- Преподавателю
- Информатика
- Статья на тему Общая структура МПС
Статья на тему Общая структура МПС
| Раздел | Информатика |
| Класс | 12 класс |
| Тип | Статьи |
| Автор | Сиразетдинова Э.Р. |
| Дата | 10.02.2016 |
| Формат | doc |
| Изображения | Есть |

-
Общая структура МПС
Микропроцессор - центральная часть любой микропроцессорной системы (МПС) - включает в себя АЛУ и ЦУУ, реализующее командный цикл. МП может функционировать только в составе МПС, включающей в себя, кроме МП, память, устройства ввода/вывода, вспомогательные схемы (тактовый генератор, контроллеры прерываний и ПДП, шинные формирователи, регистры-защелки и др.).
В любой МПС можно выделить следующие основные части (подсистемы) :
-
процессорный модуль;
-
память;
-
внешние устройства (внешние ЗУ + устройства ввода/вывода);
-
подсистему прерываний;
-
подсистему прямого доступа в память.
С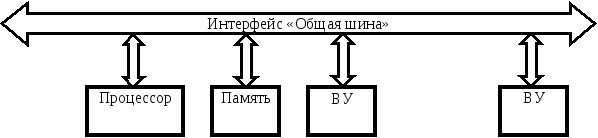
вязь между процессором и другими устройствами МПС может осуществляться по принципам радиальных связей, общей шины или комбинированным способом. В однопроцессорных МПС, особенно 8- и 16-разрядных, наибольшее распространение получил принцип связи "Общая шина", при котором все устройства подключаются к интерфейсу одинаковым образом (Рис.1.1).
Рис.1.1. Структура МПС с интерфейсом "Общая шина"
Все сигналы интерфейса делятся на три основные группы - данных, адреса и управления. Многочисленные разновидности интерфейсов "Общая шина" обеспечивают передачу по раздельным или мультиплексированным линиям (шинам). Например, интерфейс Microbus, с которым работают большинство 8-разрядных МПС на базе i8080, передает адрес и данные по раздельным шинам, но некоторые управляющие сигналы передаются по шине данных. Интерфейс Q-bus, используемый в микро-ЭВМ фирмы DEC (отечественный аналог - микропроцессоры серии К1801) имеет мультиплексированную шину адреса/данных, по которой эта информация передается с разделением во времени. Естественно, что при наличии мультиплексированной шины в состав линий управления необходимо включать специальный сигнал, идентифицирующий тип информации на шине.
Обмен информацией по интерфейсу производится между двумя устройствами, одно из которых является активным, а другое - пассивным. Активное устройство формирует адреса пассивных устройств и управляющие сигналы. Активным устройством выступает, как правило, процессор, а пассивным - всегда память и некоторые ВУ. Однако, иногда быстродействующие ВУ могут выступать в качестве задатчика (активного устройства) на интерфейсе, управляя обменом с памятью (т.н. режим прямого доступа в память - см. раздел 8).
Концепция "Общей шины" предполагает, что обращения ко всем устройствам МПС производится в едином адресном пространстве, однако, в целях расширения числа адресуемых объектов, в некоторых системах искусственно разделяют адресные пространства памяти и ВУ, а иногда даже и памяти программ и памяти данных.
Как известно, процессор является основным вычислительным блоком компьютера, в наибольшей степени определяющим его мощь. Процессор является устройством, исполняющим программу - последовательность команд (инструкций), задуманную программистом и оформленную в виде модуля программного кода. Чтобы понять, что делает процессор, рассмотрим его в окружении системных компонентов IBM PC-совместимого компьютера. Этой компьютерной архитектурой, естественно, не ограничивается сфера применения процессоров.
Всем известный IBM PC-совместимый компьютер представляет собой реализацию так называемой фон-неймановской архитектуры вычислительных машин. Эта архитектура была представлена Джоном фон-Нейманом еще в 1945 году и имеет следующие основные признаки. Машина состоит из блока управления, арифметико-логического устройства (АЛУ), памяти и устройств ввода/вывода. В ней реализуется концепция хранимой программы: программы и данные хранятся в одной и той же памяти.
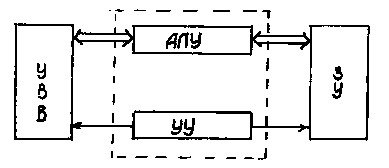
Рис. 1.1 Архитектура фон-Неймана
Если разделить память на память программ и память данных мы получим Гарвардскую архитектуру.
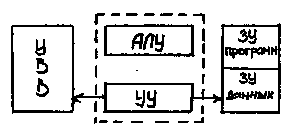
Рис. 1.2 Гарвардская архитектура
Выполняемые действия определяются блоком управления и АЛУ, которые вместе являются основой центрального процессора. Центральный процессор выбирает и исполняет команды из памяти последовательно, адрес очередной команды задается "счетчиком адреса" в блоке управления. Этот принцип исполнения называется последовательной передачей управления. Данные, с которыми работает программа, могут включать переменные - именованные области памяти, в которых сохраняются значения с целью дальнейшего использования в программе.
Фон-неймановская архитектура - не единственный вариант построения ЭВМ, есть и другие, которые не соответствуют указанным принципам (например, потоковые машины). Однако подавляющее большинство современных компьютеров основано именно на этих принципах, включая и сложные многопроцессорные комплексы, которые можно рассматривать как объединение фон-неймановских машин. Конечно же, за более чем полувековую историю ЭВМ классическая архитектура прошла длинный путь развития.
Прерывание - первое отличие современных архитектур от машин фон-Неймана. Работа прерывания заключается в том что при поступлении сигнала прерывания процессор обязан прекратить выполнение текущей программы и немедленно начать обработку процедуры прерывания.
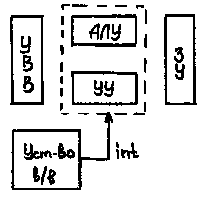
Рис. 1.3 Архитектура фон-Неймана с прерыванием
ПДП (Прямой Доступ к Памяти) - второе отличие современных архитектур от машин фон-Неймана. ПДП позволяет сократить расходы на пересылку единицы информации.
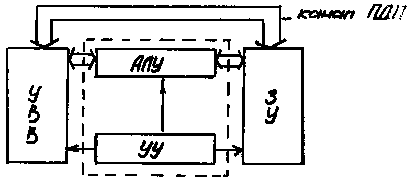
Рис. 1.4 Архитектура фон-Неймана с каналом ПДП
-
Основные схемотехнологические направления производства микропроцессоров
В настоящее время для производства интегральных схем используются следующие основные технологические базисы: транзисторно-транзисторная логика (ТТЛ); ТТЛ с диодами Шоттки (ТТЛШ); маломощная ТТЛШ (МТТЛШ); инжекционная интегральная логика (И2Л) и ее различные варианты (И3Л, ИШЛ и т. д.); р-канальная МОП-технология (р-МОП); n-канальная МОП (n-МОП); комплементарная МОП-технология (КМОП); варианты МОП-технологии (МНОП, ЛИЗМОП); эмиттерно-связанная логика (ЭСЛ).
Рассмотрим основные особенности распространенных технологий производства БИС. Для ТТЛ напряжение питания Uп=5В; стандартные входные уровни сигналов U0<=0.8В, U1>=2.0В, выходные U0<=0.4В; U1>=2.4В. По ТТЛ-технологии реализованы ИС серий К133, К134, К155. По сравнению с обычным ТТЛ, ТТЛШ-вентиль обеспечивает приблизительно вдвое меньшие задержки включения и выключения за счет использования ненасыщенного режима работы транзисторов, а также несколько меньшую мощность потребления и обладает в 1.5-2 раза меньшей площадью. Напряжение питания и стандартные входные-выходные напряжения ТТЛШ-вентиля унифицированы с аналогичными параметрами обычного ТТЛ-вентиля. Вентили ТТЛ и ТТЛШ работоспособны в широком диапазоне температур, изменение мощности их потребления в зависимости от частоты незначительно. По ТТЛШ-технологии реализованы ИС и БИС серий К533, К555, К589, К585, К1802, К1804, а также некоторые БИС серий К583, К584. На основе маломощной ТТЛШ-технологии реализованы ИС серий К1533, К1555.
Диапазон размаха логического сигнала И2Л-вентиля лежит в пределах 0.2-0.8В, поэтому для сопряжения И2Л БИС с ТТЛ-схемами используются специальные входные и выходные каскады. Стандартные И2Л-вентили имеют широкий диапазон рабочих токов питания, при этом их быстродействие прямо пропорционально току инжекции. И2Л БИС работоспособны в диапазоне от 0.1 до 2 значений номинального тока питания, что обеспечивает их работу как в микромощном, так и в быстродействующем режиме. По сравнению с ТТЛШ И2Л-технология обеспечивает приблизительно в десять раз большую степень интеграции БИС при меньшем в 2-3 раза быстродействии. В настоящее время развиваются многочисленные разновидности И2Л-технологии, такие как изопланарная И2Л (И3Л) и инжекционная Шоттки (ИШЛ) логика. ИШЛ по сравнению с И2Л-вентилем обладает приблизительно в 1.5 раза большей площадью, но обеспечивает быстродействие, соизмеримое с ТТЛШ-схемами. Инжекционная логика работоспособна в широком диапазоне температур. Помехоустойчивость схем такая же, как и у ТТЛ-логики. На основе И2Л-технологии реализованы БИС серий К582, К583, К584, К1808, К1815. Перспективным является построение комбинированных кристаллов, когда внутренняя часть строится по инжекционной технологии, а внешняя, для удачного сопряжения с периферией и другими БИС, - по ТТЛ-технологии.
Для работы р-МОП-инвертора необходимо подать напряжение питания Uп=-(9-24)В и напряжение смещения подложки Uсп=-(3-12)В. Выходные напряжения при Uп=-24В обычно принимаются равными U0=-22В, U1=-2В; входные напряжения U0=-12B, U1=-4B. Вентили имеют небольшую площадь, но обладают малым быстродействием (время переключения более 0.1 мкс). Относительная дешевизна этих БИС объясняет их широкое применение в бытовых приборах. Для работы n-МОП-инвертора необходимо подать напряжение питания Uп=5В и напряжение смещения подложки U'сп=-5В, на основе которого в резистивном делителе, подключенном к Uп и к U'сп вырабатывается Uсп. Иногда внутреннее Uсп вырабатывается на основе напряжения питания и земли. Входные и выходные напряжения n-МОП обычно обеспечивают прямое сопряжение с ТТЛ-схемами.
Площадь у n-МОП вентиля в 5-7 раз меньше, чем у ТТЛ и быстродействие в 4-10 раз меньше, чем у ТТЛ-схем. По n-МОП-технологии разработаны комплекты БИС серий К145, К580, К581, К586, К1801, К1809, К1810, К1820.
В состав КМОП-инвертора входят два транзистора разного типа проводимости. Для работы вентилей нет необходимости использовать напряжение смещения подложки. В состоянии логических нуля и единицы вентиль практически не потребляет энергию. Стандартные входные U0<=0.8B, U1>=3.5B и выходные U0<=0.4B, U1>=4.5B. Следует отметить высокую помехоустойчивость КМОП. Амплитуда помехи может составлять до 40% от напряжения питания. Высокопороговая КМОП-логика обычно имеет Uп=9В и не сопрягается с ТТЛ. По высокопороговой технологии выполнена серия К587, по низкопороговой - К564, К561, К588, К1806.
Вентиль ЭСЛ обладает самым большим быстродействием, но занимает самую большую площадь и потребляет большую, чем у всех остальных, мощность. Высокое быстродействие достигается за счет ненасыщенных режимов работы транзисторов. Входные и выходные напряжения составляют U0>=-1.1B, U1<=-1.5B; U1<=-1.65B, U0>=-0.8B соответственно. Из этого следует, что ЭСЛ-вентили невозможно прямо использовать в составе ТТЛ-схем.
