- Преподавателю
- Другое
- Методичка по базам данных
Методичка по базам данных
| Раздел | Другое |
| Класс | - |
| Тип | Конспекты |
| Автор | Селедцова А.М. |
| Дата | 29.04.2015 |
| Формат | docx |
| Изображения | Есть |

Курс лекций
по дисциплине "Базы данных "
Раздел 1. Основы теории баз данных
Тема 1.1 Основные понятия теории баз данных
Лекция 1
«Основные понятия теории баз данных. Развитие технологий обработки данных»
Основы теории баз данных
Первые компьютеры использовались для выполнения сложных расчетов, т.е. задач, имеющих сложный алгоритм обработки данных, но простую структуру данных и небольшой их объем.
Необходимость использования компьютеров для обработки больших объемов информации и данных сложной структуры стимулировала разработку новых видов внешних запоминающих устройств и потребовала разработки новых технологий обработки данных. В результате были созданы банки данных и автоматизированные информационные системы, которые позволили осуществлять многоаспектный доступ к данным, централизацию управления данными, устранение избыточности.
За несколько десятилетий обработка данных развилась от примитивных методов к сложным интегрированным системам и продолжает совершенствоваться.
До появления баз данных разработчики прикладных программ (написанных, например, на Бейсике, Паскале или Си) размещали нужные им данные в файлах, организуя их наиболее удобным для себя образом. При этом одни и те же данные могут иметь в разных приложениях совершенно разную организацию (разную последовательность размещения в записи, разные форматы одних и тех же полей и т.п.). Обобществить такие данные чрезвычайно трудно: например, любое изменение структуры записи файла, производимое одним из разработчиков, приводит к необходимости изменения другими разработчиками тех программ, которые используют записи этого файла.
Жесткая зависимость между данными и использующими их программами создает серьезные проблемы в ведении данных и делает использование их менее гибким.
Нередки случаи, когда пользователи одной и той же ЭВМ создают и используют в своих программах разные наборы данных, содержащие сходную информацию. Иногда это связано с тем, что пользователь не знает (либо не захотел узнать), что в соседней комнате или за соседним столом сидит сотрудник, который уже давно ввел в ЭВМ нужные данные. Поэтому при совместном использовании одних и тех же данных возникает масса проблем.
Активная деятельность по отысканию приемлемых способов обобществления непрерывно растущего объема информации привела к созданию в начале 60-х годов специальных программных комплексов, называемых «Системы управления базами данных» (СУБД).
Основная особенность СУБД - это наличие процедур для ввода и хранения не только самих данных, но и описаний их структуры. Файлы, снабженные описанием хранимых в них данных и находящиеся под управлением СУБД, стали называть «Базы данных» (БД).
Однако, за все надо расплачиваться: на обмен данными через СУБД требуется большее время, чем на обмен аналогичными данными прямо из файлов, специально созданных для того или иного приложения.
Преимущества централизованного управления данными по сравнению с монопольным обеспечением файлами каждого приложения
Сокращение избыточности хранимых данных.
Устранение противоречивости хранимых данных.
Многоаспектное использование данных (т.е. обеспечение новых приложений за счет уже имеющихся данных).
Комплексная автоматизация. На основе анализа требований пользователей можно выбрать такие структуры данных, которые обеспечат наилучшее обслуживание проекта в целом.
Обеспечение возможности санкционированного доступа к данным.
Обеспечение возможности стандартизации в представлении данных, что упрощает эксплуатацию банка данных, обмен с другими автоматизированными системами, облегчает процедуры контроля и восстановления.
Основные понятия и определения
Банк данных - это система информационных, математических, программных, языковых, организационных и технических средств для централизованного накопления и коллективного использования данных с целью получения необходимой информации.
Информация - любые сведения о каком - либо событии, сущности, процессе, над которыми производятся операции - восприятия, передачи, преобразования, хранения.
Данные - это информация, фиксированная в определенной форме, пригодной для последующей обработки, хранения, передачи.
В соответствии с этими понятиями в банках данных различают два аспекта рассмотрения вопросов: инфологический и датологический. Инфологический употребляется в связи со смысловым содержанием, а датологический - при рассмотрении вопросов представления данных в памяти информационной системы.
Предметная область - это область применения конкретного банка данных.
Запрос - процесс обращения пользователя к БД с целью ввода, получения или изменения информации в БД.
Транзакция - неделимая операция над БД, переводящая ее из одного непротиворечивого состояния в другое.
Типы и виды запросов пользователей
Задача обеспечения информационных запросов пользователей имеет два аспекта:
-
Банк данных должен обеспечивать АСУ всей необходимой информацией, а в идеальном случае и той, которая может понадобиться.
-
Банк данных должен быть ориентирован на эффективное обслуживание запросов пользователей.
Пользователей можно разделить:
1. По признаку постоянства общения с банком данных:
1.1. Постоянные пользователи, которые пользуются банком данных регулярно и для которых можно заранее сформулировать типы запросов в соответствии с их интересами; они могут также обращаться к системе и с произвольными по содержанию запросами.
1.2. Разовые пользователи - те, которые не имеют постоянных запросов, а только произвольные по содержанию.
2. По уровню компетенции или по возможности доступа к тем или иным данным. Речь идет о защите определенной части данных от тех пользователей, которые не имеют права их получать или изменять.
3. По форме представления запросов и по форме представления затребованной информации:
3.1. Пользователи - задачи - обращаются к банку данных с регламентированными по форме и по содержанию запросами. Выдаваемая информация соответствующим образом обрабатывается и компонуется.
3.2. Пользователи - люди обращаются к банку данных с произвольными либо регламентированными запросами. Выдаваемая информация должна иметь удобную для человека форму представления.
3.3. Пользователи - программисты выполняют работу по программированию функциональных задач. Для обеспечения их нормальной работы необходимо наличие в системе словаря данных и службы слежения за его состоянием. Словарь содержит сведения о наличии типов данных, их структуре и связях между ними, об изменениях в структуре информационной модели.
3.4. Пользователи - непрограммисты, для которых и создается банк данных (конечные пользователи). Для этой группы пользователей идеальна система, общение с которой выполняется на естественном языке. Поэтому для них целесообразно создавать специальный язык запросов, напоминающий естественный язык.
Так как услугами банка данных пользуется большое число разнородных пользователей, в банке данных предусматривается специальное средство для приведения всех запросов к единой терминологии - словарь данных, а также специальные методы для грамматической обработки запросов и организации доступа одновременно различных пользователей к одним и тем же данным.
Требования к банку данных со стороны пользователей
Обеспечивать хранение и модификацию больших объемов информации; удовлетворять выявленным и вновь возникающим потребностям пользователей.
Обеспечивать заданный уровень достоверности хранимой информации и ее непротиворечивость.
Обеспечивать возможность поиска информации по заданной группе признаков.
Обеспечивать доступ к данным только пользователей с соответствующими полномочиями.
Удовлетворять заданным требованиям производительности при обработке запросов.
Иметь возможность реорганизации и расширения при изменении границ предметной области.
Обеспечивать простоту и удобство обращения пользователей за информацией и выдачу информации в удобном для пользователя виде.
Обеспечивать возможность одновременного обслуживания большого числа пользователей.
Лекция 2
«Современное состояние технологий баз данных. Банк данных и его компаненты.»
Основные компоненты банка данных
-
База данных (БД).
-
Система управления базами данных (СУБД).
-
Администратор базы данных.
-
Словарь данных.
-
Вычислительная система.
-
Обслуживающий персонал.
База данных
База данных - это датологическое представление информационной модели предметной области. База данных представляет собой совокупность взаимосвязанных, совместно используемых и контролируемых данных (и их описание).
При рассмотрении и анализе предметной области используются термины сущность(объект), атрибут, связь.
Сущностью называется отдельный тип объекта предметной области (человек, место понятие, событие и т.п.)
Атрибутом называется свойство, которое описывает некоторую характеристику сущности (номер, цвет, адрес и пр.). Атрибут иногда называют элементом данных. Атрибут, который позволяет однозначно определить сущность, называется идентифицирующим или ключом.
Связь - это то, что объединяет несколько сущностей.
Совокупность значений связанных элементов данных образует запись данных. Совокупность записей образует файл данных.
Транзакция - неделимая операция над БД, которая переводит ее из одного непротиворечивого состояния в другое.
Централизованная база данных физически сосредоточена в одном месте и управляется одним компьютером. Большинство функций, ради которых создается база данных, проще выполнять, если она централизована. Так, проще обновлять данные, делать резервные копии, выполнять запросы и управлять доступом к базе данных, если мы знаем, где она находится и какие программы ею управляют.
Размер базы данных никак не связан с тем, централизована она или нет.
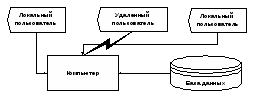
Структура централизованной базы данных
Распределенная база данных состоит из нескольких систем баз данных, управляемых различными компьютерами и соединенных коммуникационными линиями. Запрос или обновление данных перестает быть простым действием, управляемым одним программным модулем, а становится серией действий, производимых в нескольких узлах и управляемых несколькими программными модулями.
Для эффективного функционирования распределенных систем баз данных требуется наличие соответствующей технологии коммуникаций; кроме того, СУБД системы должны допускать возможность взаимодействия друг с другом и средствами коммуникаций.
Топология БД = Структура распределенной БД - схема распределения физической БД по сети.
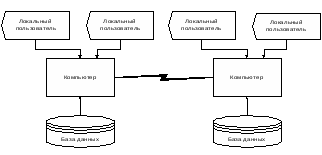
Структура распределенной базы данных
Для конечного пользователя распределенность системы должна быть совершенно прозрачна (невидима). Другими словами, распределенная система внешне длжна вести себя точно так, как и централизованная. В некоторых случаях это требование называют основным принципом построения распределенных СУБД.
Распределенные СУБД можно классифицировать как гомогенные и гетерогенные. В гомогенных системах все сайты используют один и тот же тип СУБД. В гетерогенных системах на сайтах могут функционировать различные типы СУБД.
Гомогенные системы значительно проще проектировать и сопровождать, а также наращивать размеры системы, добавляя новые сайты и повышать производительность системы за счет организации на различных сайтах параллельной обработки информации.
Гетерогенные системы обычно возникают в тех случаях, когда независимые сайты, уже эксплуатирующие свои собственные системы с базами данных, интегрируются во вновь создаваемую распределенную систему.
Очень важно понимать различия, существующие между распределенными БД и распределенной обработкой данных.
Обработка с использованием централизованной базы данных, доступ к которой может осуществляться с различных компьютеров сети, называется распределенной обработкой. Если данные хранятся централизованно, то данная система просто поддерживает распределенную обработку, но не может рассматриваться как распределенная БД.
Система управления базами данных (СУБД). Базовые понятия СУБД
СУБД - это специальный пакет программ, посредством которого реализуется централизованное управление базой данных и обеспечивается доступ к данным.
Резидентный модуль СУБД постоянно находится в резидентной памяти компьютера, с его помощью реализуются все операции доступа к базе данных.
В каждой СУБД имеются трансляторы либо интерпретаторы с языка описания данных (ЯОД) и языка манипулирования данными (ЯМД), единые для всей базы данных.
При создании интегрированных баз данных, включающих в свой состав несколько разнотипных СУБД, каждая из которых используется в своем локальном банке данных, разрабатываются единые для всего банка данных ЯОД(Data Definition Language) и ЯМД(Data Manipulation Language).
Описание структуры данного некоторого типа на формализованном языке называют схемой данного.
ЯОД предназначен для задания схемы базы данных. С его помощью описывают типы данных, подлежащих хранению в базе данных, их структуру и связи между собой.
ЯМД или язык запросов к базе данных представлен системой команд. Например,
-
произвести выборку из базы данных конкретного данного, удовлетворяющего определенным условиям;
-
произвести выборку из базы данных всех данных определенного типа, значения которых удовлетворяют заданным условиям;
-
найти в базе данных позицию данного и поместить туда его новое значение (либо удалить данные) и т.п.
Не все команды ЯМД можно выполнить за один шаг. Например, команда (b) - сначала выдается команда "найти 1-е данное, удовлетворяющее условию", затем следующее и т.д., пока в базе данных не будет больше найдено данных такого типа.
Существует две разновидности ЯМД - процедурные и непроцедурные языки, которые отличаются друг от друга способом извлечения данных.
Процедурные языки обычно обрабатывают информацию в БД последовательно, запись за записью, а непроцедурные оперируют сразу целыми наборами записей. С помощью процедурных языков указывается, как можно получить желаемый результат, а непроцедурных - что нужно получить. Наиболее распространенным языком непроцедурного типа является язык SQL (Structered Query Language), который в настоящее время определяется стандартом и являетяс обязательныи языком почти для всех СУБД.
Во многих СУБД имеются специальные средства обеспечения защиты данных от некомпетентного их использования и сбоев технических средств; средства контроля достоверности данных, средства автоматического накопления статистики использования данных пользователями.
Для упрощения работы пользователей с БД и обеспечения защиты данных СУБД использует механизм создания представлений, который позволяет каждому пользователю иметь дело только с теми данными, которые ему необходимы, и использование которых ему разрешено. Представление является некоторым подмножеством БД и создается с помощью специальных команд ЯОД.
Функции СУБД
-
Хранение, извлечение и обновление данных.
-
Хранение описания данных или метаданных (данные о данных) в словаре данных.
-
Поддержка транзакций. Должно быть гарантировано либо выполнение всех операций данной транзакции, либо ни одной.
-
Управление параллельностью. Должно быть гарантировано корректное обновление БД при параллельной работе пользователей.
-
Восстановление данных после сбоя аппаратного или программного обеспечения.
-
Контроль доступа к данным.
-
Поддержка обмена данными по сети
-
Поддержка целостности данных
-
Поддержка независимости от данных
-
Обеспечение эффективного администрирования.
Словарь данных
Представляет собой специальную систему в составе банка данных для хранения единообразной и централизованной информации обо всех ресурсах базы данных.
В словаре содержатся сведения:
-
об объектах, их свойствах и отношениях для данной предметной области;
-
о данных, хранимых в базе данных (наименование, смысловое описание, структура, связи с другими данными);
-
о возможных значениях и форматах представления данных;
-
об источниках возникновения данных;
-
о кодах защиты и разграничении доступа к данным со стороны пользователей.
Словарь данных нужен для уменьшения избыточности и противоречивости данных, для хранения описания данных, он позволяет пользователям использовать единообразную терминологию для данной предметной области.
Имеются СУБД с программными средствами ведения словаря данных (интегрированный словарь данных) и не имеющие таких средств. В последнем случае разрабатывается специальный пакет программ для ведения словаря. Правда, в этом случае существует дублирование описания данных в СУБД и в словаре, что может привести к противоречивости.
Администратор базы данных (АБД)
АБД - это лицо (или группа лиц), реализующее управление базой данных. Это специалисты, знакомые с теорией систем обработки данных и спецификой программного обеспечения данной информационной системы.
Основная функция АБД - обеспечение структур данных и взаимосвязей между ними, эффективных для обслуживания всего коллектива пользователей.
На стадии проектирования базы данных АБД выступает в качестве идеолога и главного конструктора системы, на этапе эксплуатации он отвечает за нормальное функционирование банка данных и сохранность данных.
В составе группы АБД должны быть:
-
системные аналитики,
-
проектировщики структур данных,
-
проектировщики технологических процессов обработки информации,
-
системные и прикладные программисты,
-
операторы и специалисты по техническому обслуживанию.
