Его популярность объясняется интересным названием и простотой самого алгоритма.
Таким образом, сортировки «пузырьковая», методом выбора, включением, слиянием. Все вышеперечисленные сортировки являются сортировками порядка n2, что делает их слишком медленными и неэффективными на больших объёмах данных. Для больших объёмов данных эти сортировки будут медленными, а начиная с некоторой величины размерности массива, они будут слишком медленными, чтобы их можно было использовать на практике.
Список используемых источников
-
Методы сортировки и поиска. С.Д. Кузнецов. Учебное пособие. - 2009 г.
-
. Румянцев Д. Г., Монастырский Л. Ф. Путь программиста: Опыт создания личности программиста.- М.: ИНФРА-М, 2000.- 540 с.
-
Вирт Н. Язык программирования Паскаль // Алгоритмы и организация решения экономических задач.
-
Перминов О.Н. Язык программирования Паскаль. - М.: Радио и связь, 2000. - 160 с.
-
Источник: Львовский М.Б. Методическое пособие «BOOK» по информатике для 9-11 классов. Адрес: markbook.chat.ru/book/
-
Для подготовки данной работы были использованы материалы с сайта comp-science.ru/