-
Характеристики микропроцессоров
Кратко перечислим основные характеристики микропроцессоров:
-
разрядность;
-
быстродействие (тактовая частота, время выполнения "короткой" команды;
-
потребляемая мощность;
-
технология (уровень логических сигналов);
-
архитектурные особенности: система операций, способы адресации, наличие и организация подсистем прерываний и ПДП, объем и организация СОЗУ, конвейер операций, аппаратная поддержка системы виртуальной памяти и т.п.;
-
структурные особенности: количество и назначение шин (стандарт интерфейса), внутренняя структура;
-
число источников питания;
-
число БИС в комплекте;
и др.
Поколения микропроцессоров.
В первые десятилетия своего развития микропроцессоры было принято делить на поколения, причем границы поколений (разумеется, весьма условно) проводились по признаку технологии, освоенной на данном этапе эволюции МП. Рассмотрим кратко особенности первых трех поколений МП.
1.4.1. Микропроцессоры 1 поколения. Первый МП был разработан фирмой INTEL и выпущен в 1971г. на основе p-МОП технологии (i4004). В 1972 и 1973 годах этой же фирмой были выпущены модели i4040, i8008. Фирма Rockwell выпустила модели МП PSS-4, PSS-8. Все они могут быть отнесены к МП 1 поколения, характеристиками которого являются:
-
разрядность - 4..8 бит;
-
технология - p-МОП;
-
быстродействие (RR) - 5..60 мкС;
-
тактовая частота - 200..800 КГц;
-
совмещение шин адреса и данных;
-
число вспомогательных ИС и СИС - 15..50;
-
подсистемы прерываний и ПДП - отсутствуют.
Первые МП 1 поколения - 4-разрядные приборы, использовались для организации десятичной арифметики (калькуляторы). Так, i4004 имел 4-разрядное АЛУ с блоком десятичной коррекции, 16 РОНов, внутренний трехуровневый стек. Объем адресного пространства 212 (возможен выбор одного из 4 банков такого размера). Система команд включала 46 команд: пересылки, ввод/вывод, сдвиги, арифметические команды (+ - ФЗ).
В процессе эволюции МП первого поколения (МП-1) имело место увеличение разрядности (до 8) и некоторое расширение функций. Так, в i4040 добавлены логические операции, увеличен массив РОН (до24), введено одноуровневое прерывание. i8008 предназначался прежде всего для использования в системах управления. В нем, по сравнению с i4004, увеличена разрядность (до 8), добавлены логические команды, но исключен блок десятичной коррекции. Все МП-1 выпускались в стандартном 16-выводовом корпусе.
1.4.2. Микропроцессоры 2 поколения. Совершенствование технологии МОП, переход на n-МОП технологию привел к появлению МП второго поколения, которые отличались от МП-1 не только количественными характеристиками, но и качественно. В 1974г. был выпущен МП i8080, который стал первым и наиболее популярным МП второго поколения (МП-2). Он же положил начало семейству однокристальных МП, которому суждено было стать (и оставаться до настоящего времени) доминирующим на мировом рынке МП. Вслед за i8080 другими фирмами были выпущены МП со сходными (иногда несколько лучшими) характеристиками. Наиболее известными являются. Z80 фирмы Zilog и MS6800 (Motorola). Эти МП, как и i8080, имеют своих 16- и 32-разрядных "потомков". Характерными признаками МП-2 можно считать:
-
переход на более прогрессивные технологии n-МОП и КМОП, позволившие повысить быстродействие МП до 2..2,5 МГц (200..500 тыс. операций RR), снизить потребление мощности (КМОП);
-
значительные архитектурные отличия: расширение системы операций, использование широкого набора способов адресации (прямая, косвенная, относительная, безадресная, непосредственная),введены подсистемы прерываний и прямого доступа в память (ПДП), предусмотрен механизм универсального стека;
-
структурные отличия: шины адреса и данных разделены, уменьшено число вспомогательных ИС и СИС.
МП-2 пришли на смену МП-1, значительно расширив сферу применения МП. Правда, МП-1 (по признаку технологии p-МОП) возродились позже в новом качестве - дешевых приборов бытовой электроники.
Другая судьба ожидала МП-2. Появившиеся микропроцессоры третьего поколения (МП-3) стали развиваться параллельно с МП-2, причем МП-2 легли в основу т.н. однокристальных МП и микро-ЭВМ, а МП-3 - секционированных многокристальных МП.
1.4.3. Переход к третьему поколению МП связан со стремлением к увеличению быстродействия МПС и переходом на биполярные технологии - ТТЛ и ТТЛШ.
Исходя из соотношения dEdt = const,
где dt - время переключения, dE - энергия переключения
очевидно, что повышение быстродействия связано с увеличением рассеиваемой мощности, а следовательно - к снижению степени интеграции кристалла. Первые МП-3 приборы были двухразрядными, что не приводило к увеличению производительности МП, хотя тактовая частота увеличивалась значительно (на порядок). Это обстоятельство повлекло значительные структурные изменения в МП-3 по сравнению с МП-2:
-
микропроцессоры выпускаются в виде секций со средствами межразрядных связей, позволяющими объединять в одну систему произвольное число секций для достижения заданной разрядности. В состав секций включалось АЛУ, РОН и некоторые элементы УУ;
-
устройство управления вынесено на отдельный кристалл (группу кристаллов), общий для всех процессорных секций;
-
за счет резерва внешних выводов (малая разрядность) предусмотрены отдельные шины ввода и вывода данных, адреса, причем данные от разных источников вводились по различным шинам. Так, первый МП-3 i3000 (серия К589 - отечественный аналог) имел три двухразрядные входные шины данных (от памяти, УВВ и УУ) и две выходные шины - данных и адреса;
-
кристаллы управления реализуют УУ с программируемой логикой, что позволяет достаточно легко реализовать практически любую систему команд на фиксированной структуре операционного устройства.
1.4.4. Тенденции развития поколений. В настоящее время технология не является решающим фактором классификации МП, ибо появились разновидности технологий одного типа, обеспечивающие очень широкий спектр характеристик МП, широкое распространение получили комбинированные технологии (например, И2Л + ТТЛШ).
Современные микропроцессоры принято разделять на два больших класса : однокристальные и многокристальные. В свою очередь, однокристальные МП можно разделить на собственно микропроцессоры и однокристальные микро-ЭВМ.
Направление развития однокристальных МП - непрерывное наращивание вычислительной мощности процессора за счет увеличения разрядности, расширения системы команд, появления дополнительных функций - Кэш-памяти, конвейера операций, встроенных процессоров плавающей запятой, аппаратной поддержки виртуальной памяти и др.
Однокристальные микро-ЭВМ, сохраняя вычислительную мощность процессора практически неизменной (на уровне 8-разрядного МП), содержат на кристалле все элементы МПС : тактовый генератор, память программ и данных, контроллеры параллельного и последовательного ввода/вывода, контроллеры прерываний, таймеры, а некоторые микро-ЭВМ - АЦП и ЦАП и другие спец. средства (например, динамические схемы управления восьмисегментной индикацией). Такие БИС можно непосредственно подключать к периферийным устройствам для создания микро-ЭВМ или включать в контур управления.
Многокристальные микропрограммируемые МП используются как элементная база "больших" ЭВМ или специализированных средств, для которых характерны нетрадиционные параметры.
На Рис. 0.1 показаны направления развития различных типов МПС.
Р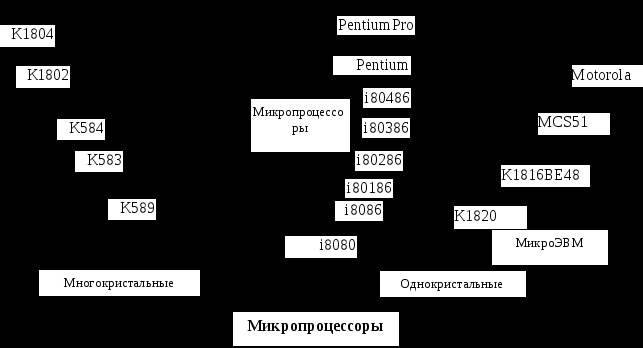
ис. 0.2. Микропроцессоры (дерево развития)
Из Рис. 0.1 видно, что наиболее многочисленное (и распространенное в мире) семейство микропроцессоров - INTEL. Далее будем иллюстрировать основные положения курса примерами организации МП этого семейства : однокристальные МП - i8080-i8086-i80286-i80386-i80486-Pentium-PentiumPro; однокристальные микро-ЭВМ - i8035-i8051/52
4. Шинная организация IBM PC
В основу архитектуры IBM PC изначально был положен принцип открытости, который стал ее отличительной чертой. Основные конкуренты IBM в области персональных машин пришли к этому только через несколько лет после того, как указанный принцип позволил персональным компьютерам фирмы IBM практически завоевать компьютерный рынок.
Принцип открытости, строго говоря, основывается во-первых, на чрезвычайно развитой в IBM PC системе прерываний, которая позволяет "подключать" программы пользователя ко всем ресурсам системы на любом уровне, доступном пользователю, а во-вторых, на системе шин, организующей информационные потоки таким образом, чтобы не только позволить пользователю подключать к ресурсам процессора свои аппаратные средства (возможно, нестандартные), но и дать возможность самой архитектуре совершенствоваться и развиваться за счет введения дополнительных или новых компонентов без каких-либо принципиальных изменений в организации информационных потоков.
Принципы организации открытой системы прерываний будут рассмотрены ниже в отдельном разделе, а здесь остановимся на шинной организации информационных потоков, которая берет свое начало с первой модели IBM PC и эволюционирует сегодня. Как Вам известно из курса "Организации ЭВМ", шину микрокомпьютера образует группа линий передачи сигналов с адресной информацией, информацией о передаваемых данных, а также управляющих сигналов. Фактически ее можно разделить на три части: адресную шину, шину данных и шину управления.
Уровни этих сигналов в каждый момент времени определяют состояние всей вычислительной системы в этот момент. Далее мы привяжем обсуждение этих принципов функционирования к конкретной архитектуре ЭВМ, совместимых с IBM PC AT-286 и 386. На рис.2.1 изображено ядро гипотетической вычислительной системы, включающей, например, синхрогенератор i82284, микропроцессор i80286 и математический сопроцессор i80287, а также шинный контроллер i82288.
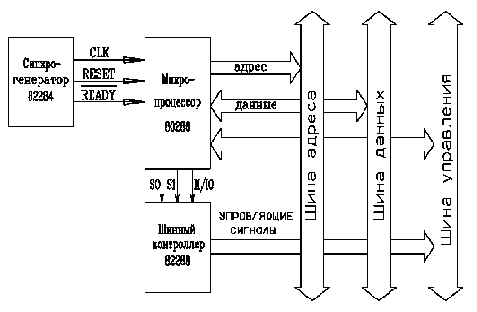
Рис 2.1. Шины компьютера.
Кроме того, показаны три шины: адреса, данных и управляющих сигналов. Синхрогенератор генерирует тактовый сигнал CLK для синхронизации внутреннего функционирования процессора и других микросхем. Сигнал RESET производит сброс процессора в начальное состояние. Сигнал READY, также формируется с помощью синхрогенератора, предназначен для удлинения циклов шины при работе с медленными периферийными устройствами. На адресную шину, состоящую из 24 линий, микропроцессор i80286 выставляет адрес байта или слова, которые будут пересылаться по шине данных в процессор или из него. Кроме того, шина адреса используется микропроцессором для указания адресов (номеров) периферийных портов, с которыми производится обмен данными.
Шина данных состоит из 16 линий, по которым возможна передача как отдельных байтов, так и двухбайтовых слов. При пересылке байтов возможна передача отдельно как по старшим 8 линиям, так и по младшим. Шина данных двунаправленна, т.к. передача байтов и слов может производиться как в микропроцессор, так и из него. Шина управления формируется сигналами, во-первых, поступающими непосредственно от микропроцессора, во-вторых, сигналами, сформированными системным контроллером, и, в-третьих, сигналами, идущими к микропроцессору от других микросхем и периферийных адаптеров. Микропроцессор использует системный контроллер для формирования управляющих сигналов, определяющих правила переноса данных по шине. Он выставляет три сигнала S0, S1, M/IO (выводы 5, 4 и 65), которые определяют тип цикла шины (подтверждение прерывания, чтение порта ввода/вывода, запись в порт ввода/вывода, останов, чтение памяти, запись в память). На основании значений этих сигналов системный контроллер формирует управляющие сигналы, определяющие последовательность процессов данного типа цикла шины.