Основные функции группы АБД
-
Анализ предметной области, ее описание, определение требований пользователей и т.д.
-
Проектирование БД: разработка структуры БД и задание ограничений целостности, описание БД на ЯОД; разработка приложений, словарей - справочников БД.
-
Первоначальная загрузка: разработка технологии загрузки и проверки достоверности данных.
-
Защита данных: разработка принципов и средств защиты, тестирование системы защиты, исследование случаев нарушения защиты.
-
Обеспечение восстановления БД: разработка соответствующих технологических процессов и программных средств.
-
Анализ эффетивности функционирования БД.
-
Работа с конечными пользователями: сбор информации об изменениях в предметной области, обучение и консультирование пользователей, разработка методической и учебной документации по работе пользователей.
Тема 1.2 Архитектура СУБД и модели данных
Лекция 3
«Трехуровневая архитектура описания базы данных. Режимы работы с базой данных»
Режимы работы с базой данных
Режимы использования БД в общем случае можно представить в следующем виде:
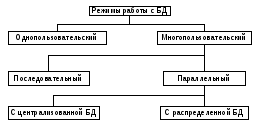
Однопользовательский режим - БД размещена на одном компьютере и используется одним пользователем.
Многопользовательский последовательный режим - БД размещена на одном компьютере и используется несколькими пользователями последовательно. Вопросы сохранения целостности БД решаются с помощью организационных мер (соблюдение заданной последовательности операций и пр.)
Многопользовательский параллельный режим с централизованной БД - единая БД размещена на одном компьютере сети и используется параллельно несколькими пользователями, которые имеют свои бизнес - функции и территориально могут находиться в разных помещениях. Возникает необходимость распределения приложений. Такие системы называются системами распределенной обработки данных.
Многопользовательский параллельный режим с распределенной БД - БД размещена по нескольким компьютерам, расположенным в сети и используется параллельно несколькими пользователями. Такие системы называются системами распределенных БД.
Удаленный запрос - запрос, который выполняется с помощью модемной связи.
Реализация удаленной транзакции - обработка транзакции на удаленном узле.
Распределенный запрос - запрос, при обработке которого используются данные из БД, расположенные в разных узлах сети.
Распределенная транзакция - транзакция, состоящая из нескольких запросов, которые выполняются на нескольких узлах сети, но каждый только на одном.
Выбор режима работы и структуры БД определяется ее масштабами и задачами.
Модели «клиент - сервер» в технологии баз данных
Из всех режимов работы с БД наибольшие проблемы возникают при реализации БД с параллельным доступом.
При работе в режиме распределенного доступа процесс выполнения строится по принципу взаимодействия двух программных процессов, один из которых называется «клиентом», а второй - «сервером». Клиентский процесс запрашивает некоторые услуги, а серверный процесс их оказывает.
Основной принцип технологии «клиент - сервер» в БД заключается в разделении функций приложения на 5 групп:
-
Функции ввода и отображения данных (Presentation Logic)
-
Прикладные функции, определяющие основные алгоритмы решения задач (Business Logic);
-
Функции обработки данных внутри приложения (Database Logic);
-
Функции управления информационными ресурсами (Database Meneger Sysytem);
-
Служебные функции, играющие роль связок между функциями первых четырех групп.
Презентационная логика (Presentation Logic) определяется тем, что пользователь видит на экране - это и формы ввода и результаты обработки запросов. Основные задачи презентационной логики - это формирования изображений на экране, чтение и запись информации в экранные формы, обработка сигналов мыши и клавиатуры.
Бизнес - логика(Business Logic) - это часть кода приложения, которая определяет собственно алгоритмы решения задач приложения и пишется с использованием различных языков, таких как С, Visual Basic, Cobol и т.п.
Логика обработки данных (Database Logic) связана с обработкой данных внутри приложения. Для доступа к данным используется язык запросов и средства манипулирования данными языка SQL.
Процессор управления данными (Database Meneger Sysytem)- это собственно СУБД.
В централизованной архитектуре все эти части приложения расположены в одной среде и комбинируются внутри одной исполняемой программы.
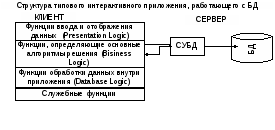
В клиент - серверной технологии эти задачи могут по-разному распределяться между серверным и клиентским процессами.
Модель файлового сервера (файл - сервер)
В этой модели презентационная логика и бизнес - логика располагаются на клиенте. На сервере располагаются файлы с данными и поддерживается доступ к файлам. Функции управления информационными ресурсами и СУБД находятся на клиенте.
Запрос клиента формулируется в командах ЯМД, СУБД переводит этот запрос в последовательность файловых команд. Файловые команды вызывают перекачку информации на клиента, которая производится до тех пор, пока не будет получен ответ на запрос.
Недостатки:
-
высокий сетевой трафик;
-
защита данных только на уровне файловой системы.
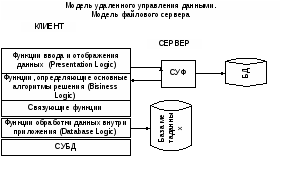
Модель удаленного доступа к данным
БД хранится на сервере, там же находится ядро СУБД. На клиенте находится презентационная логика и бизнес - логика приложения. Клиент обращается к сереверу с запросами на языке SQL.
Преимущества:
-
уменьшение загрузки сети (SQL запрос вместо файлов БД);
-
стандартизованное общения «клиент-сервер».
Недостатки:
-
при повторении аналогичных функций для разных приложений один и тот же код бизнес-логики должен повторяться для каждого клиента;
-
управление информационными ресурсами выполняют клиенты (поддержание целостности усложнено).
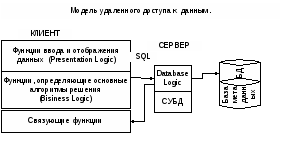
Модель сервера баз данных
Данную модель поддерживают большинство современных СУБД. Бизнес-логика разделена между клиентом и сервером. На сервере она реализована в виде хранимых процедур. Клиент обращается с командой вызова хранимой процедуры, а сервер ее выполняет и возвращает клиенту соответствующие данные. Централизованный контроль целостности данных обеспечивается использованием механизма триггеров.
Хранимая процедура. Программа, написанная на языке СУБД, скомпилированная на машинный язык и сохраненная для многократного и более эффективного выполнения.
Триггер - это программа, которая автоматически выполняется при попытке изменения содержимого заданной таблицы. Для каждой таблицы можно определить три типа триггеров: триггеры ввода, добавления и удаления.
Преимущества:
-
резкое уменьшение загрузки сети;
-
хранимые процедуры и триггеры используются несколькими клиентами, что уменьшает дублирование алгоритмов обработки данных;
-
механизм триггеров упрощает контроль целостности БД.
Недостатки:
-
большая загрузка сервера.
Так как на сервер переложена большая часть бизнес-логики, то требования к клиентам в такой модели существенно уменьшаются. Такую модель называют моделью с «тонким клиентом», в отличие от предыдущих («толстый клиент»).
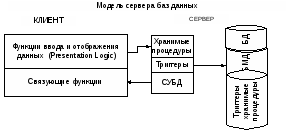
Модель сервера баз приложений
Вводится дополнительный промежуточный уровень между клиентом и сервером, который содержит один или несколько серверов приложений.
Клиент обеспечивает презентационную логику и коммуникационные функции.
Серверы приложений хранят и исполняют наиболее общие правила бизнес-логики, обеспечивают обмен сообщениями и поддержку запросов, особенно в распределенных транзакциях.
Серверы баз данных занимаются функциями СУБД: поддерживают целостность БД, обеспечивают восстановление после сбоев и т.д.
Такая модель обладает большей гибкостью, чем двухуровневые, особенно, когда клиенты выполняют сложные аналитические расчеты.
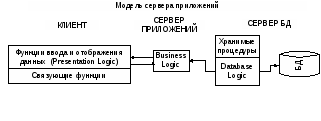
Архитектура баз данных
Программы, с помощью которых пользователи работают с БД, называются приложениями. В общем случае с одной БД могут работать несколько приложений параллельно и независимо друг от друга, и СУБД должна обеспечить их работу таким образом, чтобы каждое приложение работало корректно и учитывало все изменения, вносимые другими приложениями.
Логическая и физическая структура БД
Одним из наиболее революционных решений в области методов доступа к данным стала идея отделения логической стуктуры и манипуляции данными, как они понимаются конечным пользователем, от их физического представления, требуемого компьютерным оборудованием. Это решение представлено трехуровневой артитектурой БД в соответствии со стандартом ANSI/SPARC.
Для обеспечения независимости прикладных программ от данных необходимо ввести модель данных, которая будет отражать для пользователей информационное содержание базы данных, но подробности организации физического хранения данных в ней будут отсутствовать.
Модель должна иметь свою схему, в которой отражена структура данных, имена записей, имена и форматы полей. Прикладные программисты работают только с записями модели.
Для образования записей модели СУБД должна располагать информацией о том, как записи и их поля строятся из хранимых в физической базе данных записей и полей. То есть на СУБД возлагается задача реализации отображения (прямого и обратного).
Модель - Физическая база данных
В описании отображения кроме указания соответствия между полями записей модели и полями хранимых записей будут указаны все необходимые сведения о хранимых данных:
-
в каком коде представлены;
-
как упорядочены;
-
где расположены;
-
с какими данными связаны;
-
какие методы доступа необходимо использовать и т.д.
Обычно при проектировании СУБД не разрабатывают программы манипулирования данными на физическом уровне, а используют программы методов доступа операционной системы. Это обеспечивает относительную независимость операций хранения и обработки данных от используемых технических средств, предоставляемую операционной системой. Поэтому вводится модель представления хранимых данных или внутренняя модель данных.
Модель -> Внутренняя модель -> физическая база данных - это двухуровневая архитектура банка данных.
Пользователи составляют прикладные программы только в терминах модели данных. СУБД, получив запрос из прикладной программы, организует запрос к операционной системе на получение из физической базы данных необходимой информации. Такая архитектура обеспечивает независимость прикладных программ от данных и определенную независимость от используемых технических средств.
Однако модель данных является глобальным логическим представлением информационного содержимого базы данных, и это вынуждает каждого пользователя при написании программ сначала ознакомиться с моделью данных для всей базы данных, что во многих случаях неприемлемо:
-
часто в этом нет необходимости;
-
логические представления для пользователей могут отличаться (имеются ненужные связи и т.п.);
-
нарушается защита данных.
Поэтому вводится еще один уровень логического представления данных - для каждого конкретного пользователя - внешняя модель данных. А модель данных, рассмотренная ранее, которая охватывает все содержимое базы данных, называется концептуальной моделью.
В трехуровневой архитектуре банка данных СУБД реализует следующие отображения:
Внешняя модель -> Концептуальная модель -> Внутренняя модель -> Физическая база данных.
СУБД реализует обмен данными между рабочей областью ввода-вывода прикладной программы и физической базой данных. Любой запрос прикладной программы, сформулированный на ЯМД, поступает к СУБД. Имея соответствующие описания моделей и описания отображений между моделями, СУБД обращается к методам доступа операционной системы для выполнения необходимых операций на физическом уровне.
Таким образом, СУБД дает возможность программам и пользователям осуществлять доступ к хранимым данным лишь по их именам, не заботясь о физическом расположении этих данных. Нужные данные отыскиваются СУБД на внешних запоминающих устройствах по физической модели данных.
Такая архитектура получила наибольшее распространение.
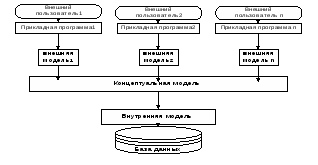
Кроме названных трех уровней в банке данных существует еще один, им предшествующий. Модель этого уровня должна отражать информацию о предметной области в виде, независимом от конкретной СУБД. С этой моделью предметной области работают администратор базы данных и пользователи, используя естественный язык, математические формулы, таблицы, графики и других средства. Она называется инфологической моделью предметной области. Инфологические модели данных используются на ранних стадиях проектирования БД.
Рассмотренные ранее внешняя и концептуальная модели, с которыми работает СУБД, образуют даталогическую модель.
Трехуровневая архитектура позволяет обеспечить независимость хранимых данных от использующих их программ. При необходимости можно переписать хранимые данные на другие носители информации и (или) реорганизовать их физическую структуру, изменив лишь физическую модель данных. АБД может подключить к системе любое число новых пользователей (новых приложений), дополнив, если надо, даталогическую модель. Указанные изменения физической и даталогической моделей не будут замечены существующими пользователями системы (окажутся "прозрачными" для них), так же как не будут замечены и новые пользователи. Следовательно, независимость данных обеспечивает возможность развития системы баз данных без разрушения существующих приложений.
Лекция 4
«Модели данных: понятие основные компоненты и классификации»
Понятие модели данных
Данные не обладают определенной структурой, данные становятся информацией тогда, когда пользователь задает им определенную структуру, то есть осознает их смысловое содержание. Поэтому центральным понятием в области баз данных является понятие модели.
Модель - это представление реальности, отражающее лишь избранные детали.
База данных является моделью предметной области. Она отображает элементы реальности в элементы модели. Отобразить - значит ассоциировать элементы из одной области с элементами другой области. Если процесс отображения выполнен должным образом, то моделью можно воспользоваться для решения задачи. Если нет, то модель не может служить источником правильного решения.
Если процесс отображения выполнен правильно, то моделью можно воспользоваться для решения задачи.
Каждая ЭВМ обладает простой моделью данных - это допустимые в ЭВМ форматы данных и состав операций, выполняемых над ними. Это физическая модель данных. С ее помощью можно построить более сложные и удобные модели данных. Пример - модель данных языка высокого уровня, то есть совокупность методов и средств для определения логических структур данных и процессов изменения их состояния. Эти модели данных называют логическими.
Модель данных, поддерживаемую некоторым языком программирования, обычно характеризуют следующим образом:
-
идентифицируют типы логических структур данных, которые можно представить в данной модели;
-
специфицируют: признаки структур данного типа, правила композиции структур данного типа из структур других типов; правила обработки этих структур.
Все это относится и к СУБД. Отличие от алгоритмического языка в том, что операторы разделены и оформлены в виде самостоятельных языков: ЯОД и ЯМД. Совокупность операторов ЯОД и ЯМД определяет модель данных, поддерживаемую конкретной СУБД.
Модель данных - совокупность структур данных и операций над ними.
Схемой структуры данных называется описание структуры данных на каком-либо формализованном языке. Схема описывает те свойства структуры данных, которые не изменяются при выполнении прикладных программ, и которые можно объявить заранее.
Построение структур данных в каждой конкретной модели данных выполняется только по определенным правилам. Это связано с ограничениями, вытекающими из особенностей используемых в модели данных типов структур и операций, которые над ними можно выполнять.
Таким образом, основные компоненты модели данных:
-
структуры данных,
-
операции над ними,
-
ограничения.
Они тесно связаны между собой и в конкретных моделях данных могут быть реализованы различными способами.
Основные операции над данными
Реализация любой конкретной операции над данными включает в себя селекцию данных, то есть выделение именно тех данных, над которыми она должна быть выполнена. Селекция выполняется в соответствии с критериями отбора любым из способов с использованием: логической позиции данного, значения данного, связей между данными.
Используя логическую позицию данных можно выполнить селекцию данных, находящихся на первой, последней, предыдущей, последующей позиции или на позиции с определенным номером. Этот тип селекции еще называют селекцией посредством текущей. При выполнении прикладной программы СУБД автоматически поддерживает ее индикаторы текущего состояния. Индикатор указывает на некоторый экземпляр записи в базе данных. В некоторых моделях текущие задаются явно, в некоторых нет.