Для того чтобы понять динамику работы шины, разберем, каким образом процессор осуществляет чтение слова из оперативной памяти. Это происходит в течение четырех тактов CLK (тактовых импульсов на входе 31 микропроцессора), или двух внутренних состояний процессора (т.е. каждое состояние процессора длится 2 такта синхросигнала CLK). Во время первого состояния, обозначаемого как Ts, процессор выставляет на адресную шину значение адреса, по которому будет читаться слово. Кроме того, он формирует на шине совместно с шинным контроллером соответствующие значения управляющих сигналов. Эти сигналы и адрес обрабатываются схемой управления памятью, в результате чего, начиная с середины второго состояния процессора Ts (т.е. в начале четвертого такта CLK) на шине данных появляется значение содержимого соответствующего слова из оперативной памяти. И, наконец, процессор считывает значение этого слова с шины данных. На этом перенос (копирование) значения слова из памяти в процессор заканчивается.
5. Организация системы шин L, S, X и M в компьютере РС/АТ
Следует отметить, что описанная выше система из одной, разбитой на три секции, шины, использовалась лишь в древних ЭВМ класса IBM PC XT. Имея название "Общая шина", она и впрямь пронизывала весь компьютер, позволяя соединить в каждый момент времени процессор с одним из приборов памяти либо одним из контроллеров периферийных устройств. На самом деле в нашем компьютере имеется не одна, а несколько шин (см.рис.2.2). Основных шин четыре, и обозначаются они как L-шина, S-шина, М-шина и X-шина. Нами только что рассматривалась L-шина (или локальная шина), линии адреса и данных которой связаны непосредственно с микропроцессором. Можно ввести понятие удаленности шины от процессора, считая, что чем больше буферов отделяют шину, тем она более удалена от процессора. Тогда L-шина может считаться ближайшей к процессору.
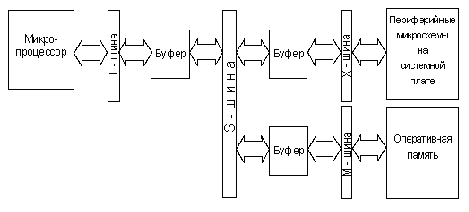
Рис 2.2. Шинная организация IBM PC AT
Основной шиной, связывающей компьютер в единое целое, является S-шина, или системная шина, к которой, кроме того, подключаются адаптеры периферийных устройств, не входящих в состав системного ядра. Именно она выведена на 8 специальных разъемов-слотов. Эти слоты хорошо видны на системной плате компьютера: в них установлены платы периферийных адаптеров (дисплея, флоппи-диска, винчестера, мыши и т.д.).
При переходе с шины L на шину S сигналы процессора должны претерпеть определенную трансформацию. В частности, максимальная нагрузочная способность линий микропроцессора не превышает одного TTL входа, так как максимальный выходной ток этих линий не должен превышать 1мА. Поэтому между линиями L - шины и S - шины должны располагаться буферные элементы, повышающие мощность выводов как минимум в сто раз. Кроме того, шина данных микропроцессора, как мы увидим в дальнейшем, не всегда должны соединяться с остальными частями ЭВМ. При выполнении так называемого внепроцессорного обмена микропроцессор вообще должен быть отключен от остальных схем компьютера.
Защелкивание (этот распространенный в среде инженеров - электронщиков термин обозначает сохранение информации в регистре) кода адреса необходимо по следующей причине. К тому моменту, когда на шинах данных появляется информация, подлежащая перемещению в микропроцессор или из него, должен уже быть подготовлен тракт передачи этой информации от источника к приемнику, проходящий через систему шин и образованный целым набором буферных усилителей и шинных формирователей. Как известно, переключение выводов микросхем из высокоимпедансного состояния в рабочее, а также переключение направления передачи информации требует определенного времени. Кроме того, время затрачивается на дешифрацию элементов, участвующих в данном обмене. Следовательно, адресная информация должна быть выставлена на шину заблаговременно - еще в конце машинного цикла, предшествующего циклу рассматриваемого обмена, и сохраняться в регистре. Кроме того, для максимально возможного увеличения скорости обмена адресная информация, необходимая для дешифрации периферийных микросхем, вообще фиксируется и участвует в подготовке обмена начиная примерно с середины предыдущего цикла. Этот вариант адреса, образующийся на линиях LA(17) - LA(23), и соответствующий адресу обмена в следующем цикле, меняется уже тогда, когда на остальных линиях адреса системной шины еще присутствует информация, соответствующая адресу обмена в текущем цикле.
-
Передача информации в МПС
При организации последовательного обмена ключевыми могут считаться две проблемы:
-
синхронизацию битов передатчика и приемника;
-
фиксацию начала сеанса передачи.
В МПС существует три способа передачи информации:
-
асинхронный
-
синхронный
-
смешанный.
Асинхронный способ характеризуется тем что сигналы передаются с произвольными промежутками времени.
Синхронный способ характеризуется тем что сигналы передаются строго периодично во времени.
Смешанный способ характеризуется тем что байты передаются асинхронно а биты внутри байтов синхронно.
Асинхронный способ
Асинхронный способ обеспечивает передачу информации по единственной линии. Для надежной синхронизации обмена в асинхронном режиме
-
передатчик и приемник настраивают на работу с одинаковой частотой;
-
передатчик формирует стартовый и стоповый биты, отмечающие начало и конец посылки;
-
передача ведется короткими посылками (5..9 бит), а частоты передачи выбираются сравнительно низкими.
Асинхронный способ по методу регистрации сигналов делится на
-
стробируемый
-
«запрос-ответ».
Метод стробирования
Строб - дополнительный сигнал является подтверждением действительности других сигналов.
Стробирование может осуществляться по фронту или по уровню.
Синхронный способ
В синхронном способе передачи информации выделяют изохронный метод.
Синхронизация бывает:
-
внутренняя
-
внешняя
Изохронный метод
В этом методе передачи информации возможна потеря данных. Здесь сам приемник определяет какие данные принимать а какие нет (например для звуковой информации).
Внешняя синхронизация
Сигналы синхронизации поступают вместе с данными. В этом случае форма сигналов может быть неправильной. Поэтому внешняя синхронизация используется только при передаче на небольшие расстояния т.е. внутри платы.
Внутренняя синхронизация
Достоинства:
-
достаточно двух линий сигнал и земля
-
высокая частота
-
высокая надежность связи
-
длина пакета определяется взаимной синхронностью передатчики и приемника.
Синхроимпульсы обеспечивают синхронизацию передаваемых бит, а начало передачи отмечается по-разному.
При организации внешней синхронизации сигнал начала передачи BD генерируется передатчиком и передается на приемник по специальной линии (Рис. 3.6).
В системах с внутренней синхронизацией отсутствует линия BD, а на линию данных генерируются специальные коды длиной 1-2 байта - "символы синхронизации". Для каждого приемника предварительно определяются конкретные синхросимволы, таким образом можно осуществлять адресацию конкретного абонента из нескольких, работающих на одной линии. Каждый приемник постоянно принимает биты с RxD, формирует символы и сравнивает с собственными синхросимволами. При совпадении синхросимволов последующие биты поступают в канал данных приемника.
Асинхронно-синхронный способ
Предположим, что мы умеем преобразовывать каждый байт в поток единиц и нулей, то есть биты, которые могут быть переданы через среду связи (например, телефонную линию). В самом деле, универсальный асинхронный приемопередатчик (UART), как мы увидим ниже, выполняет точно такую же функцию. Обычно, в то время как линия находится в режиме ожидания, для демонстрации того, что линия в порядке, по ней передается единица, обозначая незанятость линии. С другой стороны, когда линия находится в состоянии логического нуля, говорится, что она стоит в режиме выдерживания интервалов. Таким образом, логические единица и ноль рассматриваются соответственно как MARK и SPACE.
В асинхронной связи изменение условия состояния линии с MARK на SPACE означает начало символа. Это называется стартовым битом. За стартовым битом следует комбинация битов, представляющая символ, и затем бит контроля четности. Наконец, линия переходит в состояние ожидания MARK, которая представляет собой стоповый бит и означает конец текущего символа. Число битов, используемых для представления символа, называется длиной слова и обычно бывает равно семи или восьми. Контрольный бит используется для выполнения элементарной проверки на наличие ошибки.
Длительность каждого бита определяется генераторами тактовых импульсов приемника и передатчика. Отметим, однако, что генераторы в приемнике и передатчике должны иметь одну и ту же частоту, но не требуется, чтобы они были синхронизированы. Выбор частоты генератора зависит от скорости передачи в бодах, которая означает число изменений состояния линии каждую секунду. Номинально, тактовая частота "16-кратная скорость передачи в бодах" означает, что линия проверяется достаточно часто для надежного распознавания стартового бита.
Рассмотренные принципы асинхронной последовательной связи реализованы в ряде стандартов для передачи информации, среди которых наиболее популярным является стандарт RS-232С.
7 Принципы работы интерфейса RS-232
В состав PC AT входит оборудование, которое обеспечивает обмен данными между различными устройствами в последовательном коде по асинхронному методу. Это оборудование соответствует требованиям стандарта США RS-232C и рекомендациям V.24 и V.28 международного консультативного комитета по телефонии и телеграфии МККТТ (CCITT). Этим стандартам соответствуют ГОСТ 18145-81 и ГОСТ 23675-79 соответственно.
В дальнейшем будем называть такое оборудование наиболее распространённым термином - интерфейсом RS-232C, или последовательным асинхронным интерфейсом.
Обычно PC имеют в своем составе два интерфейса RS-232C, которые обозначаются COM1 и COM2. Возможна установка дополнительного оборудования, которое обеспечивает функционирование в составе PC четырех, восьми и шестнадцати интерфейсов RS-232C.
Интерфейс RS-232C обеспечивает следующие возможности:
1) применение PC в качестве абонентского пункта в системах и сетях телеобработки данных. В этом случае PC подключается через этот интерфейс к устройствам преобразования сигналов (модемам), которые в свою очередь подключаются к каналам связи;
2) подключение к PC различных устройств ввода-вывода (графопостроителей, принтеров, графических манипуляторов, внешних НГМД, стриммеров и т.д.);
3) объединение нескольких PC между собой и с другими ЭВМ для организации перекачки файлов между ними.
Широкое применение интерфейса RS-232C объясняется его универсальностью в части диапазона скоростей передачи информации (от 50 до 115 000 бит в секунду), "прозрачностью", т.е. отсутствием запрещенных к использованию для передачи данных кодовых комбинаций, наличием специализированных БИС и ИС, на которых достаточно эффективно реализуется данный интерфейс, простотой конструкции соединительных кабелей.
Основные принципы обмена информацией по интерфейсу RS-232C заключаются в следующем:
1) обмен данными обеспечивается по двум цепям, каждая из которых является для одной из сторон передающей, а для другой приемной;
2) в исходном состоянии по каждой из этих цепей передается двоичная единица, т.е. стоповая посылка. Передача стоповой посылки может выполняться сколько угодно долго;
3) передаче каждого знака данных предшествует передача стартовой посылки, т.е. передача двоичного нуля в течение времени, равного времени передачи одного бита данных;
4) после передачи стартовой посылки обеспечивается последовательная передача всех разрядов знака данных, начиная с младшего разряда. Количество разрядов знака может быть 5, 6, 7 или 8;
5) после передачи последнего разряда знака данных возможна передача контрольного разряда, который дополняет сумму по модулю 2 переданных разрядов до четности или нечетности. В некоторых системах передача контрольного разряда не выполняется;
6) после передачи контрольного разряда или последнего разряда знака, если формирование контрольного разряда не предусмотрено, обеспечивается передача стоповой посылки. Минимальная длительность посылки может быть равной длительности передачи одного, полутора или двух бит данных.
Обмен данными по описанным выше принципам требует предварительного согласования приемника и передатчика по количеству используемых разрядов в символе, правилам формирования контрольного разряда и длительности передачи бита данных.
Последнее согласование обеспечивается путем стандартизации ряда скоростей: 50, 75, 100, 110, 200, 300, 600, 1200, 2400, 4800, 9600, 19 200, 38 400, 57 000 или 115 000 бит в секунду. Установленная скорость должна отличаться от номинальной не более чем на 2 %, что гарантированно обеспечивается применением генераторов с кварцевыми резонаторами.
Обычно используется генератор с частотой 1,8432 МГц.
-
Методы ввода/вывода и их классификация
Подсистема ввода/вывода (ПВВ) обеспечивает связь МП с внешними устройствами, к которым будем относить:
-
устройства ввода/вывода (УВВ): клавиатура, дисплей, принтер, датчики и исполнительные механизмы, АЦП, ЦАП, таймеры и т.п.
-
внешние запоминающие устройства (ВЗУ): накопители на магнитных дисках, "электронные диски" и др.
В рамках рассмотрения ПВВ будем полагать термины "УВВ" и "ВУ" синонимами, т.к. обращение к ним со стороны процессора осуществляется по одним законам.
ПВВ в общем случае должна обеспечивать выполнение следующих функций:
-
согласование форматов данных, т.к. процессор всегда выдает/принимает данные в параллельной форме, а некоторые ВУ (например, НМД) - в последовательной. С этой точки зрения различают устройства параллельного и последовательного обмена. В рамках параллельного обмена не производится преобразование форматов передаваемых слов, в то время как при последовательном обмене осуществляется преобразования параллельного кода в последовательный и наоборот. Все варианты, когда длина слова ВУ (больше 1 бита) не совпадает с длиной слова МП, сводятся к разновидностям параллельного обмена;
-
организация режима обмена - формирование и прием управляющих сигналов, идентифицирующих наличие информации на различных шинах, ее тип, состояние ВУ (Готово, Занято, Авария), регламентирующих временные параметры обмена. По способу связи процессора и ВУ (активного и пассивного) различают синхронный и асинхронный обмен. При синхронном обмене временные характеристики обмена полностью определяются МП, который не анализирует готовность ВУ к обмену и фактическое время завершения обмена. Синхронный обмен возможен только с устройствами, всегда готовыми к нему (например, двоичная индикация). При асинхронном обмене МП анализирует состояние ВУ и/или момент завершения обмена. Временные характеристики обмена в этом случае могут определяться ВУ;
-
адресную селекцию внешнего устройства.
Классификация методов ввода/вывода
-
Под управлением ЦП.
-
По опросу
-
По прерыванию
-
Под управлением внешних устройств (прямого доступа к памяти).
Метод по опросу подразумевает регулярную проверку процессором готовности к ответу.
Недостатки:
быстродействие очень низкое;
-
процессор занимается постоянным опросом.
Достоинства:
-
не требует дополнительной аппаратуры;
-
можно использовать несколько источников.
Необходимо чтобы процессор и устройства были согласованны по скорости. Эффективность низка если информация поступает редко (процессор опрашивает а информации нет).
9. Подсистема прерываний МПС
Подсистема прерываний - совокупность аппаратных и программных средств, обеспечивающих реакцию программы на события, происходящие вне программы. Такие события возникают, как правило, случайно и асинхронно по отношению к программе и требуют прекращения (чаще временного) выполнения текущей программы и переход на выполнение другой программы (подпрограммы), соответствующей возникшему событию.
Внутренние и внешние прерывания
Различают внутренние и внешние (по отношению к процессору) события, требующие реакции подсистемы прерываний. К внутренним событиям относятся переполнение разрядной сетки при выполнении арифметических операций, попытка деления на 0, извлечение корня четной степени из отрицательного числа и т.п., появление несуществующего кода команды, обращение программы в область памяти, для нее не предназначенную, сбой при выполнении передачи или операции в АЛУ и многое другое. Внутренние прерывания должны обеспечиваться развитой системой аппаратного контроля процессора, поэтому они не получили широкого распространения в простых 8- и 16-разрядных МП.
Внешние прерывания могут возникать во внешней по отношению к процессору среде и отмечать как аварийные ситуации (кончилась бумага на принтере, температура в реакторе превысила допустимый уровень, исполнительный орган робота дошел до предельного положения и т.п.), так и нормальные рабочие события, которые происходят в случайные моменты времени (нажатие клавиши на клавиатуре, исчерпан буфер принтера или ВЗУ и т.п.). Во всех этих случаях требуется прервать выполнение текущей программы и перейти на выполнение другой программы (подпрограммы), обслуживающей это событие.
С точки зрения реализации внутренние и внешние прерывания функционируют одинаковым образом, хотя при работе подсистемы с внешними прерываниями возникают дополнительные проблемы идентификации источника прерывания. Поэтому ниже будут рассмотрены внешние прерывания.
Анализ состояния внешней среды можно осуществлять путем программного сканирования - считывания через определенные промежутки времени слов состояния всех возможных источников прерываний, выделения признаков отслеживаемых событий и переход (при необходимости) на прерывающую подпрограмму.
Однако, такой способ не обеспечивает для большинства применений приемлемого времени реакции системы на события, особенно при необходимости отслеживания большого числа событий. К тому же при коротком цикле сканирования большой процент процессорного времени тратится на проверку (чаще безрезультатную) состояния внешней среды.
Гораздо эффективней организовать взаимодействие с внешней средой таким образом, чтобы всякое изменение состояния среды, требующее реакции МПС, вызывало появление на специальном входе МП сигнала прерывания текущей программы. Организация прерываний должна быть обеспечена определенными аппаратными и программными средствами, которые мы и называем "подсистемой прерываний".
Функции подсистемы прерываний и их реализация
Подсистема прерываний должна обеспечивать выполнение следующих функций:
-
обнаружение изменения состояния внешней среды (запрос на прерывание);
-
идентификация источника прерывания;
-
разрешение конфликтной ситуации в случае одновременного возникновения нескольких запросов (приоритет запросов);
-
определение возможности прерывания текущей программы (приоритет программ);
-
фиксация состояния прерываемой (текущей) программы;
-
переход к программе, соответствующей обслуживаемому прерыванию;
-
возврат к прерванной программе после окончания работы прерывающей программы.
Рассмотрим варианты реализации в МПС перечисленных выше функций.
(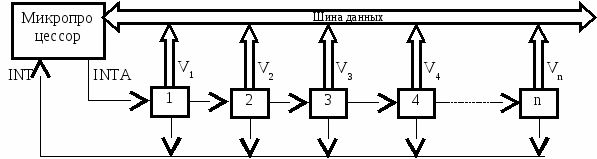
1) Фиксация изменения состояния внешней среды может осуществляться различными средствами: двоичными датчиками, компараторами, схемами формирования состояний и т.п. Будем полагать, что все эти средства формируют в конечном итоге логические сигналы запроса на прерывание z, причем для определенности будем считать, что активное состояние этого сигнала передается уровнем логической единицы (H - уровень).
Количество источников запросов в МПС может быть различно, в том числе и довольно велико. Дефицит внешних выводов МП исключает возможность передачи запросов от ВУ по "собственным" линиям интерфейса. Обычно на одну линию запроса подключается несколько источников прерываний (по функции ИЛИ), а иногда и все источники системы - на единственный вход (как в i8080).
Рис. 5.3. Организация векторного прерывания
Различают два типа входов запросов на прерывания - радиальные и векторные. Процессор анализирует состояние входов запросов в конце каждого машинного цикла.
(2) Получив запрос на прерывание, процессор должен идентифицировать его источник, т.е. в конечном счете, определить начальный адрес обслуживающей это прерывание программы. Способ идентификации зависит от типа входа, на который поступил запрос.
Каждый радиальный вход связан с определенным адресом памяти, по которому размещается указатель на обслуживающую программу или сама программа. Если на радиальный вход поступает несколько запросов, то необходимо осуществить программную идентификацию источника путем последовательного (в порядке убывания приоритетов) опроса всех возможных источников прерывания. Этот способ не требует дополнительных аппаратных затрат и одновременно решает проблему приоритета запросов (3), однако время реакции системы на запрос может оказаться недопустимо велико, особенно при большом числе источников прерываний.
Гораздо чаще в современных МПС используется т.н. "векторная" подсистема прерываний (Рис. 5.1). В такой системе микропроцессор, получив запрос на векторном входе INT, выдает на свою выходную линию сигнал подтверждения прерывания INTA, поступающий на все возможные источники прерывания. Источник, не выставивший запроса, никак не реагирует на сигнал INTA. Источник, выставивший запрос, получая сигнал INTA, выдает на системную шину данных "вектор прерывания" - свой номер или адрес обслуживающей программы или, чаще, адрес памяти, по которому расположен указатель на обслуживающую программу. Время реакции МПС на запрос векторного прерывания минимально (1..3 машинных цикла) и не зависит от числа источников.
(3) Для исключения конфликтов при одновременном возникновении нескольких запросов на векторном входе ответный сигнал INTA подается на источники запросов не параллельно, а последовательно - в порядке убывания приоритетов запросов. Источник, не выставлявший запроса, транслирует сигнал INTA со своего входа на выход, а источник, выставивший запрос, блокирует дальнейшее распространение сигнала INTA. Таким образом, только один источник, выставивший запрос, получит от процессора сигнал INTA и выдаст по нему свой вектор на шину данных.
Более гибко решается проблема организации приоритетов запросов при использовании в МПС специальных контроллеров прерываний (см. ниже).
Конфликты на радиальном входе исключаются самим порядком программного опроса источников.
(4) Прерывание в общем случае может возникать не только при решении "фоновой" задачи, но и в момент работы другой прерывающей программы, причем не всякую прерывающую программу допустимо прерывать любым запросом. В фоновой задаче так же могут встречаться участки, при работе которых прерывания (все или некоторые) недопустимы. В общем случае в каждый момент времени работы процессора должно быть выделено подмножество запросов, которым разрешено прерывать текущую программу.
В МПС эта задача решается на нескольких уровнях. В процессоре обычно предусматривается программно-доступный флаг разрешения/запрещения прерывания, значение которого определяет возможность или невозможность всех прерываний. Для создания более гибкой системы приоритетов программ на каждом источнике прерываний может быть предусмотрен специальный программно-доступный триггер разрешения формирования запроса. В таком случае возможно формирование произвольного подмножества разрешенных в данный момент источников прерываний.
В МП: машинный такт - машинный цикл - командный цикл. Рассмотрим возможность прерывания программы по окончанию различных процессов. Учитывая, что прерванная программа должна быть запущена по окончании работы прерывающей с того места, где она была прервана, подсистема прерываний МПС должна обеспечить фиксацию полного состояния прерываемой программы на момент прерывания.
При прерывании после текущего машинного такта требуется запоминать не только состояние всех регистров процессора (программно-доступных и системных), но и состояние первичного управляющего автомата. Реализация процедуры фиксации состояния и последующего восстановления потребует значительных затрат дополнительного оборудования и/или времени.
Значительный объем информации требуется запоминать и при прерывании программы после текущего машинного цикла (выбранный фрагмент или всю команду, выбранные операнды или сформированные адреса).
Поэтому в большинстве МП прерывание может осуществляться после выполнения очередной команды. Состояние программы в этом случае характеризуется содержимым счетчика команд (адрес следующей команды), а так же содержимым РОН и регистра флагов. Процедура перехода к прерывающей программе и последующего возврата из нее может быть полностью идентична действиям, выполняемым по командам ВЫЗОВ и ВОЗВРАТ. Состояние программного счетчика (а иногда и регистра флагов или PSW) аппаратно фиксируется в стеке, а значение РОНов - при необходимости программно в самом тексте прерывающей программы. Учитывая, что большинство команд МП являются короткими, время реакции МПС на запрос прерывания при анализе запросов по завершению текущего командного цикла не бывает большим.