При селекции по значениям данных критерий селекции может определять простые или булевы условия отбора данных:
имя_атрибута оператор_условия значение атрибута
В операторе условия используются логические функции =,>,<,<>,>=,<=. Булевы условия строятся с использованием операторов НЕ, И, ИЛИ. Используются скобки для определения порядка их выполнения.
Если модель данных позволяет выполнить селекцию данных по их связям, то с помощью условия селекции выполняется идентификация требуемых данных.
По характеру производимых действий различают следующие виды операций:
1. Идентификацию данного и нахождение его позиции в базе данных;
2. Выборку (чтение) данного из базы;
3. Включение (запись) данного в базу;
4. Удаление данного из базы;
5. Модификацию (изменение) значения данного в базе.
В некоторых языках первая и вторая операции объединяются.
Модель данных также должна предусматривать специальные операции для установления и разрыва связей в базе данных.
По характеру способа получения результата различают навигационные и спецификационные операции. Если результат получается путем прохождения по связям, то операцию называют навигационной. Результат чаще всего - единичный объект в базе данных. Если в операции определяются только требования к результату, но не задается способ их получения, то операция называется спецификационной. Результату такой операции обычно соответствует некоторое множество объектов, существующих в базе данных.
Рассмотренные виды операций подчиняются простой схеме - вначале выполняется селекция требуемых данных, а затем выборка, включение, удаление или модификация.
В ряде случаев необходимо выполнять более сложные действия над данными. Обобщенные операции над данными называют процедурами баз данных. Запуск процедур может выполняться либо по директиве пользователя, либо автоматически СУБД при возникновении определенных ситуаций. (Например, удаление записей-членов группы при удалении ее владельца).
Особый вид составляют процедуры, вычисляющие значения атрибутов, отсутствующих в базе данных, но которые можно вычислить на основании значений других атрибутов. Это процедуры, вычисляющие виртуальные атрибуты.
Особенность процедуры базы данных и отдельной операции - неделимость их действия. Процедура рассматривается как отдельная операция, при выполнении которой ни одна другая процедура или прикладная программа не может обратиться к данным до ее окончания. Такие процедуры и операции называются транзакциями.
Модели данных
Классификация моделей данных
В соответствии с рассмотренной ранее трехуровневой архитектурой мы сталкиваемся с понятием модели данных по отношению к каждому уровню. И действительно, физическая модель данных оперирует категориями, касающимися организации внешней памяти и структур хранения, используемых в данной операционной среде. В настоящий момент в качестве физических моделей используются различные методы размещения данных, основанные на файловых структурах: это организация файлов прямого и последовательного доступа, индексных файлов и др. Кроме того, современные СУБД широко используют страничную организацию данных, которая является наиболее перспективной.
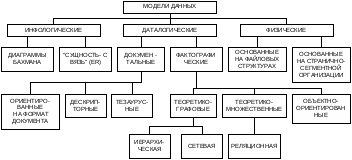
Рассмотрим модели данных, используемые на концептуальном уровне [1].
Документальные модели данных
Документальные модели данных соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке.
Модели, основанные на языках разметки документов, связаны прежде всего со стандартным общим языком разметки - SGML (Standart Generalised Markup Language), который был утвержден ISO в качестве стандарта еще в 80-х годах. Этот язык предназначен для создания других языков разметки, он определяет допустимый набор тегов (ссылок), их атрибуты и внутреннюю структуру документа. Из-за своей сложности SGML использовался в основном для описания синтаксиса других языков (наиболее известным из которых является HTML), и немногие приложения работали с SGML-документами напрямую.
Гораздо более простой и удобный, чем SGML, язык HTML (Hyper Text Markup Language) позволяет определять оформление элементов документа и имеет некий ограниченный набор инструкций - тегов, при помощи которых осуществляется процесс разметки. Инструкции HTML в первую, очередь предназначены для управления процессом вывода содержимого документа на экране программы-клиента и определяют этим самым способ представления документа, но не его структуру. В качестве элемента гипертекстовой базы данных, описываемой HTML, используется текстовый файл, который может легко передаваться по сети с использованием протокола HTTP. Эта особенность, а также то, что HTML является открытым стандартом и огромное количество пользователей имеет возможность применять возможности этого языка для оформления своих документов, безусловно, повлияли на рост популярности HTML и сделали его сегодня главным механизмом представления информации в Интернет.
Однако HTML сегодня уже не удовлетворяет в полной мере требованиям, предъявляемым современными разработчиками к языкам подобного рода. И ему на смену был предложен новый язык гипертекстовой разметки, мощный, гибкий и, одновременно с этим, удобный язык XML (Extensible Markup Language) - язык разметки, описывающий целый класс объектов данных, называемых XML-документами. Он используется в качестве средства для описания грамматики других языков и контроля правильности составления документов. То есть сам по себе XML не содержит никаких тегов, предназначенных для разметки, он просто определяет порядок их создания.
Тезаурусные модели основаны на принципе организации словарей, содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используются в системах-переводчиках, особенно многоязыковых переводчиках.
Дескриптпорные модели - самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор - описатель. Этот дескриптор имел жесткую структуру и описывал документ в cooтветствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой документальной БД. Например, для БД, содержащей описание патентов, дескриптор содержал название области, к которой относился патент, номер патента, дату выдачи патента и еще ряд ключевых параметров, которые заполнялись для каждого патента. Обработка информации в таких базах данных велась исключительно по дескрипторам, то есть по тем параметрам, которые характеризовали патент, а не по самому тексту патента.
Теоретико-графовые модели данных
Эти модели отражают совокупность объектов реального мира в виде графа взаимосвязанных информационных объектов. В зависимости от типа графа выделяют иерархическую или сетевую модели. Исторически эти модели появились раньше, и в настоящий момент они используются реже, чем более современная реляционная модель данных. Однако до сих пор существуют системы, работающие на основе этих моделей, а одна из концепций развития объектно-ориентированных баз данных предполагает объединение принципов сетевой модели с концепцией реляционной.
Лекция 5
«Сетевая модель данных: элементы структуры, основные операции над данными и ограничения целостности»
Сетевая модель данных
Сети - естественный способ представления отношений между объектами. Они широко применяются в математике, исследованиях операций, химии, физике, социологии и других областях знаний. Сетевая архитектура применяется также и к базам данных.
Сети обычно могут быть представлены математической структурой, которая называется направленным графом. Направленный граф имеет простую структуру. Он состоит из точек или узлов, соединенных стрелками или ребрами. В контексте моделей данных узлы можно представлять как типы записей данных, а ребра представляют отношения один-к-одному или один-ко-многим. Таким образом, сетевая модель данных представляет данные сетевыми структурами типов записей, связанных отношениями мощности один-к-одному или один-ко-многим. Структура графа делает возможными простые представления иерархических отношений (таких как генеалогические данные), отношений принадлежности (например, отдел, в котором работает служащий) и многих других. Более того, после того как отношение между двумя объектами установлено, становится возможным эффективное выполнение извлечения данных и манипуляции ими.
Конференция по языкам систем данных (Conference on Data Systems Languages, CODASYL), поручила подгруппе, названной Database Task Group (DBTG), разработать стандарты систем управления базами данных.
Стандарт сетевой модели впервые был определен в 1975 году организацией CODASYL (Conference of Data System Languages), которая определила базовые понятия модели и формальный язык описания.
Базовыми объектами модели являются:
элемент данных;
агрегат данных;
запись;
набор данных.
Элемент данных - это минимальная информационная единица, доступная пользователю с использованием СУБД.
Агрегат данных соответствует следующему уровню обобщения в модели. В модели определены агрегаты двух типов: агрегат типа вектор и агрегат типа повторяющаяся группа. Агрегат данных имеет имя, и в системе допустимо обращение к агрегату по имени.
Агрегат типа вектор соответствует линейному набору элементов данных. Например, агрегат Адрес может быть представлен следующим образом: Город,Улица, Дом, Квартира.
Агрегат типа повторяющаяся группа соответствует совокупности векторов данных. Например, агрегат Зарплата соответствует типу повторяющаяся группа с числом повторений 12.
Зарплата
Месяц
Сумма
Записью называется совокупность агрегатов или элементов данных, моделирующая некоторый класс объектов реального мира. Для записи вводятся понятия типа записи и экземпляра записи. Типы записей определяются обычным образом как совокупности логически связанных записей. Экземпляр (вхождение) - действительные значения записи в структуре данных.
Наборы в модели DBTG выражают отношения один-ко-многим (или один-к-одному) между двумя типами записей. Набор фактически отражает иерархическую связь между двумя типами записей. Родительский тип записи в данном наборе называется владельцем набора, а дочерний тип записи - членом того же набора.
Для любых двух типов записей может быть задано любое количество наборов, которые их связывают. В рамках набора возможен последовательный просмотр экземпляров членов набора, связанных с одним экземпляром владельца набора.
Между двумя типами записей может быть, определено любое количество наборов: например, можно построить два взаимосвязанных набора. Существенным ограничением набора является то, что один и тот же тип записи не может быть одновременно владельцем и членом набора.
Наборы обозначаются стрелками между типами записей, причем стрелка указывает в сторону типа записи члена (сторона «много» отношения один-ко-многим). Каждый набор состоит из типа записи владельца, типа записи члена и имени набора. Имя набора - это метка, присвоенная стрелке. Это соответствует графу, в котором узлами являются типы записей, а ребра представлены стрелками, соединяющими типы записей. Структура данных состоит из этих простых наборов отношений.
B модели DBTG возможны только простые сети, в которых все отношения имеют мощность один-к-одному или один-ко-многим. Сложные сети, включающие одно или несколько отношений много-ко-многим, не могут быть напрямую реализованы в модели DBTG. Однако, существует метод преобразования сложной сети в простую сетевую форму, необходимую для DBTG-реализации.
Язык определения данных (ЯОД) DBTG. Применяется ЯОД для реализации схемы.
Схема состоит из следующих частей:
Раздел схемы, задающий имя схемы (описание базы данных - области размещения).
Разделы записей (описания записей), определяющие структуру каждой записи: ее элементы данных и агрегаты (каждый в отдельности) и ее адрес. После описания записи в целом идет описание внутренней структуры:
<Имя уровня> <Имя данного» <(Шаблон> <Тип>
Номер уровня определяет уровень вложенности при описании элементов и агрегатов данных. Первый уровень - сама запись. Поэтому элементы или агрегаты данных имеют уровень начиная со второго. Если данное соответствует агрегату, то любая его составляющая добавляет один уровень вложенности.
Разделы наборов, определяющие все наборы, включая типы записей владельцев и членов.
Язык манипулирования данными DBTG.
Все операции манипулирования данными в сетевой модели делятся на навигационные операции и операции модификации.
Навигационные операции осуществляют перемещение по БД путем прохождения по связям, которые поддерживаются в схеме БД. В этом случае результатом является новый единичный объект, который получает статус текущего объекта.
Операции модификации осуществляют как добавление новых экземпляров отдельных типов записей, так и экземпляров новых наборов, удаление экземпляров записей и наборов, модификацию отдельных составляющих внутри конкретных экземпляров записей.
В противоположность ЯМД реляционных систем баз данных, операторы которых обрабатывают сразу всю реляционную таблицу, операторы ЯМД DBTG обрабатывают записи по одной. Более того, ЯМД необходимо погружать в базовый язык, такой как Кобол. Основные команды ЯМД можно классифицировать следующим образом: команды передвижения, команды извлечения, команды обновления записей, команды обновления наборов.
Операторы манипулирования данными в сетевой модели
Операция
Назначение
READY
Обеспечение доступа к БД
сходна по смыслу с операцией открытия файла)
FINISH
Окончание работы с БД
FIND
Группа операций, устанавливающих указатель найденного объекта на текущий объект
GET
Передача найденного объекта в рабочую область. Допустима только после FIND
STORE
Помещение в БД записи, сформированной в рабочей области
CONNECT
Включение текущей записи в текущий экземпляр набора
DISCONNECT
Исключение текущей записи из текущего экземпляра набора
MODIFY
Обновление текущей записи данными из рабочей области пользователя
ERASE
Удаление экземпляра текущей записи
Реализация. Сетевая модель DBTG особенно хорошо подходит для информационных систем, которые характеризуются:
-
большим размером;
-
хорошо определенными, повторяющимися запросами;
-
хорошо определенными транзакциями;
-
хорошо определенными приложениями;
Если все эти факторы присутствуют, то пользователи и проектировщики системы базы данных могут сосредоточить усилия на обеспечении того, чтобы приложения были написаны наиболее эффективным образом. Негативная сторона состоит в том, что не предвиденные заранее приложения в будущем могут работать плохо; они даже могут потребовать трудоемкой реорганизации структуры базы данных.
Лекция 6
«Иерархическая модель данных: элементы структуры, основные операции над данными и ограничения целостности»
Иерархическая модель данных
Иерархическая модель данных является наиболее простой среди всех даталогических моделей. Исторически она появилась первой среди всех даталогических моделей: именно эту модель поддерживает первая из зарегистрированных промышленных СУБД IMS фирмы IBM.
Основными информационными единицами в иерархической модели являются: база данных (БД), сегмент и поле.
Поле данных определяется как минимальная, неделимая единица данных, доступная пользователю с помощью СУБД.
Сегмент в терминологии Американской Ассоциации по базам данных DBTG (Data Base Task Group) называется записью, при этом в рамках иерархической модели определяются два понятия: тип сегмента или тип записи и экземпляр сегмента или экземпляр записи.
Тип сегмента - это поименованная совокупность типов элементов данных, в него входящих. Экземпляр сегмента образуется из конкретных значений полей или элементов данных, в него входящих. Каждый тип сегмента в рамках иерархической модели образует некоторый набор однородных записей. Для возможности различия отдельных записей в данном наборе каждый тип сегмента должен иметь ключ или набор ключевых атрибутов (полей, элементов данных). Ключом называется набор элементов данных, однозначно идентифицирующих экземпляр сегмента.
В иерархической модели сегменты объединяются в ориентированный древовидный граф. При этом направленные ребра графа отражают иерархические связи между сегментами: каждому экземпляру сегмента, стоящему выше по иерархии и соединенному с данным типом сегмента, соответствует несколько (множество) экземпляров данного (подчиненного) типа сегмента.
На концептуальном уровне иерархическая модель данных является просто частным случаем сетевой модели данных. Как отмечалось в предыдущей главе, сеть - это направленный граф, состоящий из точек, соединенных стрелками. Применительно к моделям данных, точки - это типы записей, а стрелки представляют отношения один-к-одному или один-ко-многим. Стрелка в сети имеет по точке с каждого конца. Точка в «хвосте» стрелки в терминологии иерархической модели называется предком, а точка на острие стрелки называется потомком. Принципиальная разница между сетевой и иерархической моделями состоит в том, что в сетевой модели потомок может принадлежать нескольким предкам, тогда как в иерархической модели - только одному. Тип сетевой структуры, разрешенный в иерархической модели, называется деревом. Отношения в иерархической модели данных организованы в виде совокупностей деревьев, а не произвольных графов.
Как и в случае сетевой модели, с иерархической структурой данных связаны два основных понятия: типы сегментов, или просто сегменты, и типы отношений предок-потомок. Сегмент аналогичен типу записей сетевой модели. Тип ОПП аналогичен типу набора сетевой модели, за исключением того, что тип сегмента может являться потомком только для одного типа отношения предок-потомок.