10 .Контроллер приоритетов прерываний
Внешние устройства, включенные в подсистему прерываний, должны реализовать несколько функций, связанных с работой в этой подсистеме - формирование запроса, анализ ответа процессора, выдачу вектора прерывания. Кроме того, в подсистеме необходимо обеспечить дисциплину обслуживания запросов. Перечисленные функции могут быть реализованы на специальных устройствах - контроллерах прерываний, которые выпускаются в виде БИС в составе многих микропроцессорных комплектов.
Параллельный арбитраж осуществляется с помощью специального устройства-арбитра (в этом случае используется КПП).
Основные функции КПДП:
-
получить запросы прерываний от устройств и сформировать сигнал запроса прерывания на входе МП.
-
установка и смена приоритетов при одновременном поступлении запросов
-
маскирования запросов по команде процессора
-
сообщить МП начальный адрес подпрограммы обслуживания прерываний в соответствии с тем, какой запрос будет удовлетворен.
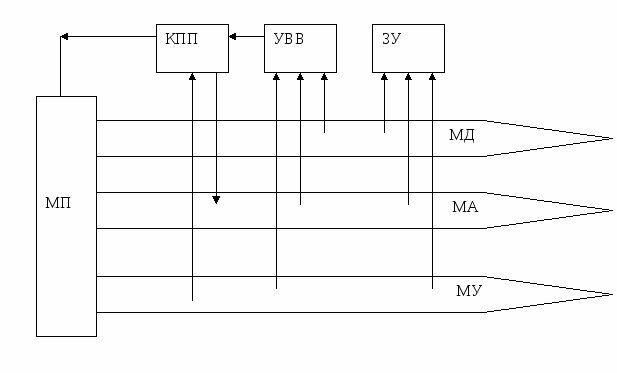
Взаимодействие МП с КПП осуществляется с помощью сигналов запроса прерываний от КПП и подтверждения прерывания по МУ. При поступлении запроса прерывания от УВВ КПП, в случае если запрос не маскирован, выдает сигнал запроса прерывания основной программы на МП. МП завершает выполнение текущей команды, в стеке запоминается адрес возврата в подпрограмму. Сигналом подтверждения прерывания по МУ запрашивается вектор прерывания от КПП. КПП выставляет на МД адрес подпрограммы обслуживания прерывания или вектор прерывания (информация по которой можно найти адрес начала подпрограммы обслуживания устройства). После сообщения МП вектора прерывания снимается запрос прерывания от КПП, выполняется подпрограмма обслуживания, снимается сигнал запроса от УВВ.
-
Подсистема прямого доступа в память МПС. Контроллер прямого доступа памяти (КПДП)
КПДП служит для организации обмена данных между устройствами минуя процессор. Контроллер используется в МПС если необходимо переслать большой объем информации. Его применение увеличивает быстродействие обмена информации.
Функции КПДП:
-
получение запросов на режим ПДП от УВВ
-
формирование сигнала запроса захвата магистрали на входе МП
-
информирование МП о завершении обмена
-
определение приоритета устройств в случае поступления одновременно нескольких запросов и информирование выбранного устройства о начале обмена
-
задания необходимого числа обращений к устройству.
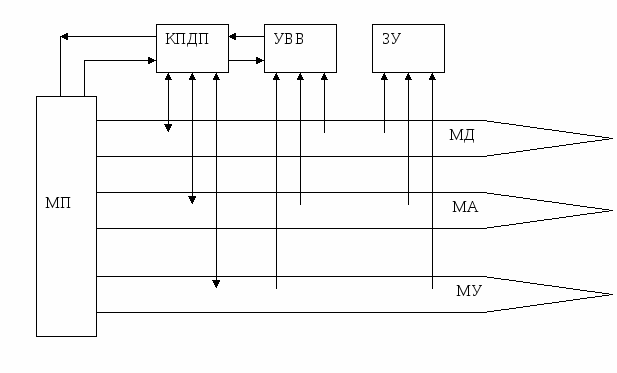
Обмен данными между устройствами с использованием ПДП: устройство ввода и память; между памятью и устройством вывода; между двумя областями памяти.
Принцип работы КПДП. МП с КПДП взаимодействует при помощи сигналов запроса захвата магистрали МП и сигнала подтверждения захвата магистрали.
Получив сигнал запроса от устройства, КПДП выдает процессору сигнал запроса захвата. Процессор заканчивает текущую команду, отключается от магистралей (Кеш память) и формирует сигнал подтверждения захвата магистрали. Получив магистраль КПДП определяет устройство, запрос которого имеет наивысший приоритет и выдает ему сигнал подтверждающий прием информации от устройства. За время выдачи этого сигнала производится одно обращение к магистралям. КПДП будет повторять обращение до тех пор, пока устройство не снимет запрос обмена. КПДП заканчивает обращение, отключается от магистрали, информирует об этом МП сигналом запроса захвата и его снятием. МП подключается к магистралям и продолжает работу.
-
Подсистема памяти МПС
Распределение адресного пространства
Объем адресного пространства МПС с интерфейсом "Общая шина" определяется главным образом разрядностью шины адреса и, кроме того, номенклатурой управляющих сигналов интерфейса. Управляющие сигналы могут определять тип объекта, к которому производится обращение (ОЗУ, ВУ, стек, специализированные ПЗУ и др.). В случае, если МП не выдает сигналов, идентифицирующих пассивное устройство (или они не используются в МПС), - для селекции используются только адресные линии. Число адресуемых объектов составляет в этом случае 2k, где k - разрядность шины адреса. Будем называть такое адресное пространство "единым". Иногда говорят, что ВУ в едином адресном пространстве "отображены на память", т.е. адреса ВУ занимают адреса ячеек памяти. Пример организации селекции устройств в едином адресном пространстве МПС на базе i8080 и распределение адресного пространства показаны на Рис. 7.1 и Рис. 7.2 соответственно.
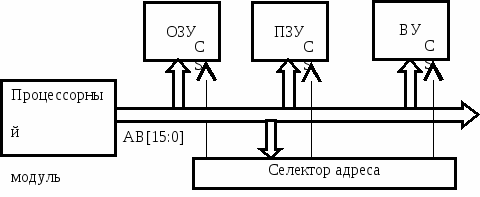
Рис. 7.4. Структура единого адресного пространства
-
0000 0FFF
1000 FEFF
FF00 FFFF
ПЗУ
4К
ОЗУ
до 59,75К
ВУ
0,25К
Рис. 7.5. Пример распределения единого адресного пространства
При небольших объемах памяти в МПС целесообразно использовать некоторые адресные линии непосредственно в качестве селектирующих (Рис. 7.3), что позволяет уменьшить объем оборудования МПС за счет исключения селектора адреса. При этом, однако, адресное пространство используется крайне неэффективно.
При использовании информации о типе устройства, к которому идет обращение, можно одни и те же адреса назначать для разных устройств, осуществляя селекцию с помощью управляющих сигналов.
Так, большинство МП выдают в той или иной форме информацию о типе обращения. В результате в большинстве интерфейсов присутствуют отдельные управляющие линии для обращения к памяти и вводу/ выводу, реже - стеку или специализированному ПЗУ. В результате суммарный объем адресного пространства МПС может превышать величину 2k.
Диспетчер памяти
При необходимости расширить объем памяти за пределы адресного пространства можно воспользоваться т.н. "диспетчером памяти". В простейшем случае он представляет собой программно-доступный регистр, который должен располагаться в пространстве ввода/вывода. В него заносится номер активного в данный момент банка памяти, причем объем банка может равняться объему адресного пространства МП (2k).
Очевидно, в каждый момент времени процессору доступен только один банк. При необходимости перехода в другой банк памяти МП должен предварительно выполнить программную процедуру (часто всего одну команду) перезагрузки содержимого номера банка. Сказанное иллюстрируется Рис. 7.44. К развитию этой идеи можно отнести механизм сегментации памяти в 16- и 32-разрядных МП фирмы INTEL.
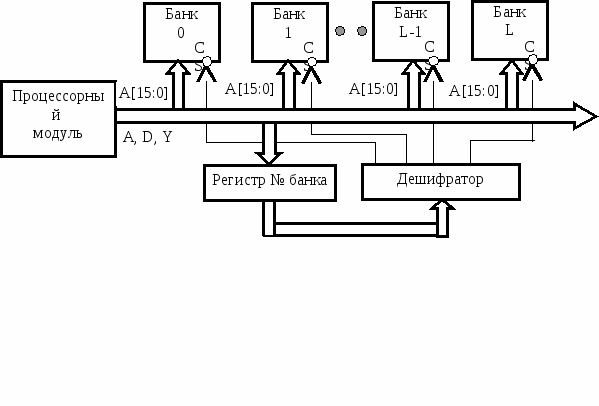
Рис. 7.4. Использование диспетчера памяти
Запоминающие устройства
Память может быть внутренней и внешней. Внешней называют память на магнитных, оптических дисках, лентах и т.п. Внутренняя память выполняется, чаще всего, на микросхемах. Внутренняя или основная память может быть двух типов: оперативное запоминающее устройство (ОЗУ) или ЗУ с произвольной выборкой (ЗУПВ) и постоянное ЗУ (ПЗУ). ОЗУ, кроме того, обозначается - (RAM, Random Access Memory), а ПЗУ - (ROM, Read Only Memory). Получила также распространение Флэш(Flash) память, имеющая особенности и ОЗУ и ПЗУ и энергонезависимая память (Nonvolatile - NV) на батарейках. Последнее название условно, так как ПЗУ и Флэш память, также энергонезависимы. В ОЗУ коды в соответствии с решаемыми задачами постоянно изменяются и полностью пропадают при выключении питания. В ПЗУ хранятся управляющие работой ЭВМ стандартные программы, константы, таблицы символов и другая информация, которая сохраняется и при выключении компъютера. ОЗУ подразделяются на статическую память (SRAM), динамическую (DRAM), регистровую (RG). ПЗУ могут быть: масочными - запрограммированными на заводе изготовителе (ROM), однократно-программируемыми пользователем ППЗУ (PROM или OTP), многократно-программируемыми (репрограммируемыми) пользователем РПЗУ с ультрафиолетовым стиранием (EPROM) или c электрическим стиранием (EEPROM). Широкое распространение нашли также программируемые логические матрицы и устройства (PLM, PML, PLA, PAL, PLD, FPGA и т.д.) с большим выбором логических элементов и устройств на одном кристалле.
В зависимости от типа ЗУ элементом памяти (ЭП) может быть: триггер, миниатюрный конденсатор, транзистор с "плавающим затвором", плавкая перемычка (или ее отсутствие). Упорядоченный набор ЭП образует ячейку памяти (ЯП) . Количество элементов памяти в ячейке (длина слова) обычно кратно 2n (1,4,8,16, 32,64..), причем величины свыше 8-ми достигаются, обычно, группировкой микросхем с меньшим количеством ЭП. Количество ЭП в ЯП иногда называется длиной слова. Основными характеристиками микросхем памяти являются: информационная емкость, быстродействие и энергопотребление. Емкость ЗУ чаще всего выражается в единицах кратных числу 210 = 1024 = 1K. Для длины слова равной биту (одному двоичному разряду) или байту (набору из восьми бит) эта единица называется килобит или килобайт и обозначается Kb или KB.
Каждой из двух в степени "n" ячеек памяти однозначно соответствует "n"- разрядное двоичное число, называемое адресом ЯП. Например, адресом 511-ой ячейки будет число 1 1111 1111(BIN) = 511(DEC) = 1FF(HEX). В программах адреса употребляются в 16-ном формате. Емкость ЗУ часто выражается произведением двух чисел 2n * m, где 2n - число ячеек памяти, а m - длина слова ячейки, например 8K * 8 (м/с 537РУ17), т.е. 8192 ячейки размером в один байт. В некоторых справочниках для этой же микросхемы приводится обозначение емкости одной цифрой 64Kбит, что никак не отражает внутреннюю организацию этой микросхемы, такую же емкость могут иметь м/с с организацией 16K * 4, 64K * 1 и т.д.