Основной структурой иерархической модели является дерево. Дерево данных - это иерархия сегментов, удовлетворяющих следующим правилам:
Существует единственный сегмент верхнего уровня, называемый корнем. Корневой сегмент - это тип сегмента, не участвующий в качестве потомка ни в одном отношении предок-потомок.
За исключением корневого сегмента, каждый сегмент входит в качестве потомка ровно в один тип отношений предок-потомок.
Сегмент может участвовать в качестве предка в нескольких типах отношений предок-потомок.
Каждый сегмент-потомок обладает только одним сегментом-предком. Это означает, что отношение между предком и потомком в дереве имеет мощность один-ко-многим.
Сегмент, у которого нет потомков, называется листовым сегментом.
Для любого типа сегмента А существует единственный путь в дереве от корня до А. Записи этого пути называются предшественниками А.
Предшественник. В иерархии тип сегмента, находящийся на том же пути, что и данный, но на более высоком уровне дерева.
Зависимый тип сегмента. Все типы сегментов, отличные от корневого.
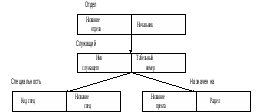
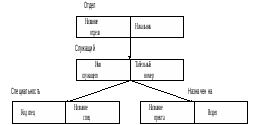
Рисунок является примером трехуровневого дерева. В данном случае дерево состоит из типов сегментов ОТДЕЛ, СЛУЖАЩИЙ, СПЕЦИАЛЬНОСТЬ и НАЗНАЧЕН-НА и их отношений. Иерархическая схема базы данных - это совокупность такого рода деревьев с корнями. Каждое такое дерево называется деревом базы данных. Вхождение корня и всех его зависимых сегментов называется записью базы данных.
Каждый тип сегмента может иметь множество соответствующих ему экземпляров. Между экземплярами сегментов также существуют иерархические связи.
Экземпляры-потомки одного типа, связанные с одним экземпляром сегмента-предка, называют «близнецами». Так, для нашего примера экземпляры b1, b2 и bЗ являются «близнецами», но экземпляр b4 не является «близнецом» по отношению к экземплярам b1, b2 и bЗ. Набор всех экземпляров сегментов, подчиненных одному экземпляру корневого сегмента, называется физической записью.
Лекция 7
«Реляционная модель данных. Особенности реляционной модели. Правила Кодда»
Реляционная модель данных
Реляционная модель данных в настоящее время используется в большинстве коммерческих СУБД.
Сотрудник фирмы IBM д-р Э.Кодд, математик по образованию, в 1970 году предложил использовать для обработки данных аппарат теории множеств (объединение, пересечение, разность, декартово произведение). Он показал, что любое представление данных сводится к совокупности двумерных таблиц особого вида, известного в математике как отношение (relation).
Предложенная в 1970 году Е.Ф.Коддом реляционная модель позволила пользователю не заботиться о физической структуре данных и не интересоваться ею. Кодд ввел два языка манипулирования данными - реляционная алгебра и реляционное исчисление, которые предлагали более эффективные средства доступа к данным и их обработки и сегодня являются основой коммерческих СУБД.
Наименьшая единица данных реляционной модели - это отдельное атомарное (неразложимое) для данной модели значение данных. Так, в одной предметной области фамилия, имя и отчество могут рассматриваться как единое значение, а в другой - как три различных значения.
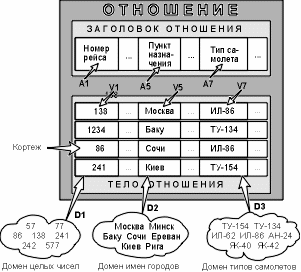
Домен - это некоторое множество элементов, например, множество значений, которые может принимать объект.
Например, домен пунктов отправления (назначения) - множество названий населенных пунктов, а домен номеров рейса - множество целых положительных чисел.
Декартово произведение К доменов:
D=D1 x D2 x ... Dk
это множество всех кортежей длины К, то есть состоящих из К элементов, по одному из каждого домена.
Таким образом, декартово произведение позволяет получить все возможные комбинации элементов исходных множеств. Например,
D1 = {A,2} D2 = {B,C} D3 = {4,5,D}
D= D1 x D2 x D3 = { (A,B,4), (A,B,5), (A,B,D), (A,C,4), (A,C,5), (A,C,D), (2,B,4), (2,B,5), (2,B,D), (2,C,4), (2,C,5), (2,C,D) }
Отношением R на множествах D1 D2 Dk называется подмножество их декартова произведения.
Элементами отношения являются кортежи.
Поскольку декартово произведение не содержит совпадающих элементов, то никакие два кортежа отношения не могут быть дубликатами друг друга в любой произвольно-заданный момент времени.
Отношение на доменах D1, D2, ..., Dn состоит из заголовка и тела. На рисунке приведен пример отношения для расписания движения самолетов.
Заголовок состоит из такого фиксированного множества атрибутов A1, A2, ..., An, что существует взаимно однозначное соответствие между этими атрибутами Ai и определяющими их доменами Di (i=1,2,...,n).
Отношение с математической точки зрения (Ai - атрибуты, Vi - значения атрибутов)
Тело состоит из меняющегося во времени множества кортежей, где каждый кортеж состоит в свою очередь из множества пар атрибут-значение (Ai:Vi), (i=1,2,...,n), по одной такой паре для каждого атрибута Ai в заголовке. Для любой заданной пары атрибут-значение (Ai:Vi) Vi является значением из единственного домена Di, который связан с атрибутом Ai.
Степень отношения - это число его атрибутов.
Кардинальное число или мощность отношения - это число его кортежей. Кардинальное число отношения изменяется во времени в отличие от его степени.
В ряде случаев отношение удобно представить как таблицу, где каждая строка - кортеж, а каждый столбец - домен. Любые две строки в отношении должны отличаться хотя бы одним элементом.
Отношение используется для представления набора объектов и для представления связей между наборами объектов. Каждый кортеж - отдельный объект, а атрибуты набора объектов - домены.
Список имен атрибутов или заголовок называют схемой отношения:
R(A1,A2,...,An)
Реляционная база данных - это набор экземпляров отношений.
Эти математические понятия явились теоретической базой для создания реляционных СУБД, однако, для массового пользователя реляционных СУБД можно с успехом использовать неформальные эквиваленты этих понятий:
Отношение - Таблица (иногда Файл),
Кортеж - Строка (иногда Запись),
Домен - Столбец, Атрибут, Поле.
При этом принимается, что "запись" означает "экземпляр записи", а "поле" означает "имя и тип поля".
Реляционная база данных - это совокупность отношений, содержащих всю информацию, которая должна храниться в БД. Однако пользователи могут воспринимать такую базу данных как совокупность таблиц.
Лекция 8
«Реляционная модель данных: элементы структуры, основные операции над данными и ограничения целостности. Виды отношений и ключей»
Атрибуты и ключи
В некоторых кортежах конкретный атрибут может быть неприменим, или его значение неизвестно и будет введено позже, тогда атрибуту приписывается пустое значение (это не пробел и не ноль). Пустое значение - это значение, приписываемое атрибуту в кортеже, если он неприменим или его значение неизвестно.
Основное ограничение для реляционной модели - это невозможность кортежей-дубликатов.
Потенциальным ключом называется минимальный набор атрибутов, однозначно определяющий кортежи. Каждое отношение имеет хотя бы один потенциальный ключ, в крайнем случае, состоящий из всех атрибутов. Ключ, содержащий более одного атрибута, называется составным.
В некоторых сущностях возможно наличие нескольких потенциальных ключей. В этом случае один из них будет первичным ключом, а остальные - альтернативными ключами. В качестве первичного выбирают тот из потенциальных ключей, который имеет минимальный набор атрибутов, минимальную длину и т.п.
Набор атрибутов, являющийся ключом другой (или той же самой таблицы), который используется для индикации логических связей между таблицами, называется внешним ключом.
В реляционной модели Кодда есть несколько ограничительных условий, используемых для проверки данных в базе данных, а также для придания данным осмысленной структуры.
Категорная целостность. Никакой ключевой атрибут строки не может быть пустым.
Целостность на уровне ссылок. Значение непустого внешнего ключа должно быть равно одному из текущих значений ключа другой таблицы.
Выполнение операций над отношениями
Для получения информации из отношений необходим язык манипулирования данными, на котором формулируются запросы. Коддом были предложены два языка - реляционная алгебра и реляционное исчисление. Реляционная алгебра - это процедурный язык обработки реляционных таблиц, он обеспечивает пошаговое выполнение задачи. Реляционное исчисление - непроцедурный язык создания запросов, он позволяет формулировать, что нужно сделать, а не как этого добиться. Кодд показал, что реляционная алгебра и реляционное исчисление логически эквивалентны. Это означает, что любой запрос, который можно сформулировать при помощи реляционного исчисления, можно выполнить и при помощи реляционной алгебры, и наоборот.
Лекция 9
«Основы реляционной алгебры. Операции над отношениями»
Реляционная алгебра
Операции реляционной алгебры используют одну или две существующие таблицы для создания новой таблицы.
Рассмотрим операции реляционной алгебры на примере двух отношений R1 и R2.
R1 R2
а в г и к л
д е ж с о б
и к л
-
Объединение отношений R1 и R2. Создает новую таблицу, содержащую кортежи обеих исходных таблиц. При этом любая строка, существующая в обеих таблицах, появляется в таблице объединения только один раз. Важным условием объединения является то, что таблицы должны быть объединительно - совместимыми, то есть иметь эквивалентные столбцы с точки зрения их количества и областей.
R = R1 R2
а в г
д е ж
и к л
с о б
-
Разность отношений R1 и R2. Позволяет идентифицировать те строки, которые есть в одной таблице, но отсутствуют в другой.
R = R1 - R2
а в г
д е ж
-
Декартово произведение R1 и R2. Создается путем связывания или соединения атрибутов двух таблиц, а затем присоединения к каждой строке таблицы R1 каждой строки таблицы R2. Если R1 имеет арность к1, а R2 - к2, то декартово произведение будет иметь арность к1+к2. Первые к1 элементов из R1, последние к2 элементов из R2
R = R1 х R2
а в г и к л
д е ж и к л
и к л и к л
а в г с о б
д е ж с о б
и к л с о б
-
Проекция отношения R1 на компоненты i1,i2,...,ir. Создает новую таблицу путем исключения столбцов из существующей таблицы.
R = i1,i2,...,ir (R1), где i1,i2,...,ir - номера столбцов отношения R1.
R = 1,3 (R1) а г
д ж
и л
-
Селекция отношения R1 по формуле F. Производит отбор строк из таблицы на основании некоторого условия.
R = F (R1), где F - формула, образованная номерами столбцов и логическими операторами.
R = 1=а 1=и (R1)
а в г
и к л
-
Пересечение отношений R1 и R2. Позволяет идентифицировать строки, общие для двух таблиц.
R = R1 R2
R и к л
-
Деление отношений R1 и R2. Создает новую таблицу путем выбора строк одной таблицы, соответствующих каждой строке другой таблицы.
R = R1 R2
R1 и о р к R2 с а R и о
о р с а р к с к
и о с а
с к с а
и о к с
-
Соединение отношений R1 и R2. Обратно проекции. Это операция, при которой соединяют два отношения, используя в качестве признака соединения общий атрибут.
R = R1 R2
Соединение имеет несколько версий: естественное соединение, тета - соединение и внешнее соединение.
Естественное соединение - это операция, связывающая таблицы, когда общие столбцы имеют равные значения. Берется произведение таблиц R1 и R2. Из таблицы произведения исключаются все строки, кроме тех, где значения соединяемых столбцов обеих таблиц равны. Проектированием исключается одна копия столбцов соединения.
R1 а в с R2 а и R по столбцам 2 и 1
а и р е к д е ж е к
д е ж
Тета - соединение позволяет задавать условие соединения строк. В отличие от естественного соединения тета - соединение не включает удаление одного или более столбцов на последнем шаге.
Внешнее соединение расширяет естественное соединение, гарантируя, что каждая запись из обеих таблиц будет представлена в таблице соединения хотя бы один раз. Внешнее соединение выполняется в два этапа. Сначала выполняется естественное соединение, затем, если какая-либо строка одной из исходных таблиц не подходит ни к одной строке другой таблицы, она включается в таблицу соединения, а все дополнительные столбцы заполняются пустыми значениями.
R а в с _ _
а и р _ _
д е ж е к
_ _ _ а и
-
Присвоение - это операция реляционной алгебры, дающая имя таблице.
Реляционное исчисление
Исчисления выражают только то, каким должен быть результат вычмсления, а не то, каким образом его производить.
Запрос в реляционном исчислении состоит из целевого списка и определяющего выражения, разделенных двоеточием. Фигурные скобки, в которые заключено выражение, означают, что ответом на запрос будет множество значений данных.
Целевой список определяет атрибуты таблицы решения. Атрибуты в нем разделяются запятой.
Определяющее выражение задает условие, ограничивающее вхождение элементов в таблицу решения.
В реляционном исчислении используются квантор существования 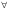 и квантор всеобщности
и квантор всеобщности 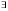 .
.
Квантор существования означает, что существует хотя бы один экземпляр определенного вида вещей. В реляционном исчислении он используется для задания условия того, что определенный тип строк в таблице существует.
Квантор всеобщности означает, что некоторое условие применяется к каждой строке определенного типа.
Раздел 2. Принципы проектирования реляционной базы данных
Тема 2.1. Концептуальный и логический уровни описания баз данных
Лекция 10
«Основные принципы проектирования баз данных. Этапы проектирования: инфологическое моделирование, даталогическое проектирование, физическое проектирование»
Проектирование баз данных
Жизненный цикл БД
Включает в себя:
-
проектирование БД и приложений,
-
реализация,
-
загрузка данных,
-
тестирование,
-
разработка средств администрирования БД,
-
эксплуатация БД.
Этапы и основные принципы проектирования баз данных
Процесс проектирования состоит в переходе от одного уровня абстракции в представлении данных к другому. Этот процесс представляют последовательностью более простых, обычно интерактивных, процессов проектирования менее сложных отображений между промежуточными моделями данных.
Задача системного анализа предметной области заклбчается в определении целей создания системы, изучении предметной области и определении требований пользователей.
Определяются границы предметной области, отбрасываются несущественные части. Накапливаются знания о предметной области. Описание обычно делается на естественном языке.
Задача инфологического этапа проектирования - получение семантических (смысловых) моделей, отражающих информационное содержание предметной области.
Главными элементами концептуальной модели являются объекты и их отношения. Объекты часто представляются в виде существительных, а отношения в виде глаголов. На этом этапе определяются объекты, то есть те вещи, которые пользователи считают особенно важными, их свойства и связи между ними.
Затем составляется инфологическая концептуальная модель в соответствии с требованиями пользователей. Описывается информация, требуемая каждому конкретному пользователю, то есть запросы к базе данных. Формируются описания внешних инфологических моделей, их взаимная увязка с инфологической концептуальной моделью.
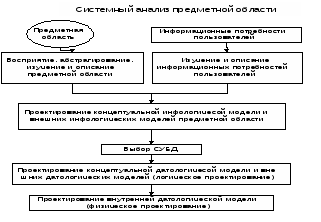
Полученные описания отражают составляющие предметной области, связи между ними. Эти описания не должны зависеть от методов представления данных и от конкретной СУБД. Концептуальная инфологическая модель должна обеспечивать прочную и долговременную работу всей системы, выдерживать замену одной СУБД на другую.
Задача логического этапа проектирования - организация данных, выделенных на предыдущем этапе, в форму, выбранную в конкретной СУБД.
Инфологическая модель должна быть отображена в компьютеро-ориентированную даталогическую модель, "понятную" СУБД. В процессе развития теории и практического использования БД создавались СУБД, поддерживающие различные даталогические модели.
Иными словами, требуется разработать схему концептуальной и внешних моделей данных, пользуясь только теми типами данных и их особенностями, которые поддерживаются данной СУБД. На этом этапе обычно не прорабатываются вопросы, связанные с организацией хранения и доступа к данным на внутреннем уровне, но методы доступа выбираются.
Задача физического этапа проектирования - выбор рациональной структуры хранения данных и методов доступа к ним, исходя из арсенала методов и средств, который предоставляется данной СУБД.
Системный анализ предметной области
При проектировании информационной системы необходимо провести анализ целей этой системы и выявить требования к ней отдельных пользователей.
В рамках системного анализа необходимо провести подробное словесное описание объектов предметной области и реальных связей, которые между ними существуют.
При проектировании банков данных для определения границ предметной области используются два подхода: функциональный или «от запросов пользователей» и предметный или «от реального мира».
Функциональный подход применяется тогда, когда заранее известны функции некоторой группы лиц или комплексов задач, для обслуживания которой создается БД. В этом случае можно четко выделить набор объектов предметной области, которые должны быть описаны.
Предметный подход применяется тогда, когда информационные потребности пользователей БД жестко не фиксируются. Они могут быть разнообразными и динамичными. В этом случае невозможно выделить мимнимальный набор объектов предметной области, которые необходимо описывать и в описание включаются те объекты и взаимосвязи, которые наиболее существенны для данной предметной области. Созданная таким образом БД может быть использована при решении множества разнообразных, заранее не определенных задач. Однако, при таком подходе возможно создание настолько сложной БД, что она окажется неэффективной для конкретных задач.
Чаще всего используется комбинированный подход, который позволяет учесть конкретные потребности пользователей и в то же время предусматривает возможность наращивания новых приложений для создаваемой БД.
Лекция 11
«Информационно-логическое моделирование. Понятие и назначение ER-модели. Изобразительные средства, используемые в ER-моделировании»
Инфологическое проектирование
Инфологическая модель отображает реальный мир в некоторые понятные человеку концепции, полностью независимые от параметров среды хранения данных. Существует множество подходов к построению таких моделей: графовые модели, семантические сети, модель "сущность-связь" и т.д. Наиболее популярной из них оказалась модель "сущность-связь".
В инфологическом подходе выделяются:
Сущность (Объект) - это то, о чем должна накапливаться информация в системе. Необходимо различать такие понятия, как тип сущности и экземпляр сущности. Типом сущности иди объектным множеством будем называть множество вещей одного типа, например, ГОРОД. Экземпляром сущности или объектом-элементом будем называть конкретный элемент объектного множества (Москва, Киев).
Некоторые объектные множества содержатся внутри других объектных множеств (МУЖЧИНА - ЧЕЛОВЕК).
Конкретизация. Объектное множество, являющееся подмножеством другого объектного множества.
Обобщение. Объектное множество, являющееся надмножеством другого объектного множества(содержащее его).
Объекты могут быть атомарными или составными, причем объект может в одном приложении быть атомарным, а в другом - составным. Для составного объекта должны быть определены его внутренние составляющие.
Каждый объект в определенный момент времени характеризуется определенным состоянием. Это состояние описывается с помощью набора свойств и связей с другими объектами.
Свойства объекта могут не зависеть от его связей (отношений) с другими объектами. Такие свойства называются локальными. Свойства, которые зависят от связей с другими объектами, называются реляционными.
Связь(отношение) между объектами в зависимости от числа входящих в нее объектов характеризуется мощностью. Мощность - это максимальное количество элементов одного объектного множества, связанных с одним элементом другого объектного множества. Некоторые отношения не имеют конкретного значения максимальной мощности, тогда мощность обозначают *, т.е. "много".
Модель "Сущность - Связь"(ERD)
Это модель предметной области, которая используется на этапе инфологического проектирования. Нотация ERD была впервые введена П. Ченом (Chen).
Модель использует три основных элемента: сущность, атрибут и связь.
Сущность - это абстракция какого-либо объекта, процесса или явления реального мира, о котором нужно хранить информацию. В качестве сущности могут выступать материальные (предприятие, товар) и нематериальные (описание явления, реферат статьи) объекты.
Тип сущности определяет набор однородных объектов, а экземпляр сущности - конкретный объект в наборе.
Каждый тип сущности обладает одним или несколькими атрибутами.
Каждому типу сущности должно быть дано уникальное имя. К одному и тому же имени должна всегда применяться одна и та же интерпретация.
Для идентификации конкретных экземпляров сущностей используются атрибуты - идентификаторы (один или несколько), которые позволяют однозначно отличать один экземпляр сущности от другого.
Каждая сущность может обладать любым количеством связей с другими сущностями модели.
Атрибут - это поименованная характеристика сущности, которая принимает значения из некоторого множества значений. Например, для сущности КНИГА атрибутами являются Автор, Наименование, Год издания и т.п.
Чтобы задать атрибут в модели, необходимо присвоить ему наименование, привести смысловое описание атрибута, определить множество его допустимых значений и указать, для чего он используется.
Основное назначение атрибута - описание свойства сущности, а также идентификация экземпляров сущности. Атрибут можно использовать и, так как связь - это тоже признак сущности.
Атрибут может быть либо обязательным, либо необязательным. Обязательность означает, что атрибут не может принимать неопределенных значений (null values). Атрибут может быть либо описательным (т.е. обычным дескриптором сущности), либо входить в состав уникального идентификатора (первичного ключа).
Первичный ключ - набор атрибутов, значения которого однозначно определяют экземпляр сущности.
Внешний ключ - это набор атрибутов, используемый для представления связей между сущностями.
Связи - поименованная ассоциация между двумя сущностями, значимая для рассматриваемой предметной области. Связь - это средство, с помощью которого представляются отношения между сущностями, имеющие место в предметной области. Связи может даваться имя, выражаемое грамматическим оборотом глагола. Имя каждой связи между двумя данными сущностями должно быть уникальным, но имена связей в модели не обязаны быть уникальными.
Связи могут быть между двумя (бинарные), тремя (тернарные) и более сущностями. Чаще всего используются бинарные. Они классифицируются следующим образом:
Связь "один - к - одному" (отображение 1:1)
Когда каждому экземпляру сущности А соответствует один и только один экземпляр сущности Б, и наоборот. Связь двунаправленная.

Связь "один -ко - многим" (отображение 1:М)

Это такой тип связи, когда каждому экземпляру сущности А может соответствовать ни одного, один или несколько экземпляров сущности Б, однако каждому экземпляру сущности Б соответствует один и только один экземпляр сущности А.
Связь "многие - к - одному" (отображение М:1)
Это отображение обратно предыдущему.
Связь "многие - ко - многим" (отображение М:N)
Это такой тип связи, при котором каждому экземпляру сущности А может соответствовать ни одного, один или несколько экземпляров сущности Б, и наоборот.

В некоторых случаях целесообразно рассматривать однонаправленную связь от сущности А к сущности Б. Она может быть простой и многозначной.
При простой однонаправленной связи от А к Б одному и тому же экземпляру А соответствует один и тот же экземпляр Б. При этом обратная связь не определена.

При многозначной однонаправленной связи от А к Б, одному и тому же экземпляру А соответствует ни одного, один или несколько экземпляров Б. Обратная связь не определена.
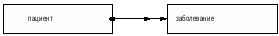
Во многих случаях интересен не сам факт отношения, а его мощность, выраженная в числовой форме. Она называется показателем и широко используется в управленческой деятельности. В этих случаях тип отношения можно рассматривать как тип сущности и он может иметь описательные атрибуты. Например, "Деталь А - размещена - на складе Б" рассматриваем как сущность, о которой хотим хранить информацию о количестве деталей на складе (атрибут - количество).
Информацию о проекте оформляют составлением спецификаций по сущностям, атрибутам и отношениям с использованием графических диаграмм. На диаграмме обозначают:
-
сущности - прямоугольниками;
-
атрибуты - овалами, соединяя их с соответствующими сущностями ненаправленными ребрами; идентифицирующие атрибуты подчеркиваются;
-
связи (отношения) - ромбами, соединяя их с соответствующими сущностями ненаправленными ребрами, за исключением бинарных связей, которые соединяются направленными ребрами.
При моделировании используются следующие общие правила:
-
используются только три типа конструктивных элементов - сущность, атрибут и связь;
-
в отдельном проектном представлении каждый компонент информации моделируется только одним конструктивным элементом, то есть необходимо избегать избыточности.
Структурный подход при разработке инфологической модели
Сущность структурного подхода к разработке ИС заключается в ее декомпозиции (разбиении) на автоматизируемые функции: система разбивается на функциональные подсистемы, которые в свою очередь делятся на подфункции, подразделяемые на задачи и так далее. Процесс разбиения продолжается вплоть до конкретных процедур. При этом автоматизируемая система сохраняет целостное представление, в котором все составляющие компоненты взаимоувязаны. При разработке системы "снизу-вверх" от отдельных задач ко всей системе целостность теряется, возникают проблемы при информационной стыковке отдельных компонентов. При моделировании предметной области проектировщик разбивает ее на ряд локальных областей, моделирует каждое локальное представление, а затем их объединяет.
Моделирование локальных представлений
Выбор локального представления зависит от масштабов предметной области. Для удобства проектирования желательно использовать в отдельных локальных представлениях шесть - семь сущностей.
1. Формулирование сущностей
На этом этапе необходимо указать типы объектов, о которых нужно хранить информацию. Иногда это сложно сделать, так как отдельный объект можно представить и в виде сущности, и в виде атрибута и в виде связи. Тогда следует проработать несколько вариантов моделей и выбрать наиболее гибкий.
Каждой выбранной сущности должно быть присвоено четкое наименование. Общее их количество не должно быть большим.
2. Выбор идентифицирующего атрибута для каждой сущности.
Необходимо для каждой сущности указать идентификатор, позволяющий однозначно распознавать экземпляры сущности. Это один или несколько атрибутов, называемых ключом. Если в наборе атрибутов такого нет, то его надо ввести. Обычно в этом случае для каждого экземпляра сущности вводится внутренний номер, не имеющий смысла вне системы. Он называется суррогатным ключом.
Один и тот же набор объектов может иметь несколько ключей. Один из них является первичным. Это ключ, который однозначно идентифицирует отдельные экземпляры сущности. Первичный ключ должен включать в свой состав минимальное количество атрибутов. Ключ, состоящий их нескольких атрибутов, называется составным.
3. Назначение сущностям описательных атрибутов
Спецификация атрибутов заканчивается указанием для каждого атрибута множества значений, которые он может принимать (пул, домен). Если это множество бесконечное, то оно задается указанием типа значений (числовой, символьный и пр.) и диапазона значений для чисел и количества символов для алфавитно-цифровых значений.
4. Спецификация связей
Выявляются зависимости между двумя и более сущностями. Определяется какие из них необходимые, какие избыточные. Каждый тип связи именуется. Кроме связей "сущность-сущность" специфицируются связи типа "сущность-атрибут" и "атрибут-атрибут". Связей "атрибут-атрибут" нужно избегать.
Объединение моделей локальных представлений
При объединении моделей локальных представлений проектировщик вводит в рассмотрение понятия более высокого уровня по отношению к понятиям, используемым в локальных представлениях. Это делается с целью:
-
объединить представления о различных свойствах одного и того же объекта;
-
устранить несущественные различия в представлении подобных объектов;
-
ввести абстрактные понятия, удобные для решения задач системы, и установить их связи с конкретными понятиями, использованными в модели;
-
образовать классы и подклассы подобных объектов и ввести соответствующие понятия.
Вводимые производные конструкции должны обеспечивать непротиворечивое представление данных.
Перед объединением необходимо определить его порядок. Например, имеется N моделей локальных представлений. Можно попытаться выполнить объединение за один шаг. Это возможно, если количество локальных моделей невелико - не более четырех. Если их больше, то задача усложняется, растут временные затраты, возрастает возможность ошибок и упущений. Поэтому число шагов объединения увеличивают, уменьшая число объединяемых моделей на одном шаге. Обычно используется попарное объединение. Если перед объединением выполнить группировку локальных представлений, то это еще больше упростит задачу.
При объединении представлений используются три основополагающих концепции: идентичность, агрегация и обобщение.
Два или более элементов идентичны, если имеют одинаковое семантическое(смысловое) значение.
Агрегация - позволяет рассматривать связь между элементами модели как новый элемент.
Например, связь между сущностями СТУДЕНТ, ПРЕДМЕТ, ПРЕПОДАВАТЕЛЬ, имеющая смысловое описание "Студент ... получил на экзамене по предмету ... у преподавателя ... оценку ...", может быть представлена агрегатированным элементом - сущностью ЭКЗАМЕН с атрибутами ФИО_студента, Название_предмета, ФИО_преподавателя, Код_оценки.
Обобщением называется абстракция данных, позволяющая трактовать класс подобных объектов, как один поименованный тип объектов. В обобщении подчеркивается общая природа объектов. При этом у объекта могут появиться новые свойства. Применение обобщений позволяет повысить гибкость системы для совместного использования данных, значительно сократить пространство поиска.
Процесс объединения носит интерактивный характер, так как в процессе объединения выявляются противоречия между отдельными локальными представлениями. Часть противоречий обычно вызвана некорректностью требований, неточностью спецификаций, ошибками при проектировании локальных представлений. Другая часть противоречий связана с различием требований в отдельных приложениях. Их необходимо согласовать, скорректировать локальные представления и вновь выполнить объединение. Этот процесс продолжается до тех пор, пока не будут объединены все представления, устранены все противоречия.
Результатом этого этапа проектирования является инфологическая концептуальная модель предметной области, оформленная в виде графических диаграмм и соответствующих спецификаций. Сформированные спецификации вводятся в словарь данных системы.
Лекция 12
«Избыточность данных и аномалии обновления в базе данных. Функциональные зависимости между атрибутами»
Функциональные зависимости между атрибутами
Пусть X и Y - атрибуты отношения R. Атрибут Y функционально зависит от атрибута Х, если в каждый момент времени одному и тому же значению Х соответствует одно и то же значение Y. Х -> Y. Например, одному и тому же значению номера табельного в отношении СОТРУДНИК соответствует одно и то же значение атрибута "возраст".
Неполная функциональная зависимость возникает, если в состав ключа входит два и более атрибутов. Таким образом, имеются атрибуты, зависящие не от всех атрибутов, входящих в ключ - это неполная функциональная зависимость. Например,
ПРЕПОДАВАТЕЛЬ(ФИО, КАФЕДРА, ВОЗРАСТ, ПРЕДМЕТ)- неполная функциональная зависимость существует между ключом и атрибутом "возраст".
Транзитивная зависимость возникает между атрибутами А и С, если атрибут В функционально зависит от атрибута А, а атрибут С функционально зависит от атрибута В.
Существует также многозначная зависимость, когда при заданных значениях атрибутов А существует взаимосвязанное множество значений атрибутов из В. Например, СТУДЕНТ(N_таб, ОЦЕНКА, ПРЕДМЕТ); ОБУЧЕНИЕ(Предмет, Преподаватель, Учебник)- между атрибутами Предмет-Преподаватель и Предмет-Учебник.