-
PCI Высокоскоростной интерфейс
Высокоскоростной интерфейс : 32-64 разрядный с мультиплексированной ША данных.
Назначение :
Универсальный интерфейс (соединение процессора с периферийными элементами и системой процессора памяти). Имеется встроенная поддержка кэширования (механизм слежения за шиной - интерференция данных).
Скорость : 33,66,133 МГц.
Пересылки : 32 и 64 бит , следовательно ширина ШД : 4-8 байт
Групповые пересылки разрешаются (Burst) . Реализован скрытый арбитраж : арбитраж осуществляется в то время когда на шину идут пересылки (время не тратится). Низкая стоимость , определяется малым числом выводов (49 для "мастер" и 47 для Slave). Простота использования : реализована функция авто конфигурирования системы. Высокая надёжность : при пересылки осуществляется контроль чёткости адреса данных.
Основные циклы
1.Чтение (система с изолированной шиной и каждое устр-во имеет свой дешифратор адреса)
а) позитивная дешифрация (устр-во опознаёт свой собственный диапазон адресов)
б) вычитательная дешифрация (на шине 1 устр-во , которое отвечает за все остальные не заполненные адреса) .
PCI : Реализованный синхронный алгоритм обмена синхронного сигнала - даёт преимущество в быстродействии
Такт 1 : инициатор (мастер шины выставляет сигнал FRAME , который говорит ,что шина захвачена и выставлен сигнал IRDy ,следовательно устройство (мастер ) готово к обмену.
Такт 2 : к моменту выставления фронта ,мастер выставляет команду WRITE и адрес ADDRESS ,по которому осуществляется обращение .
Такт 3 : в промежутке между тактом 2 и тактом 3 3slave определяет , что обращение осуществлено к нему и выставлен знак DEVSEV и TRDY.
Такт 3 : активное устр-во выставляет данные на ШД и выставляет сигнал Byte Enables, который подтверждает каждый из передаваемых байтов (читает первую порцию данных адресованное устр-ву D1).
Такт 4: Slave не готов к обмену и выставляет сигнал TRDY и активное устр-во данные ен передаёт .
Такт 5 : Мастер не готов и выставляет сигнал об этом и Slave не принимает данные. Т5 -Т6 : оба устр-ва готовы к обмену и мастер выставляет порцию данных и Byte Enables Т7: цикл завершается: выставляет одновременно пару сигналов в IRDY =1 и FRAME=1 - цикл завешен.
Арбитраж: скрытый в PCI : совмещённый реальный арбитраж с работой др. устр-в . У каждого устр-ва сигналы REQ , GNT свои.
Активное устр-во выдаёт сигнал REQ на арбитр по своей линии . Арбитр определяет какое устр- во имеет наиболее высокий приоритет и по линии выдаёт сигнал GNT этому устр-ву. Активное устр-во выставляет сигнал FRAME ,что устр-во захвачено и осуществляет обмен.
Особенности :
1) Групповая пересылка
2) Встроенная поддержка кэширования
Неудобства - существование мостов и необходимость реализовать сопрягающее устройство .
-
Микропроцессоры и микроконтроллеры
Как известно, процессор является основным вычислительным блоком компьютера, в наибольшей степени определяющим его мощь. Процессор является устройством, исполняющим программу - последовательность команд (инструкций), задуманную программистом и оформленную в виде модуля программного кода. Чтобы понять, что делает процессор, рассмотрим его в окружении системных компонентов IBM PC-совместимого компьютера. Этой компьютерной архитектурой, естественно, не ограничивается сфера применения процессоров. Всем известный IBM PC-совместимый компьютер представляет собой реализацию так называемой фон-неймановской архитектуры вычислительных машин. Эта архитектура имеет следующие основные признаки. Машина состоит из блока управления, арифметико-логического устройства (АЛУ), памяти и устройств ввода/вывода. В ней реализуется концепция хранимой программы: программы и данные хранятся в одной и той же памяти. Выполняемые действия определяются блоком управления и АЛУ, которые вместе являются основой центрального процессора. Центральный процессор выбирает и исполняет команды из памяти последовательно, адрес очередной команды задается "счетчиком адреса" в блоке управления. Этот принцип исполнения называется последовательной передачей управления. Данные, с которыми работает программа, могут включать переменные - именованные области памяти, в которых сохраняются значения с целью дальнейшего использования в программе. Фон-неймановская архитектура - не единственный вариант построения ЭВМ, есть и другие, которые не соответствуют указанным принципам (например, потоковые машины). Однако подавляющее большинство современных компьютеров основано именно на этих принципах, включая и сложные многопроцессорные комплексы, которые можно рассматривать как объединение фон-неймановских машин. Конечно же, за более чем полувековую историю ЭВМ классическая архитектура прошла длинный путь развития. В общем смысле под архитектурой процессора понимается его программная модель, то есть программно-видимые свойства. Под микроархитектурой понимается внутренняя реализация этой программной модели. Для одной и той же архитектуры разными фирмами и в разных поколениях применяются существенно различные микроархитектурные реализации, при этом, естественно, стремятся к максимальному повышению производительности (скорости исполнения программ). Сейчас существует множество архитектур процессоров, которые делятся на две глобальные категории - RISC и CISC. RISC - Reduced (Restricted) Instruction Set Computer - процессоры (компьютеры) с сокращенной системой команд. Эти процессоры обычно имеют набор однородных регистров универсального назначения, причем их число может быть большим. Система команд отличается относительной простотой, коды инструкций имеют четкую структуру, как правило, с фиксированной длиной. В результате аппаратная реализация такой архитектуры позволяет с небольшими затратами декодировать и выполнять эти инструкции за минимальное (в пределе 1) число тактов синхронизации. Определенные преимущества дает и унификация регистров. CISC - Complete Instruction Set Computer - процессоры (компьютеры) с полным набором инструкций, к которым относится и семейство х86. Состав и назначение их регистров существенно неоднородны, широкий набор команд усложняет декодирование инструкций, на что расходуются аппаратные ресурсы. Возрастает число тактов, необходимое для выполнения инструкций. Процессоры х86 имеют самую сложную в мире систему команд. Хорошо ли это, вопрос спорный, но груз совместимости с программным обеспечением для IBM PC, имеющим уже 20-летнюю историю, не позволяет расставаться с этим "наследием тяжелого прошлого". В процессорах семейства х86, начиная с 486, применяется комбинированная архитектура - CISC-процессор имеет RISC-ядро. Различают следующие способы организации вычислительного процесса:
-
один поток команд - один поток данных (Simple Instruction - Simple Data, SISD) - характерно для традиционной фон-неймановской архитектуры (иногда вместо Simple пишут Single);
-
один поток команд - множественный поток данных (Simple Instruction - Multiple Data, SIMD) - технология MMX;
-
множественный поток команд - один поток данных (Multiple Instruction - Simple Data, MISD);
-
множественный поток команд - множественный поток данных (Multiple Instruction - Multiple Data, MIMD).
Микроконтроллер - вычислительно-управляющее устройство, предназначенное для выполнения функций контроля и управления периферийным оборудованием.
Уклон в сторону управления накладывает отпечаток на особенность архитектуры микроконтроллеров. Основной из этих особенностей является то, что наряду с процессорным ядром микроконтроллера имеют в своём составе подсистему ввода-вывода и, возможно, подсистему памяти. В последнем случае принято говорить об однокристальных микро-ЭВМ.
Рассмотрим особенности организации каждой из подсистем микроконтроллеров.
Процессорное ядро
Современные микроконтроллеры могут быть построены как по Гарвардской (MCS-51 Intel), так и по Фон Неймановской архитектуре (MCS-96 Intel, 80C166 Siemens). Все они имеют внешнюю системную магистраль для обмена данными с внешней памятью и дополнительными периферийными устройствами. Классические семейства микроконтроллеров (MCS-51) имеют, как правило, мультиплексные шины адреса/данных, что было обусловлено необходимостью минимизировать размер микросхемы. Однако современные быстродействующие микроконтроллеры используют уже демультиплексную шину, что ускоряет работу системы. Некоторые модели микроконтроллеров имеют возможность работать либо мультиплексной либо с демультиплексной шиной, в зависимости от требуемой конфигурации системы. В случае демультиплексной шины контроллер быстрее обменивается данными по магистрали. При работе с мультиплексной шиной, освободившиеся выводы используются как порты ввода-вывода. (MCS251 Intel, 80C166 Siemens).
Практически все микроконтроллеры выполняют только операции с фиксированной точкой. Существуют 8-разрядные (MCS-51 Intel, MC6805 Motorola),16-разрядные (MCS-96 Intel, 80C166 Siemens, MC6816 Motorola),32-разрядные(MC683 Motorola, MPC500 PowerPc) микроконтроллеры. Системы команд микроконтроллеров поддерживает, как правило, широкий набор методов адресации в т.ч. бытовую адресацию.
Подсистема памяти.
Существуют микроконтроллеры с аккумуляторной (MCS-51) и регистровой (MCS-96) организацией. Количество регистров и их разрядность зависит от конкретной модели. Зачастую микроконтроллеры имеют несколько банков регистров (MCS-48, MCS-51, 80C166).
Память данных определенного объема присутствует на простом микроконтроллере практически всегда. Она обменивается данными с процессорным ядром по внутренней магистрали микроконтроллера, которая может быть организована иначе, чем внешняя. Поэтому обмен данными с внутренней памятью данных, как правило, осуществляется быстрее, чем с внешней.
Варианты реализации внутренней памяти программ могут быть различными:
-
она может отсутствовать. В этом случае микроконтроллер выполняет программу, считывая команды из внешней памяти программ через системную магистраль.
-
Она может быть выполнена в виде масочного ПЗУ. В этом случае микроконтроллер не нуждается во внешней памяти программ. Однако в этом случае программа во внутреннюю память записывается однократно на этапе изготовления кристалла и не может быть изменена в дальнейшем. Как правило, программа, записанная во внутреннюю память, выполняется быстрее, чем из внешней памяти.
-
Она может быть выполнена в виде однократно программируемого ППЗУ. В этом случае пользователь сам может записать программу во внутреннюю память, но лишь однажды. Для записи программы, как правило, необходим специальный программатор. Однако существуют микроконтроллеры, способные программировать сами себя (MCS-96) (программатор реализован внутри кристалла).
-
Она может быть выполнена в виде ППЗУ с УФ стиранием. В этом случае память программ может быть многократно перепрограммирована с помощью программатора. Перед очередным программированием она должна быть очищена с помощью УФ излучения.
-
Она может быть выполнена в виде Flash - памяти. В этом случае память программ может быть многократно перепрограммирована в процессе работы системы.
-
Она может быть реализована в виде ОЗУ. В этом случае для загрузки программы после включения питания используется так называемый Boot Strep загрузчик. Это механизм, позволяющий после включения питание загрузить начальную программу функционирования по последовательному каналу связи, либо по системной магистрали.
Подсистема ввода-вывода.
Подсистем ввода-вывода состоит из набора разнообразных устройств, выполняющих специфические функции управления и контроля. К их числу наиболее часто относятся:
Порты ввода-вывода. Они могут быть либо однонаправленными ( выполняя функции входа или выхода соответственно), либо квази-двунаправленными. Такие порты могут выполнять функции как входа, так и выхода (в каждый конкретный момент времени либо вход, либо выход).
-
Цифровая обработка сигналов DSP (digital signal processor)
Особенности DSP
DSP представляют собой специализированные процессоры для приложений, требующих интенсивных вычислений.