Лекция 13
«Нормализация отношений. Преобразование ER-модели в схему реляционной базы данных»
Логическое проектирование на примере реляционной модели данных
Нормализация отношений
Существует большое количество вариантов группировки атрибутов в отношения. Проблема в том, чтобы выбрать из них самый рациональный, который будет отвечать следующим требованиям:
-
Выбранные для отношений первичные ключи должны быть минимальными;
-
Выбранный состав отношений базы должен быть минимальным, то есть отличаться минимальной избыточностью атрибутов;
-
При выполнении операций включения, удаления, модификации данных в базе данных не должно возникать аномалий;
-
Перестройка набора отношений при добавлении новых типов данных должна быть минимальной;
-
Разброс времени ответа на различные запросы пользователей должен быть небольшим.
Аномалии (трудности) при включении, удалении, модификации данных при неправильном проекте базы данных заключаются в следующем. Например, имеется база данных со схемой:
ПОСТАВКА (Назв_поставщика, Адрес, Товар, Количество, Цена)
Аномалия модификации. Если у поставщика изменится адрес, необходимо изменить его во всех кортежах, где встречается этот поставщик, а если этого не произойдет, возникнет противоречивость.
Аномалия удаления возникает при попытке удаления всех кортежей, где есть поставки от какого-либо поставщика. В системе теряется его название и адрес, хотя с ним по-прежнему заключен договор о поставках.
Аномалия включения возникает в том случае, если с поставщиком заключен договор, а поставок еще не было.
Чтобы решить подобные вопросы выполняется нормализация исходных схем отношений, их композиция или декомпозиция и назначение ключей для каждого отношения.
Нормальные формы схем отношений
Введено пять уровней нормализации схем отношений и пять нормальных форм: 1НФ, 2НФ, 3НФ, 4НФ, 5НФ, которые подчиняются правилу вложенности по возрастанию номеров, то есть если отношение находится в 4НФ, то оно находится и в 3НФ, и во 2НФ, и в 1НФ.
1НФ - все входящие в отношение атрибуты должны быть атомарными (не составными)и ни одно из ключевых полей не должно быть пустым. Другими словами в позиции на пересечении каждой строки и столбца таблицы всегда находится единственное атомарное значение, и никогда не может быть множества таких значений. Для работы языков запросов этого достаточно, остальные нормальные формы предназначены для того, чтобы выполнить требования 1-5 к базе данных.
2НФ - если схема отношения находится в 1НФ, и каждый ее непервичный атрибут функционально полно зависит от первичного ключа. Отношение во 2НФ может обладать аномалиями включения, удаления, модификации.
3НФ - если схема отношения находится во 2НФ и каждый ее непервичный атрибут нетранзитивно зависит от первичного ключа.
НФБК - нормальная форма Бойса-Кодда - отношение, в котором каждый детерминант является потенциальным ключом. Детерминантом называется любой атрибут, от которого функционально полно зависит другой атрибут. Если в отношении один потенциальный ключ, то НФБК и 3НФ эквивалентны. Нарушение требований НФБК происходит, если имеется два или более потенциальных ключей и они перекрываются, т.е. имеют хотя бы один общий атрибут.
4НФ - если схема отношения находится в 3НФ и в ней отсутствуют многозначные зависимости. В отношении в 4НФ отсутствуют аномалии включения, удаления, модификации.
5НФ - схема отношения в 4НФ и в ней отсутствуют зависимости соединения. Зависимость соединения - свойство декомпозиции, которое вызывает генерацию ложных строк при обраном соединении декомпозированных отношений с помощью естественного соединения.
Схема процесса нормализации
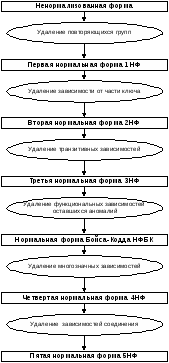
Нормализация отношений выполняется декомпозицией их схем, т.е. разбиением таблицы на несколько, обладающих лучшими свойствами при обновлении, включении и удалении данных. Нормализация - это процесс последовательной замены таблицы ее полными декомпозициями до тех пор, пока все они не будут находиться в 5НФ. На практике обычно достаточно привести таблицы к НФБК и с большой гарантией считать, что они находятся в 5НФ
Процедура логического проектирования для реляционной модели данных
-
Преобразование каждого локального представления (внешней инфологической модели) в локальную логическую модель. Инфологическая модель может содержать такие структуры данных, которые не реализуются выбранной СУБД. На этом этапе:
-
удаляются избыточные связи,
-
удаляются связи «многие-ко-многим», сложные связи между тремя и более сущностями, связи, имеющие атрибуты, рекурсивные связи (связь сущности с самой собой) путем введения новых сущностей;
-
объединяются сущности, имеющие связь «один-к-одному»
-
Определение набора отношений, исходя из инфологической модели данных. Каждое отношение необходимо представить таблицей базы данных и специфицировать первичный ключ этой базовой таблицы и альтернативные ключи. Связи, которые установлены между сущностями, определяются с помощью внешних ключей. Необходимо установить, какая таблица является родительской, а какая дочерней. Для связи типа «один-ко-многим» таблица, которая является «единичной» стороной связи, будет родительской, а таблица, которая является «множественной» стороной связи, будет дочерней.
-
Нормализация отношений.
-
Проверка модели в отношении транзакций пользователей. Цель этого этапа состоит в том, чтобы проверить, что все транзакции, определяемые действиями пользователя данной модели, могут быть реализованы. Используя модель «сущность-связь», установленные в описании таблиц внешние ключи, нужно попытаться выполнить все необходимые транзакции вручную. При этом необходимо проверить, что для всех элементов данных, которые участвуют в данной транзакции, имеются соответствующие поля в таблице или к ним можно получить доступ с помощью установленных связей. Если это не удается, нужно устранить ошибки.
-
Составление окончательного варианта модели «сущность-связь».
-
Определение требований поддержки целостности данных. Реализация этих требований может осуществляться либо СУБД, если она поддерживает ограничения такого рода, либо прикладными программами.
-
Создание и проверка глобальной логической модели данных.
Тема 2.2. Физическое проектирование баз данных
Лекция 14
«Физическое проектирование. Особенности, влияющие на организацию внешней памяти. Технологии хранения данных»
Физическое проектирование базы данных
Функциональные возможности различных СУБД значительно отличаются друг от друга, поэтому физическое проектирование всегда тесно связано с особенностями выбранной СУБД.
Этапы физического проектирования:
-
Перенос глобальной логической модели в среду выбранной СУБД. На этом этапе выполняется создание таблиц БД и реализация бизнес-правил в среде СУБД.
-
Проектирование физического представления БД. На этом этапе проводится анализ транзакций (их частота, время ответа), выбор файловой структуры и могут быть внесены изменения в структуру БД для достижения наибольшей эффективности (вторичные ключи, избыточность). Определяются требования к дисковой памяти.
-
Разработка механизмов защиты: разработка пользовательских представлений, определение прав доступа.
-
Организация мониторинга и настройка функционирования системы. Данные о производительности системы, полученные в результате мониторинга, анализируются с целью устранения ошибочных решений или внесения изменений для повышения производительности.
Файловые структуры баз данных
Эффективность функционирования СУБД во многом определяется выбором способа организации.
Существует 6 основных способов организации:
-
последовательные файлы;
-
файлы прямого доступа;
-
индексные;
-
инвертированные списки;
-
взаимосвязанные файлы..
Для каждого файла в системе управления файлами имется заголовок или справочная запись. Эта запись содержит информацию: имя файла, тип файла, размер записи, количество занятых физических блоков, базовый начальный адрес, ссылка на сегмент расширения, способ доступа. Набор справочных записей, в свою очередь, также образует файл, хозяином которого является операционная система.
Команда "открыть файл" означает чтение справочной записи в оперативной памяти в момент первого обращения к файлу и хранение ее для последующих ссылок.
Если в файле производятся изменения, они отражаются в справочной записи.
При завершении использования файла эта запись заносится в файл справочных записей - команда "закрыть файл".
Последовательный файл
Записи в нем расположены в определенной последовательности, Записи последовательного файла могут иметь и фиксированную и переменную длину.
Добавление записей. Новые записи собираются в файл транзакций до тех пор, пока он не станет достаточно большим. Затем осуществляется пакетное обновление, то есть слияние двух файлов.
Поиск производится последовательным перебором записей и сравнением ключевого атрибута с критерием поиска. Если файл на магнитном диске, то можно использовать двоичный поиск для того атрибута, по которому файл был упорядочен.
Двоичный поиск. Всякий раз, когда осуществляется выборка блока записей, анализируется его первая и последняя запись. Если искомая запись находится в этом блоке, то она выбирается путем просмотра записей, а если нет - читается следующий блок.
Зондирование. Это способ поиска, применяемый, если аргумент поиска является ключом упорядочения. Вначале делается прямая выборка путем количественной оценки, затем последовательный просмотр.
Обновление(модификация). Если у новой записи то же значение ключа, что и у старой, то она записывается на место старой; если нет, то старая удаляется (помечается для удаления), а новая записывается в файл транзакций.
Полное считывание - считывается основной файл и файл транзакций.
Реорганизация. Файл транзакций упорядочивается. Создается новый файл путем объединения старого и файла транзакций, при этом исключаются записи, помеченные для удаления.
Файлы с прямым доступом
Все записи имеют фиксировааную длину. Каждой записи приписывается идентификационный номер, который позволяет вычислить адрес записи на диске. Специальная вычислительная процедура (существует несколько способов) служит для преобразования ключа в адрес.
Выборка записи производится путем преобразования ключа в адрес.
Добавление и модификация записи состоит из поиска по ключу и изменения значений атрибутов.
Используется прямой файл для различных справочников, списков, когда заранее можно определить общее количество записей файла. Прямой файл имеет записи фиксированной длины и обеспечивает к ним быстрый доступ. Если можно построить функцию, которая бы однозначно определяла по значению ключа номер записи, то можно использовать прямой доступ. (№ таб)
Однако, не всегда можно хранить информацию в таком виде. В БД обычно нужен поиск записи по значению ключа, а не по номеру записи.
Хэширование
Чаще бывает, что значения ключей разбросаны по нескольким диапазонам (существуют недопустимые значения ключа). В этих случаях применяют метод хэширования и создают специальные хэш-функции.
Мы берем значение ключа и вычисляем некоторую хэш-функцию, значение которой используем для начала поиска. Таким образом, мы допускаем, что одному значению хэш-функции будет соответствовать несколько ключей (синонимы). Такая ситуация называется коллизией.
При использовании хэширования нужно:
-
выбрать хэш-функцию,
-
выбрать метод разрешения коллизий.
Стратегия разрешения коллизий с помощью области переполнения
Для каждой записи вычисляется значение хэш-функции и запись заносится в основную область в соответствии с этим значением.
Файловое пространство разделяется на основную область и область переполнения.
Если вновь записываемая запись имеет такое же значение, какое уже есть у записи, имеющейся в БД, то новая заносится в область переполнения на свободное место, а в той записи, что в основной области, делается ссылка на адрес новой. Если в ней ссылка уже была, тогда новая получает информацию в виде ссылки и становится второй в цепочке, а та, что была второй, становиться третьей. То есть новая запись всегда становится второй в цепочке синонимов.
При поиске также вычисляется значение хэш-функции и считывается первая запись в цепочке синонимов из основной области, если нужна не она, идем дальше по цепочке.
При удалении если это запись из основной области, на ее место пишется вторая в цепочке, корректируются указатели, а если она из области переполнения, то просто корректируются указатели.
Стратегия свободного замещения.
Файловое пространство не разделяется на области, но для каждой записи добавляется два указателя: на предыдущую и на следующую запись в цепочке синонимов.
Для новой записи вычисляется значение хэш-функции и если данный адрес свободен, то она становится первой. Если занят, то определяется какая должна быть первой - новая или нет, если новая, то она записывается первой (корректируются ссылки), если нет, то она ставится на свободное место и корректируются ссылки (она ставится второй).
Индексные файлы
Отличительная особенность индексных файлов заключаются в наличии индекса, позволяющего осуществлять менее упорядоченный доступ к записям.
Индекс представляет собой файл, в котором хранятся ключ и указатель. Указатель позволяет вычислить адрес записи или блока (если записи блокируются) в памяти. Индекс обычно организуется с помощью того же ключевого атрибута, который используется для упорядочения записей файла.
Файлы с плотным индексом или индексно - прямые файлы
Структура индексной записи в таком файле:
Значение ключа = Номер записи
Так как индексные файлы строятся для первичных ключей, однозначно определяющих запись, то в них не может быть двух записей, имеющих одинаковые значения первичного ключа. В индексных файлах с плотным индексом для каждой записи в основной области существует одна запись из индексной области. Все записи в индексной области упорядочены по значению ключа.
Длина доступа к произвольной записи оценивается в количестве обращений к дисковой памяти, т.к. обращение к диску является наиболее длительной операцией.
Наиболее эффективным алгоритмом поиска является логарифмический, или бинарный, поиск. При этом все пространство поиска разбивается пополам, и так как оно строго упорядочено, то определяется сначала, не является ли элемент искомым, а если нет, то в какой половине его надо искать. Следующим шагом мы определенную половину также делим пополам и производим аналогичные сравнения, и т. д., пока не обнаружим искомый элемент. Максимальное количество шагов поиска определяется двоичным логарифмом от общего числа элементов в искомом пространстве поиска:
Т"=log2N где N - число элементов.
Бинарный поиск происходит в индексной области, а потом путем прямой адресации - обращение к основной области уже по конкретному номеру записи. На диске записи файлов хранятся в блоках. В одном блоке могут размещаться несколько записей. Блок содержит гораздо большее число индексных записей, чем основных, за счет этого и происходит повышение быстродействия поиска.
При операции добавления осуществляется запись в конец основной области. В индексной области необходимо произвести занесение информации в конкретное место, чтобы не нарушать упорядоченности. Поэтому вся индексная область файла разбивается на блоки и при начальном заполнении в каждом блоке остается свободная область (процент расширения). Когда исчезает свободная область, возникает переполнение индексной области. В этом случае возможны два решения: либо перестроить заново индексную область, либо организовать область переполнения для индексной области.
Именно поэтому при проектировании физической базы данных так важно заранее как можно точнее определить объемы хранимой информации, спрогнозировать ее рост и предусмотреть соответствующее расширение области хранения.
При удалении записи возникает следующая последовательность действий: запись в основной области помечается как удаленная (отсутствующая), в индексной области соответствующий индекс уничтожается физически, то есть записи, следующие за удаленной записью, перемещаются на ее место и блок, в котором хранился данный индекс, заново записывается на диск
Файлы с неплотным индексом, или индексно-последовательные файлы
Неплотный индекс строится упорядоченных файлов. Структура записи индекса для таких файлов имеет следующий вид:
Значение ключа первой записи блока = Номер блока с этой записью
В индексной области мы теперь ищем нужный блок по заданному значению первичного ключа. Так как все записи упорядочены, то значение первой записи блока позволяет нам быстро определить, в каком блоке находится искомая запись. Все остальные действия происходят в основной области.
Время поиска сокращается за счет уменьшения размера индексного файла.
Время сортировки больших файлов весьма значительно, но поскольку файлы поддерживаются сортированными с момента их создания, накладные расходы в процессе добавления новой информации будут гораздо меньше.
При добавлении новой записи она должна заноситься сразу в требуемый блок на требуемое место, которое определяется заданным принципом упорядоченности по значению первичного ключа. Поэтому сначала ищется требуемый блок основной памяти, в который надо поместить новую запись, а потом этот блок считывается, затем в оперативной памяти корректируется содержимое блока и он снова записывается на диск на старое место. Здесь должен быть задан процент первоначального заполнения блоков, но только применительно к основной области.
Удаление записи происходит путем ее физического удаления из основной области, при этом индексная область обычно не корректируется, даже если удаляется первая запись блока.
Организация индексов в виде В-tгее (В-деревьев)
Построение В-деревьев связано с простой идеей построения индекса над уже построенным индексом. Действительно, если построен неплотный индекс, то сама индексная область может быть рассмотрена как основной файл, над которым надо снова построить неплотный индекс, а потом снова над новым - индексом строим следующий и так до того момента, пока не останется всего один индексный блок.
В итоге получется дерево, каждый родительский блок которого связан с одинаковым количеством подчиненных блоков, число которых равно числу индексных записей, размещаемых в одном блоке. Количество обращений к диску при этом для поиска любой записи одинаково и равно количеству уровней в построенном дереве. Такие деревья называются сбалансированными (bаlаnсеd) именно потому, что путь от корня до любого листа в этом дереве одинаков.
Взаимосвязанные файлы
Основной принцип связывания одной физической записи базы данных с другой состоит в использовании указателей. Указатель - это элемент данных, содержащий физический адрес.
Связанные списки. При использовании связанных списков в каждой записи содержится указатель на следующую запись, связанную с ней по значению определенного поля. Такие цепочки указателей обеспечивают возможность связывания записей, содержащих в интересующем нас атрибуте одинаковые значения. Это и есть связанный список. Головной список, поддерживаемый отдельно на диске, указывает на первую запись в каждой цепочке. Если последняя запись содержит указатель на первую, образуется кольцо (многокольцевой файл) или замкнутый список. Такие списки используются в сетевых структурах. Их недостаток в том, что для длинных списков проход по цепочке занимает много времени. Длинные списки также подвержены искажениям, связанным со сбоями операционной системы.
Принцип организации цепочек записей внутри файла и ссылки на номера записей для нескольких взаимосвязанных файлов используется для моделирования отношения «один-ко-многим» и «многие-ко-многим» в файловых структурах.
Рассмотрим как моделируется отношение «один-ко-многим». При этом один файл - основной, другой - подчиненный.
Структура записи основного файла:
КЛЮЧ ЗАПИСЬ ССЫЛКА_УКАЗАТЕЛЬ на первую запись подчиненного файла
Структура записи подчиненого файла:
УКАЗАТЕЛЬ на следующую запись в цепочке СОДЕРЖИМОЕ ЗАПИСИ
При реализации связи «многие-ко-многим» один файл («подчиненный» или «основной») может быть связан с несколькими другими файлами, при этом для каждой связи моделируются свои указатели.
Инвертированные списки
Достаточно часто в базах данных требуется проводить операции доступа по вторичным ключам. Вторичный ключ не является уникальным, так как существует множество записей, имеющих одинаковые значения вторичного ключа. Инвертированные списки послужили основой организации индексных файлов для доступа по вторичным ключам.
Инвертированный список в общем случае - это двухуровневая индексная структура. Здесь на первом уровне находится файл или часть файла, в которой упорядоченно расположены значения вторичных ключей. Каждая запись с вторичным ключом имеет ссылку на номер первого блока в цепочке блоков, содержащих номера записей с данным значением вторичного ключа. На втором уровне находится цепочка блоков, содержащих номера записей, содержащих одно и то же значение вторичного ключа. При этом блоки второго уровня упорядочены по значениям вторичного ключа.
И наконец, на третьем уровне находится собственно основной файл.
Механизм доступа к записям по вторичному ключу при подобной организации записей весьма прост. На первом шаге мы ищем в области первого уровня заданное значение вторичного ключа, а затем по ссылке считываем блоки второго уровня, содержащие номера записей с заданным значением вторичного ключа, а далее уже прямым доступом загружаем в рабочую область пользователя содержимое всех записей, содержащих заданное значение вторичного ключа.
Для одного основного файла может быть создано несколько инвертированиных списков по разным вторичным ключам. Организация вторичных списков ускоряет поиск записей с заданным значением вторичного ключа. Но при модификации основного файла после изменения записи исключается старая ссылка на предыдущее значение вторичного ключа и добавляется новая ссылка на новое значение вторичного ключа для всех вторичных ключей, по которым созданы инвертированные списки. Такой процесс требует больших временных затрат. Поэтому введение вторичных индексов (в том числе инвертированных списков) не всегда ускоряет обработку информации в базе данных, а только в том случае, если база данных достаточно стабильна и ее содержимое практически не меняется.
Организация данных при страничной (бесфайловой организации)
Современные СУБД берут на себя функции управления внешней памятью, так как принципы организации данных операционной системы могут быть не оптимальны по отношению к базам данных.
При страничной организации дисковой памяти используются следующие понятия:
Чанк- физическое пространство на диске, которое ассоциировано одному процессу (устройство, часть устройства, файл).
Экстент - непрерывная область дисковой памяти.
Совокупность экстентов моделирует таблицу базы данных.
Экстенты состоят из страниц. Страницы бывают четырех типов: страницы данных, страницы индексов, битовые страницы и страницы blob-объектов.(Binary Large Object). Страница является основной единицей обмена аданными. Все страницы имеют одинаковую структуру: заголовок, содержание (строки), слоты. Каждая строка в базе данных имеет уникальный номер (номер страницы + номер строки).
Слот - 4-байтовое слово, 2 байта - смещение строки на странице, 2 байта - длина строки. При упорядочении строк на странице не происходит их физического перемещения, все операции выполняются со слотами.
Тема 2.3. СУБД и средства проектирования структур данных
Лекция 15
«СУБД: основные функции, типы. Свойства и сравнительные характеристики СУБД»
Классификация и сравнительная характеристика СУБД. Выбор СУБД
Классифицировать СУБД можно по следующим признакам:
-
по используемой модели данных (классификация МД была рассмотрена выше),
-
по способу организации БД (централизованная или распределенная);
-
по реализуемым режимам работы (однопользовательский, многопользовательский м т.д.);
-
по способам физической организации данных.
Наиболее существенным критерием для сравнения СУБД являются эксплуатационные характеристики, такие как надежность, высокая готовность, производительность,масштабируемость. Сравнительный анализ основных СУБД по этим показателям производится на основе экспертных оценок. Пример такого анализа приведен в таблице.
Сравнительные характеристики
Microsoft SQL Server
Oracle
Административное управление
Хорошо
Отлично
Графические инструменты
Отлично
Хорошо
Простота обслуживания
Отлично
Отлично
Механизм данных
Хорошо
Отлично
Работа с несколькими ЦП
Приемлемо
Отлично
Функция соединения и выбор индексов
Отлично
Отлично
Одновременный доступ нескольких пользователей
Хорошо
Отлично
Обработка мультимедиа-даных
Плохо
Отлично
Подключение к Web
Приемлемо
Отлично
Обработка аудио, видео, изображений
Плохо
Отлично
Поиск по всему тексту
Хорошо
Отлично
Функциональная совместимость
Хорошо
Хорошо
Сопряжение с другими БД
Хорошо
Хорошо
Единая регистрация
Хорошо
Хорошо
Работа под управлением различных ОС
Приемлемо
Хорошо
Возможности программирования
Приемлемо
Отлично
Хранимые процедуры и триггеры
Хорошо
Отлично
Внутренний язык программирования
Приемлемо
Отлично
Построение баз данных
Хорошо
Отлично
Язык SQL
Отлично
Отлично
Объектно-ориентированные системы
Приемлемо
Отлично
Тиражирование
Отлично
Отлично
Распределенная обработка транзакций
Отлично
Отлично
Дистанционное администрирование
Хорошо
Отлично
Организация хранилищ данных и подготовка отчетов
Отлично
Отлично
Средства загрузки
Отлично
Отлично
Средства анализа
Отлично
Отлично
Требования к СУБД
Выбор СУБД является одним из важных этапов при разработке приложений баз данных. Выбранный программный продукт должен удовлетворять как текущим, так и будущим потребностям предприятия, при этом следует учитывать финансовые затраты на приобретение необходимого оборудования, самой системы, разработку необходимого программного обеспечения на ее основе, а также обучение персонала. Кроме того, необходимо убедиться, что новая СУБД способна принести предприятию реальные выгоды.
Очевидно, наиболее простой подход при выборе СУБД основан на оценке того, в какой мере существующие системы удовлетворяют основным требованиям создаваемого проекта информационной системы. Более сложным и дорогостоящим вариантом является создание испытательного проекта на основе нескольких СУБД и последующий выбор наиболее подходящего. Но и в этом случае используются определенные критерии отбора.
Перечень требований к СУБД может изменяться в зависимости от поставленных целей. Тем не менее, можно выделить несколько групп критериев:
-
реализуемые режимы работы с БД и максимальное число пользователей одновременно обращающихся к базе;
-
модель данных (предусмотренные типы данных, средства поиска, реализация языка запросов, средства поддержания целостности базы данных);
-
особенности архитектуры и функциональные возможности (масштабируемость, которая определяет, сможет ли данная СУБД соответствовать росту информационной системы, распределенность, сетевые возможности);
-
контроль работы системы (возможность управления использованием памяти, возможность самоконфигурирования, самодиагностики производительности);
-
особенности разработки приложений (средства проектирования, поддержка большого количества национальных языков, возможности разработки Web-приложений, поддерживаемые языки программирования);
-
производительность (Рейтинг TPC (Transactions per Cent) т.е. отношение количества запросов, обрабатываемых за некий промежуток времени, к стоимости всей системы, возможности параллельной обработки данных, возможности оптимизирования запросов);
-
надежность (сохранность информации при сбоях, обеспечение защиты данных от несанкционированного доступа);
-
требования к рабочей среде (минимальные требования к оборудованию, максимальный размер адресуемой памяти, операционные системы, под управлением которых способна работать СУБД);
-
требуемый уровень квалификации персонала;
-
смешанные критерии (качество и полнота документации, стоимость, стабильность производителя, распространенность СУБД).
Лекция 16
«Автоматизированные системы проектирования баз данных. Основные возможности Case-средств. Классификация Case-средств»
Средства проектирования структур баз данных
Общая характеристика и классификация CASE-средств
Проектирование ИС - это логически сложная, трудоемкая и длительная по времени работа, требующая высокой квалификации специалистов. Однако до недавнего времени проектирование ИС выполнялось в основном на интуитивном уровне с применением неформализованных методов, основанных на искусстве, практическом опыте, экспертных оценках и дорогостоящих экспериментальных проверках качества функционирования ИС. Применение структурной методологии проеткирования при неавтоматизированной (ручной) разработке затруднено.
Это способствовало появлению программно-технологических средств, реализующих CASE-технологию (Computer Aided Software Engineering) создания и сопровождения ИС. Под термином CASE-средства понимаются программные средства, поддерживающие процессы создания и сопровождения ИС, включая анализ и формулировку требований, проектирование прикладного программного обеспечения (приложений) и баз данных, генерацию кода, тестирование, документирование, обеспечение качества, конфигурационное управление и управление проектом, а также другие процессы.
Современные CASE-средства охватывают обширную область поддержки многочисленных технологий проектирования ИС: от простых средств анализа и документирования до полномасштабных средств автоматизации, покрывающих весь жизненный цикл ПО.
Наиболее трудоемкими этапами разработки ИС являются этапы анализа и проектирования, в процессе которых CASE-средства обеспечивают качество принимаемых технических решений и подготовку проектной документации. При этом большую роль играют методы визуального представления информации. Это предполагает построение структурных или иных диаграмм в реальном масштабе времени, использование многообразной цветовой палитры, сквозную проверку синтаксических правил. Графические средства моделирования предметной области позволяют разработчикам в наглядном виде изучать существующую ИС, перестраивать ее в соответствии с поставленными целями и имеющимися ограничениями.
Современный рынок программных средств насчитывает около 300 различных CASE-средств. Это как относительно дешевые системы для персональных компьютеров с ограниченными возможностями, так и дорогостоящие системы для неоднородных вычислительных платформ и операционных сред.
Обычно к CASE-средствам относят любое программное средство, автоматизирующее ту или иную совокупность процессов жизненного цикла программного обеспечения.
Интегрированное CASE-средство (или комплекс средств, поддерживающих полный ЖЦ ПО) содержит следующие компоненты;
-
репозиторий, являющийся основой CASE-средства. Он должен обеспечивать хранение версий проекта и его отдельных компонентов, синхронизацию поступления информации от различных разработчиков при групповой разработке, контроль метаданных на полноту и непротиворечивость;
-
графические средства анализа и проектирования, обеспечивающие создание и редактирование иерархически связанных диаграмм (DFD, ERD и др.), образующих модели ИС;
-
средства разработки приложений, включая языки 4GL и генераторы кодов;
-
средства конфигурационного управления;
-
средства документирования;
-
средства тестирования;
-
средства управления проектом;
-
средства реинжиниринга.
Все современные CASE-средства могут быть классифицированы в основном по типам и категориям. Классификация по типам отражает функциональную ориентацию CASE-средств на те или иные процессы ЖЦ и включает следующие основные типы:
-
средства анализа (Upper CASE), предназначенные для построения и анализа моделей предметной области (Design/IDEF (Meta Software), BPwin (Logic Works));
-
средства анализа и проектирования (Middle CASE), использующиеся для создания проектных спецификаций (Vantage Team Builder (Cayenne), Designer/2000 (ORACLE), Silverrun (CSA), PRO-IV (McDonnell Douglas), CASE.Аналитик (МакроПроджект)). Выходом таких средств являются спецификации компонентов и интерфейсов системы, архитектуры системы, алгоритмов и структур данных;
-
средства проектирования баз данных, обеспечивающие моделирование данных и генерацию схем баз данных (как правило, на языке SQL) для наиболее распространенных СУБД. К ним относятся ERwin (Logic Works), S-Designor (SDP) и DataBase Designer (ORACLE). Средства проектирования баз данных имеются также в составе CASE-средств Vantage Team Builder, Designer/2000, Silverrun и PRO-IV;
-
средства разработки приложений. К ним относятся средства 4GL (Uniface (Compuware), JAM (JYACC), PowerBuilder (Sybase), Developer/2000 (ORACLE), New Era (Informix), SQL Windows (Gupta), Delphi (Borland) и др.) и генераторы кодов, входящие в состав Vantage Team Builder, PRO-IV и частично - в Silverrun;
-
средства реинжиниринга, обеспечивающие анализ программных кодов и схем баз данных и формирование на их основе различных моделей и проектных спецификаций. Средства анализа схем БД и формирования ERD входят в состав Vantage Team Builder, PRO-IV, Silverrun, Designer/2000, ERwin и S-Designor. В области анализа программных кодов наибольшее распространение получают объектно-ориентированные CASE-средства, обеспечивающие реинжиниринг программ на языке С++ (Rational Rose (Rational Software), Object Team (Cayenne)).
-
средства планирования и управления проектом (SE Companion, Microsoft Project и др.);
-
средства конфигурационного управления (PVCS (Intersolv));
-
средства тестирования (Quality Works (Segue Software));
-
средства документирования (SoDA (Rational Software)).
Классификация по категориям определяет степень интегрированности по выполняемым функциям и включает в себя:
-
отдельные локальные средства, решающие небольшие автономные задачи (tools),
-
частично интегрированные средства, охватывающие большинство этапов жизненного цикла ИС (toolkit)
-
полностью интегрированные средства, поддерживающие весь ЖЦ ИС и связанные общим репозиторием.