Если ближе рассмотреть, к примеру, процесс операции умножения двух чисел с сохранением результата в традиционных микропроцессорах, то можно увидеть как расходуется машинное время: сначала происходит выборка команды (адрес команды выставляется на шину адреса), затем первого операнда (адрес операнда выставляется на шину адреса), затем операнд переносится в аккумулятор, далее происходит выборка второго операнда и т.д. Ускорение этого процесса в процессоре общего назначения невозможна из-за наличия единственной шины адреса и единственной шины данных, а также единственного банка данных. Ввиду этого все операции по извлечению операндов из памяти, выборки команды и сохранения операнда производится последовательно с использованием одной и той же шины данных и шины адреса. Кроме того, если рассмотреть операцию циклического суммирования арифметического ряда, то можно видеть что здесь непроизводительные затраты времени связаны с запоминанием адреса первой команды цикла, с проверкой условия цикла (счетчика) и возвратом к первой команде. Также большие непроизводительные затраты существуют при операциях перехода к подпрограмме и возврата (запись и восстановление значений регистров из стека) и при многих других операциях. Если при этом учесть огромное количество математических операций при выполнении цифровой обработки сигналов, то станет ясно, что неизбежны весьма чувствительные потери в точности вычисления при округлениях, которые не могут не сказаться на общем результате. Это происходит по причине одинаковой разрядности всех регистров процессоров общего назначения.
При цифровой обработке сигналов все эти затраты недопустимы. С целью преодоления этого недостатка процессоров общего назначения и были разработаны процессоры цифровых сигналов (DSP - Digital Signal Processor).
Трехшинная Гарвардская архитектура
Ее особенность состоит прежде всего в том, что в отличии от привычных нам двух шин: шины адреса и шины данных, а также одного банка памяти, DSP имеет как минимум 6-7 различных шин и 2-3 банка памяти. Эта особенность имеет своей целью максимально ускорить выполнение операции умножения с сохранением результата, которая, несомненно, является наиболее употребляемой и ресурсоемкой при цифровой обработке сигналов. Архитектура DSP позволяет за один машинный цикл произвести:
-
выборку команды посредством шины адреса программ и шины данных программ;
-
выборку двух операндов для операции умножения посредством двух шин адреса данных;
-
занесение операндов в аккумуляторы посредством двух шин данных;
-
операцию умножения;
-
сохранить результат в аккумуляторе.
Таким образом, трехшинная Гарвардская архитектура позволяет выполнить практически любую операцию за один машинный цикл.
B качестве примера эффективности использования DSP при реализации алгоритмов цифровой обработки сигналов можно привести следующий факт: время выполнения комплексного 1024-точечного преобразования Фурье составляет 20 мс для 486DX2 66 МГц (32-разрядный) и 3.23 mc для 24-разрядного 33 МГц DSP56001 фирмы Motorola или 3.1 мс для 32- разрядного 33 МГц DSP TMS320C30 с плавающей арифметикой фирмы Texas Instruments.
Однако, как уже упоминалось, процессоры цифровой обработки сигнала имеют отличием не только высокую производительность, измеряемую в быстроте выполнения операций умножения/аккумуляции (MIPS - миллионы команд в секунду), но и такие характеристики, как последовательность выполнения программ, арифметических операций и адресации памяти, позволяющие сократить до минимума непроизводительные затраты времени. В целом DSP отличается от других типов микропроцессоров и микроконтроллеров по следующим пяти основным признакам:
-
Быстрая арифметика.
DSP - процессор должен осуществлять выполнение за один цикл операций умножения, умножения с аккумуляцией, циклический сдвиг, а также стандартные арифметические и логические операции.
-
Расширенный динамический объем для операции умножения/аккумуляции.
Операция вычисления суммы некой последовательности значений является фундаментальной для алгоритмов, реализуемых на DSP. Защита от переполнения необходима для избежания потери данных.
-
Выборка двух операндов за один цикл.
Очевидно, что для большинства операций, выполняемых DSP, необходимы два операнда. Таким образом, для достижения максимального быстродействия процессор должен быть способен производить одновременную выборку двух операндов, что требует также наличия гибкой системы адресации.
-
Наличие аппаратно реализованных циклических буферов(встроенных и внешних).
Широкий класс алгоритмов, реализуемых на DSP требует использования циклических буферов. Аппаратная поддержка циклического возврата указателя адреса или модульная адресация уменьшает непроизводительные затраты процессорного времени и упрощает реализацию алгоритмов.
-
Организация циклов и ветвлений без потери в производительности.
Алгоритмы DSP включают очень много повторяющихся операций, которые могут быть реализованы в виде циклов. Возможность организации последовательности выполнения программы кодов в цикле без потери производительности отличают DSP от других процессоров. Аналогично, потеря времени при выполнении операции ветвления по условию также недопустима при цифровой обработке сигналов.
Не следует, однако, думать, что DSP могут полностью заменить процессоры общего назначения. Как правило, процессоры цифровых сигналов имеют упрощенную систему команд, не позволяющие выполнить операции, не связанные с математическими вычислениями с такой же эффективностью, как и процессоры общего назначения. Попытка же сочетания в одном процессоре мощность при математических вычислениях и гибкость при операциях другого рода приводит к неоправданному повышению себестоимости. Поэтому DSP используют чаще в виде сопроцессоров (математических, графических, акселераторов и т.д.) при главном процессоре либо в качестве самостоятельного процессора, если этого достаточно.
16. Арбитраж
Основная функция протоколов арбитража - распределение времени пользования ресурсами между претендующими на них устройствами. Для осуществления арбитража используют 2-е линии: линия запрос, по которой устройство запрашивает захват ресурса; линия ответ, по которой поступает подтверждение на передачу. Помимо числа используемых сигналов протокол арбитража отличаются способом обработки запросов от нескольких устройств и реакцией на одновременные запросы - последовательный и параллельный арбитраж.
Параллельный арбитраж. Каждое устройство имеет индивидуальную линию запрос и ответ, которые соединены со входами и выходами специального устройства под названием арбитр. В случае поступления одновременно нескольких они обслуживаются в порядке значимости (приоритета), причем приоритет может изменяться или быть строго фиксированным.
После определения запроса, арбитр выдает пославшему устройству ответный сигнал (если запрос имеет наивысший приоритет).
Достоинства:
-
за минимальное время определяет максимальный приоритет;
-
использование управляемого программным способом арбитража дает возможность изменять приоритет запроса или запрещать (маскировать) любые из них во время работы микро ЭВМ.
Недостатки:
-
число обслуживаемых запросов ограничивается числом линий запрос и ответ на магистрали и соответствующим числом входов в арбитре.
Последовательный арбитраж используется общая линия запрос к которой подсоединены все выходы устройств и общая линия ответ проходящая через все устройства.
Приоритеты определяются физическим расположением устройства на магистрали. Максимальный приоритет имеют устройства находящиеся в начале линии ответ, минимальный - в конце линии.
Каждое из устройств при необходимости может перехватывать посылаемый по линии ответ сигналы подтверждающие (разрешающие) доступ к ресурсам и пользоваться этими ресурсами. Таким образом, в арбитре, как в отдельном устройстве, потребность отпадает.
Достоинства:
-
минимальное число используемых линий в магистрали;
-
возможность ввести в состав микро ЭВМ новое устройство с любым приоритетом.
Недостатки:
-
низкая скорость из-за необходимости распространения сигнала ответ через все устройства;
-
невозможность маскирования запросов.
17. Распределение разряда при обращении к устройству
Для реализации выбранных протоколов, каждое подключенное к магистралям устройство должно иметь необходимый набор схем сопряжения - интерфейс. Основу интерфейсу составляют буферы магистралей и логическая схема управления, которая осуществляет привязку к необходимым адресам и сигналам управления. Адресное пространство может включать ПЗУ, ОЗУ, УВВ, контроллеры и т.п. Привязка устройства к определенному месту адресного пространства осуществляется с помощью дешифрации адреса.
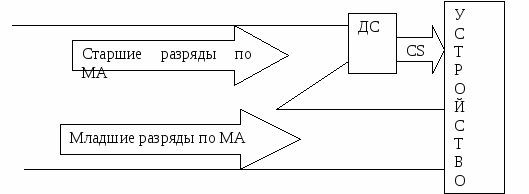
CS - сигнал выбора устройства
Количество непосредственно подаваемых на устройство младших разрядов МА определяется количеством адресуемых ячеек входящих в его состав. Размещение массива этих ячеек в адресном пространстве микро ЭВМ задается выбором определенной комбинации оставшихся разрядов МА для чего они и подаются на входы ДС, который вырабатывает сигнал выборки устройства.
Например: к 16 разрядной МА подключили память V=2048 ячеек (211), следовательно, 5-ть старших разрядов идет на ДС.
18. Шинный формирователь
Подключение устройств производится параллельно, через разветвляющиеся схемы (системные контроллеры, буферные регистры, шинные формирователи), т.е. схемы имеющие 3-и состояния выхода: логический «0», логическая единица «1», состояние высокого сопротивления.
Схемы построены так, что при подаче низкого сигнала, выход элементов подключается к магистрали. Все остальное время выход не оказывает влияние на состояние магистрали.
Однонаправленный шинный формирователь.

Информация передается от А к В, если на ОЕ поступает низкий сигнал
Пример однонаправленного шинного формирователя (для парралл.кода)
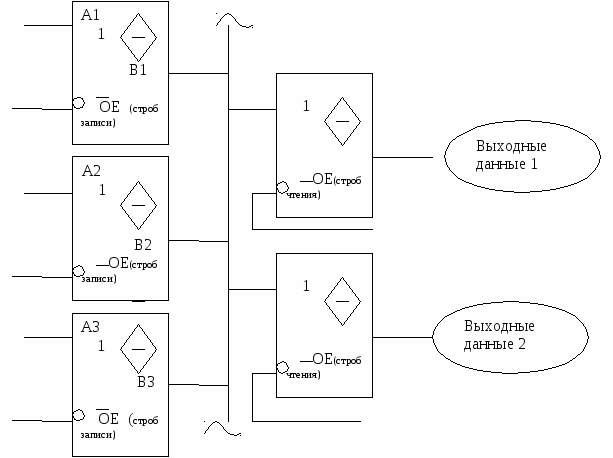
Что бы не произошло наслоение информации, на МД, на один из передатчиков подается сигнал низкого уровня, который разблокирует его выход. Другие передатчики в это время должны быть отключены. Приемники не влияют на состояние магистрали, их может быть подключено несколько. Прием информации осуществляется только по стробу чтения от логического устройства.
Двунаправленный формирователь.

ОЕ- сигнал разрешения передачи информации
А-вход, В- выход (или наоборот)
Т- сигнал выбора направления передачи информации.
А
В
ОЕ=1
-
-
ОЕ=0 Т=0
источник
приемник
ОЕ=0 Т=1
приемник
источник
19. 8-разрядный микропроцессор
На Рис. 9.1 представлена внутренняя структура МП i8080, включающего в себя 8-разрядное АЛУ с буферным регистром и схемой десятичной коррекции, блок РОН, регистры указателя стека SP и счетчика команд PC, первичный управляющий автомат УА, буферные схемы шин адреса и данных и схему управления системой.
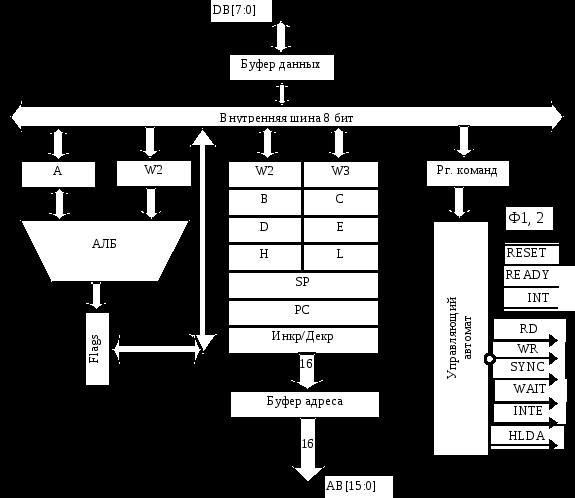
Рис. 9.6. Внутренняя структура МП i8080
Внешний интерфейс представлен 8-разрядной двунаправленной шиной данных D[7:0], 16-разрядной шиной адреса A[15:0] и группой линий управления.
Назначение входных и выходных линий МП :
D[7:0] - двунаправленная шина данных служит для приема и выдачи данных, приема команды, приема вектора прерывания, выдачи дополнительной управляющей информации (слово PSW);
A[15:0] - однонаправленная шина адреса служит для выдачи адреса памяти и устройств ввода/вывода;
Ф1,Ф2 - сигналы тактового генератора частотой 1..2,5 МГц;
RESET - сброс (начальная установка и запуск программы с адреса 0000);
READY - входной сигнал готовности памяти или ВУ к обмену (обеспечивает асинхронный режим обмена);
INT - запрос внешнего прерывания;
HOLD - захват шины (требование прямого доступа в память со стороны ВУ);
WR - запись - выходной сигнал, определяющий направление передачи информации по шине данных от процессора к памяти или ВУ;
RD - чтение - выходной сигнал, определяющий направление передачи информации по шине данных от памяти или ВУ к процессору;
SYNC - выходной сигнал, идентифицирующий наличие на шине данных дополнительной управляющей информации (PSW);
WAIT - выходной сигнал, отмечающий состояние ожидания или останова МП;
INTE - выходной сигнал, подтверждающий режим внешних прерываний;
HLDA - выходной сигнал, подтверждающий режим прямого доступа в память (подтверждение захвата).
Командный цикл микропроцессора
МП работает в составе МПС, обмениваясь информацией с памятью и ВУ. В основе работы МП лежит командный цикл - действия по выбору из памяти и выполнению одной команды. В зависимости от типа и формата команды, способов адресации и числа операндов командный цикл может включать в себя различное число обращений к памяти и ВУ и следовательно - иметь различную длительность.
Любой командный цикл (КЦ) начинается с извлечения из памяти первого байта команды по адресу, хранящемуся в PC, что команды i8080 имеют длину 1, 2 или 3 байта, причем в первом байте содержится информация о длине команды. В случае 2- или 3-байтовой команды реализуются дополнительные обращения к памяти по соседним (большим) адресам.
После считывания команды начинается ее выполнение, причем в процессе выполнения может потребоваться еще одно или несколько обращений к памяти или ВУ (чтение операнда, запись результата).
Для реализации команды i8080 может потребоваться от 1 до 5 обращений к памяти (ВУ). Хотя обращения к ЗУ/ВУ располагаются в разных частях КЦ, выполняются они по единым правилам, соответствующим интерфейсу МПС и реализованы на общем оборудовании управляющего автомата. Действия МПС по передаче в/из МП одного байта данных/команды называются машинным циклом.
Машинные циклы и их идентификация
Командный цикл представляет собой последовательность машинных циклов (МЦ), причем КЦ i8080 может содержать от 1 до 5 МЦ, которые принято обозначать M1, M2,..M5.
МЦ обязательно включает в себя действия по передаче байта информации. Кроме того, в некоторых МЦ дополнительно реализуются действия по пересылке и/или преобразованию информации внутри МП. Поэтому длительность МЦ может быть различной - за счет различного числа содержащихся в них машинных тактов (T1, T2,...).
Машинный такт (такт) образует пара сигналов тактового генератора Ф1, Ф2, поэтому длительность такта постоянна - период тактового генератора (за исключением такта Tw - см. ниже).
Таким образом, просматривается иерархия процедур при работе микропроцессора (не только i8080):
Командный цикл Машинный цикл Машинный такт
.
Каждому такту соответствует определенное состояние управляющего автомата. Любой МЦ i8080 обязательно содержит такты T1, T2, T3, предназначенные для передачи байта по интерфейсу. МЦ, в которых осуществляется передача и/или преобразование информации в МП, содержат дополнительно один или два такта T4, T5. МП i8080 вырабатывает несколько типов МЦ, основными из которых являются циклы ПРИЕМ и ВЫДАЧА
МЦ микропроцессора i8080 предусматривает возможность обмена как в синхронном, так и в асинхронном режиме. Если в составе МПС использованы только "быстрые" устройства, т.е. такие, которые могут работать с тактовой частотой МП, то передача информации в МЦ осуществляется в синхронном режиме. В этом случае на вход READY МП подается константа "1" и после такта T2 начинается такт T3. При работе с "медленными" устройствами, быстродействие которых не позволяет переключаться с частотой тактового генератора МП, необходимо "растянуть" во времени МЦ, реализовав асинхронный принцип обмена. Для этого в начале МЦ обмена с "медленными" устройствами на входе READY формируется уровень логического нуля. В такте T2 МП анализирует состояние READY, и если READY = 0, то МП после T2 переходит не к T3, а к такту ожидания Tw, который может длиться произвольное число периодов тактового генератора. Переход к T3 осуществляется по фазе Ф1, если в предыдущей Ф2 READY установился в "1". С помощью входа READY можно не только согласовывать работу МП с устройствами различного быстродействия, но и реализовывать пошаговый и потактовый режимы работы МП.
Таким образом, в машинном цикле выполняются следующие действия:
-
выдача адреса;
-
выдача информации о начатом МЦ (PSW);
-
анализ значения входных сигналов;
-
при необходимости - ожидание сигнала READY = 1;
-
прием/выдача данных;
-
при необходимости - внутренняя обработка/пересылка данных.
При реализации одного МЦ процессор может:
-
принять из памяти байт команды;
-
принять из памяти байт данных;
-
принять из УВв байт данных;
-
принять из стека байт данных;
-
принять вектор прерывания;
-
выдать в память байт данных;
-
выдать в стек байт данных;
-
выдать на УВыв байт данных.
Относительно выходных сигналов МП все перечисленные выше разновидности МЦ отличаются только направлением передачи данных: в МП - циклы 1..5 (ПРИЕМ), из МП - циклы 6..8 (ВЫДАЧА).
Дефицит внешних выводов МП не позволяет выводить во внешний интерфейс достаточный для эффективного функционирования объем управляющей информации. Для выдачи более полной информации о состоянии МП в текущем МЦ используется мультиплексирование шины данных. В начале каждого МЦ на линии шины данных D[7:0] выдается байт дополнительной управляющей информации (т.н. PSW).
Байт управляющей информации присутствует на шине данных (ШД) один такт, а использоваться может в течение всего МЦ. Поэтому в МПС, использующих информацию PSW, предусматривается специальный, внешний по отношению к МП, регистр-защелка для фиксации PSW.
20. 16-разрядный микропроцессор
Первый 16-разрядный процессор i8086 фирма Intel выпустила в 1978 году. Частота - 5 Мгц, производительность - 0,33 MIPS для инструкций с 16-битными операндами (позже появились процессоры 8 и 10 МГц). Технология 3 мкм, 29 000 транзисторов. Адресуемая память 1 Мбайт. Через год появился i8088 - тот же процессор, но с 8-разрядной шиной данных. С него началась история IBM PC, неразрывно связанная со всем дальнейшим развитием процессоров Intel.
16-разрядный МП i8086 явился дальнейшим развитием линии однокристальных МП, начатой i8080. Наряду с увеличением разрядности в i8086 реализован ряд новых архитектурных решений:
-
расширена система команд (по набору операций и способам адресации);
-
архитектура МП ориентирована на мультипроцессорную работу. Разработана группа вспомогательных БИС (контроллеров и специализированных процессоров) для организации мультимикропроцессорных систем различной конфигурации;
-
начато движение в сторону совмещения во времени выполнения различных операций. МП включает два параллельно работающих устройства
-
обработки данных и связи с магистралью, что позволяет совместить во времени процессы обработки информации и передачи ее по магистрали;
-
введена новая (по сравнению с i8080) организация памяти, которая далее использовалась во всех старших моделях семейства INTEL - сегментация памяти.
Для сохранения преемственности модели с i8080 в i8086 предусмотрено два режима работы - "минимальный" и "максимальный", причем в минимальном режиме i8086 работает просто как достаточно быстрый 16-разрядный i8080 с расширенной системой команд (архитектура МПС на базе i8086-min напоминает архитектуру на базе i8080).
Максимальный режим ориентирован на работу i8086 в составе мультимикропроцессорных систем, в которых, помимо нескольких центральных процессоров i8086, могут функционировать специализированные процессоры ввода/вывода i8089, сопроцессоры "плавающей арифметики" i8087.
Центральный процессор - поддерживает собственный командный цикл, выполняет программу, хранящуюся в системной памяти, по сбросу системы управление, как правило, передается центральному процессору (или одному из ЦП, если их несколько в системе).
Специализированный процессор - поддерживает собственный командный цикл, выполняет программу, хранящуюся в системной памяти, но инициализируется только по команде ЦП, по окончании выполнения программы сообщает ЦП о завершении работы.
Сопроцессор не поддерживает собственный командный цикл, выполняет команды, выбираемые для него ЦП из общего потока команд. По сути дела сопроцессор является расширением ЦП.
Внутренняя структура
Структурная схема МП i8086 представлена на рис. МП включает в себя три основных устройства :
-
УОД - устройство обработки данных;
-
УСМ - устройство связи с магистралью;
-
УУС - устройство управления и синхронизации.
УОД предназначено для выполнения команд и включает в себя 16-разрядное АЛУ, системные регистры и другие вспомогательные схемы; блок регистров (РОН, базовые и индексные) и блок микропрограммного управления.
УСМ обеспечивает формирование 20-разрядного физического адреса памяти и 16-разрядного адреса ВУ, выбор команд из памяти, обмен данными с ЗУ, ВУ, другими процессорами по магистрали. УСМ включает в себя сумматор адреса, блок регистров очереди команд и блок сегментных регистров.
УУС обеспечивает синхронизацию работы устройств МП, выработку управляющих сигналов и сигналов состояния для обмена с другими устройствами, анализ и соответствующую реакцию на сигналы других устройств МПС.
МП может работать в одном из двух режимов - "минимальном" (min) и "максимальном" (max). Минимальный режим предназначен для реализации однопроцессорной конфигурации МПС с организацией, подобной МПС на базе i8080, но с увеличенным адресным пространством, более высоким быстродействием и значительно расширенной системой команд. Максимальная конфигурация предполагает наличие в системе нескольких МП и специального блока арбитра магистрали (используется интерфейс Multibus).
На внешних выводах МП i8086 широко используется принцип мультиплексирования сигналов - передача разных сигналов по общим линиям с разделением во времени. Кроме того, одни и те же выводы могут использоваться для передачи разных сигналов в зависимости от режима (min - max).
Ниже приводится описание внешних выводов МП i8086. При описании выводов косой чертой разделены сигналы, появляющиеся на выводе в разные моменты машинного цикла. В круглых скобках указаны сигналы, характерные только для максимального режима. Символ \ после имени сигнала - знак его инверсии.

Рис.9.4. Внутренняя структура процессора i8086
A/D[15:0] - младшие [15:0] разряды адреса / данные;
A[19:16]/ST[6:3] - старшие [19:16] разряды адреса / сигналы состояния;
BHE\/ST[7] - разрешение передачи старшего байта данных / сигнал состояния;
STB(QS0) - строб адреса (состояние очереди команд);
R\ - чтение;
W\/(LOCK\) - запись (блокировка канала);
M-IO\(ST2\) - память - внешнее устройство (состояние цикла);
OP-IP\(ST1\) - выдача-прием (состояние цикла);
DE\(ST0\) - разрешение передачи данных (сост. цикла);
TEST\ - проверка;
RDY - готовность;
CLR - сброс;
CLC - тактовый сигнал;
INT - запрос внешнего прерывания;
INTA\(QS1) - подтверждение прерывания (состояние очереди команд);
NMI - запрос немаскируемого прерывания;
HLD(RQ\/E0) - запрос ПДП (запрос / подтверждение доступа к магистрали);
NLDA(RQ\/E1) - подтверждение ПДП (запрос / подтверждение доступа к магистрали);
MIN/MAX\ - потенциал задания режима (1-min, 0-max).
Сигналы состояния ("статуса") используются для отображения внутреннего состояния МП. Некоторые группы статусных сигналов используются только в максимальном режиме.