Помимо этого, CASE-средства можно классифицировать по следующим признакам:
-
применяемым методологиям и моделям систем и БД;
-
степени интегрированности с СУБД;
-
доступным платформам.
На сегодняшний день Российский рынок программного обеспечения располагает следующими наиболее развитыми CASE-средствами:
-
Vantage Team Builder (Westmount I-CASE);
-
Designer/2000;
-
Silverrun;
-
ERwin+BPwin;
-
S-Designor;
-
CASE.Аналитик.
Кроме того, на рынке постоянно появляются и новые для отечественных пользователей системы (например, CASE /4/0, PRO-IV, System Architect, Visible Analyst Workbench, EasyCASE), и новые версии и модификации перечисленных систем.
Раздел 3. Технология разработки БД средствами Microsoft Access.
Тема 3.1. СУБД Access.
Лекция 17
«Основные возможности СУБД Access. Принципы работы с программой. Меню программы. Панели инструментов. Объекты СУБД Access»
Основные характеристики и возможности СУБД Access
Группа реляционных СУБД представлена на рынке программных продуктов очень широко. Это, например, такие системы, как Paradox, Clarion, dBASE, FoxBASE, FoxPro, Clipper, Access. Важнейшей характеристикой любой СУБД является используемый в ней тип транслятора (интерпретатор или компилятор). Программы, написанные для системы-интерпретатора, не работают без наличия самой этой системы. В настоящее время скорость работы таких программ не уступает скорости программ, сгенерированных компилятором. Бесспорным преимуществом интерпретаторов для программистов является удобство разработки и отладки программных продуктов, а также освоение языка. Из перечисленных СУБД dBASE, FoxPro, Access являются интерпретаторами, а Clipper - компилятором. В пакетах dBASE и FoxPro имеется компилятор, позволяющий при желании сформировать ЕХЕ-файлы готовых программ. Недостатком систем-компиляторов являются большие суммарные затраты времени на многократную компиляцию и сборку (линковку) исходных модулей программы при ее отладке.
СУБД Access (фирма Microsoft) имеет достаточно высокие скоростные характеристики и входит в состав чрезвычайно популярного в нашей стране и за рубежом пакета Microsoft Office. Набор команд и функций, предлагаемых разработчикам программных продуктов в среде Access, по мощи и гибкости отвечает большинству современных требований к представлению и обработке данных. В Access поддерживаются разнообразные всплывающие и многоуровневые меню, работа с окнами и мышью, реализованы функции низкоуровневого доступа к файлам, управления цветами, настройки принтера, представления данных в виде электронных таблиц и т. п. Система также обладает средствами быстрой генерации экранов, отчетов и меню, поддерживает язык управления запросами SQL, имеет встроенный язык Visual Basic for Applications (VBA), хорошо работает в сети. СУБД Access позволяет использовать другие компоненты пакета Microsoft Office, такие как текстовый процессор Word for Windows, электронные таблицы Excel и т.д.
Перечисленные факторы определили выбор СУБД Access в качестве среды для практического изучения вопросов проектирования баз данных.
Приведем некоторые из средств Microsoft Access, существенно упрощающие разработку приложений.
-
Процедуры обработки событий и модули форм и отчетов. На встроенном языке VBA можно писать процедуры обработки событий, возникающих в формах и отчетах. Процедуры обработки событий хранятся в модулях, связанных с конкретными формами и отчетами, в результате чего код становится частью макета формы или отчета. Кроме того, существует возможность вызова функции VBA свойством события.
-
Свойства, определяемые в процессе выполнения. С помощью макроса или процедуры обработки событий можно определить практически любое свойство формы или отчета в процессе выполнения в ответ на возникновение события в форме или отчете.
-
Модель событий. Модель событий, похожая на используемую в языке Microsoft Visual Basic, позволяет приложениям реагировать на возникновение различных событий, например нажатие клавиши на клавиатуре, перемещение мыши или истечение определенного интервала времени.
-
Использование обработки данных с помощью VBA. С помощью языка VBA можно определять и обрабатывать различные объекты, в том числе, таблицы, запросы, поля, индексы, связи, формы, отчеты и элементы управления.
-
Построитель меню. Предназначен для помощи при создании специальных меню в приложениях. Кроме того, специальные меню могут содержать подменю.
-
Улучшенные средства отладки. Помимо установки точек прерывания и пошагового выполнения программ на языке VBA, можно вывести на экран список всех активных процедур. Для этого следует выбрать команду Вызовы в меню Вид или нажать кнопку [Вызовы] на панели инструментов.
-
Процедура обработки ошибок. Помимо традиционных способов обработки ошибок возможно использование процедуры обработки события Error для перехвата ошибок при выполнении программ и макросов.
-
Улучшенный интерфейс защиты. Команды и окна диалога защиты упрощают процедуру защиты и смены владельца объекта.
-
Программная поддержка механизма OLE. С помощью механизма OLE можно обрабатывать объекты из других приложений.
10. Программы-надстройки. С помощью VBA можно создавать
программы-надстройки, например нестандартные мастера и по
строители. Мастер - средство Microsoft Access, которое сначала
задает пользователю вопросы, а затем создает объект (таблицу,
зanpoc, форму, отчет и т.д.) в соответствии с его указаниями.
Диспетчер надстроек существенно упрощает процедуру установки программ-надстроек в Microsoft Access.
Мастера Access
Access позволяет даже мало подготовленному пользователю создать свою БД, обрабатывать данные с помощью форм, запросов и отчетов, проводить анализ таблиц БД и выполнять ряд других работ. Практически для любых работ с БД в Access имеется свой мастер, который помогает их выполнять.
Мастер по анализу таблиц позволяет повысить эффективность базы данных за счет нормализации данных. Он разделяет ненормализованную таблицу на две или несколько таблиц меньшего размера, в которых данные сохраняются без повторения.
Мастера по созданию форм и отчетов упрощают и ускоряют процесс создания многотабличных форм и отчетов. Новые форма и отчет могут наследовать примененный к таблице-источнику записей фильтр. Мастера по разработке форм и отчетов автоматически создают инструкцию SQL, определяющую источник записей для формы или отчета, поэтому отпадает необходимость в создании запроса.
Для изменения вида формы, отчета или отдельных элементов может быть использован мастер, вызываемый кнопкой [Автоформат].
Мастер подстановок создает в поле таблицы раскрывающийся список значений из другой таблицы для выбора и ввода нужного значения. Для создания такого поля со списком достаточно в режиме конструктора таблицы выбрать тип данных этого поля - Мастер подстановок. Мастер подстановок можно вызвать в режиме таблицы командой меню Вставка\Столбец подстановок. Созданный в данном поле таблицы список наследуется при включении этого поля в форму.
Мастера по импорту/экспорту позволяют просматривать данные при импорте/экспорте текста или электронных таблиц, а также при экспорте данных Microsoft Access в текстовые файлы.
Мастер защиты при необходимости эвакуирует данные, для чего создает новую базу данных, копирует в нее все объекты из исходной базы данных, снимает все права, присвоенные членам группы пользователей, и шифрует новую базу данных. После завершения работы мастера администратор может присвоить новые права доступа пользователям и группам пользователей.
Мастер по разделению базы данных позволяет разделить ее на два файла, в первый из которых помещаются таблицы, а во второй - запросы, формы, отчеты, макросы и модули. При этом пользователи, работающие в сети, имея общий источник данных, смогут устраивать формы, отчеты и другие объекты, используемые для обработки данных, по своему усмотрению.
2.2. Типы данных СУБД Access
Для каждого поля таблиц базы данных необходимо указывать тип данных. Тип данных определяет вид и диапазон допустимых значений, которые могут быть введены в поле, а также объем памяти, выделяющийся для этого поля. Перечень типов данных полей и описание значений, сохраняемых в таких полях, приведены в табл. 2.1.
Таблица 2.1
Типы данных базы данных Microsoft Access
Тип данных
Содержимое типа данных
Текстовый
Текст и числа, например, имена и адреса, номера теле-
фонов и почтовые индексы. Текстовое поле может содер-
жать до 255 символов
Поле Memo
Длинный текст и числа, например комментарии и
пояснения. Поле Memo может содержать до 64000
символов
Числовой
Числовые данные, допускающие проведение математи-
ческих расчетов, за исключением денежных. Свойство
Размер поля (FieldSize) позволяет указывать различные
типы числовых данных
Дата/время
Значения даты и времени. Пользователь имеет возмож-
ность выбора одного из многочисленных стандартных
форматов или создания специального формата
Денежный
Денежные значения (не рекомендуется использовать для
проведения денежных расчетов значения, принадлежа-
щие к числовому типу данных, так как последние могут
округляться при расчетах), которые всегда выводятся с
указанным числом десятичных знаков после запятой
Счетчик
Автоматически вставляющиеся последовательные номера.
Нумерация начинается с единицы. Поле счетчика, удоб-
ное для создания ключа, является совместимым с полем
числового типа, для которого в свойстве Размер поля
(FieldSize) указано значение Длинное целое
Логический
Значения Да/Нет, Истина/Ложь, Вкл./Выкл.
Поле
Объекты, созданные в других программах, поддерживаю-
объекта OLE
щих протокол OLE, которые связываются или внедряют-
ся в базу данных Microsoft Access через элемент управле-
ния в форме или отчете
2.3. Создание новой базы данных
Создание новой базы данных Access осуществляется в соответствии с ее структурой, полученной в результате внемашинного проектирования, заключающегося в создании информационно-логической модели предметной области. Структура реляционной базы данных определяется составом таблиц и их взаимосвязями. Создание реляционной базы данных с помощью СУБД Access на компьютере начинается с формирования структуры таблиц. При этом формируется состав полей и задается их описание. После формирования структуры таблиц создается схема данных, в которой устанавливаются связи между таблицами. Access запоминает и использует эти связи при заполнении таблиц и обработке данных. Завершается создание базы данных процедурой заполнения таблиц конкретной информацией.
После запуска MS Access одновременно с окном базы данных открывается первое диалоговое окно, позволяющее начать создание БД или открыть уже существующую. На закладках (кнопках) окна базы данных представлены основные типы ее объектов: Таблицы, Запросы, Формы, Отчеты, Макросы, Модули. Рабочее поле окна базы данных предназначено для отображения списка объектов Access выбранного типа (рис. 2.1).
2.4. Создание таблиц в СУБД Access
Работа по созданию базы данных на персональном компьютере (ПК) начинается с создания таблиц. После нажатия кнопки [Создать] в окне База данных разработчику предоставляется возможность выбора одного из пяти способов создания таблицы (табл. 2.2).
Если для создания таблицы выбран режим конструктора, то появляется окно Таблица 1: таблица, в котором определяется структура создаваемой таблицы базы данных (рис. 2.2).
Для определения поля в открывшемся окне задаются Имя поля, Тип данных, Описание (в виде краткого комментария), а также в
Таблица 2.2
Способы создания таблиц в СУБД Access
Способ
Описание
Режим
Для ввода данных предоставляется таблица с 30 поля-
таблицы
ми. После ее сохранения Access сама решает, какой тип
данных присвоить каждому полю. Недостатоком спо-
соба является невозможность создания поля примечаний
Конструктор
Предоставляет возможность самостоятельного создания
таблиц
полей, выбора типа данных для них, размеров и уста-
новки свойства
Мастер таблиц
Предоставляет набор таблиц, из которых можно созда-
вать таблицы по своему вкусу. При этом некоторые таб-
лицы из этого набора могут полностью подойти для
создаваемого приложения. Тип данных и другие свой-
ства полей здесь уже определены
Импорт
Используется для создания копий таблиц приложе-
таблиц
ний - источников данных. Иногда после импорта в
таблице требуется изменить размер поля и некоторые
другие свойства. Новой таблице присваивается имя, в
ней определяется ключевое поле или Access делает это
автоматически
Связь с
Устанавливается автоматическая непосредственная
таблицами
связь создаваемого приложения с данными таблиц дру-
гих приложений, причем таблица остается в приложе-
нии-источнике и может использоваться несколькими
приложениями. При этом экономятся емкость памяти,
поскольку хранятся данные только одной таблицы, и
время, так как информация обновляется только в
таблице-источнике
разделе Свойства поля задаются общие свойства - на закладке Общие и тип элемента управления - на закладке Подстановка.
Каждое поле в таблице должно иметь уникальное имя, удовлетворяющее соглашениям об именах объектов в Access и являющееся комбинацией из букв, цифр, пробелов и специальных символов (за исключением знаков .! «»). Максимальная длина имени - 64 символа.
Тип данных определяется значениями, которые предполагается вводить в поле, и операциями, которые будут выполняться с этими значениями. В Access допускается использование восьми типов данных. Список возможных типов данных каждого поля вызывается нажатием соответствующей кнопки.
Общие свойства поля задаются на закладке Общие для каждого поля и зависят от выбранного типа данных.
Наиболее важные свойства полей:
Размер поля - определяет максимальный размер данных, сохраняемых в поле. Рекомендуется задавать минимально допустимый размер поля, так как сохранение таких полей требует меньше памяти и обработка выполняется быстрее;
Формат поля - является форматом отображения заданного типа данных и задает правила представления этих данных при выводе их на экран или печать. Конкретный формат выбирается в раскрывающемся списке значений свойства Формат поля. Для числового и денежного типов данных задается число знаков после запятой (от 0 до 15);
Подпись поля - задает текст, который выводится в таблицах, формах, отчетах;
Условие на значение - позволяет осуществлять контроль ввода данных, задает ограничения на вводимые значения, при нарушении условий запрещает ввод и выводит текст, заданный свойством Сообщение об ошибке;
Сообщение об ошибке - задает текст сообщения, выводимый на экран при нарушении ограничений, заданных свойством Условие на значение.
Тип элемента управления - это свойство, которое задается на закладке Подстановка в окне конструктора таблиц и определяет, будет ли отображаться поле в таблице и в какой форме (в виде поля, списка или поля со списком). Таким образом определяется тип элемента управления, используемого по умолчанию для ото-
бражения поля. Если для отображения поля выбран тип элемента управления Список или Поле со списком, то на закладке Подстановка появляются дополнительные свойства, которые определяют источник данных для строк списка и ряд других его характеристик.
Если при определении типа поля был выбран мастер подстановок, то им и будут заполнены значения свойств на закладке Подстановка.
Определение первичного ключа
Уникальный (первичный) ключ таблицы может быть простым или составным, включающим в себя несколько полей. Для определения ключа выделяются поля, составляющие его, и на панели инструментов нажимается кнопка [Ключевое поле] или выполняется команда Правка\Ключевое поле.
Окно Индексы вызывается щелчком мыши на кнопке [Индексы] просмотра и редактирования индексов или выполнением команды Вид\Индексы. В этом окне индекс первичного ключа имеет имя Primary Key. В столбце Имя поля этого окна перечисляются имена полей, составляющие индекс.
Индекс ключевого поля всегда уникален и не допускает пустых полей в записях.
Таблица 2.3
Типы данных ключевого поля
Тип данных
Описание
Тип поля
Порядковый номер,
При вводе каждой новой записи
Счетчик
автоматически при-
Access автоматически присваивает
(AutoNum)
сваиваемый каждой
ей порядковый номер. Вводить
новой записи
или редактировать данные в поле Счетчик (AutoNum) нельзя
Номер, вводимый
При вводе записи в одно из ее по-
Числовой
пользователем при
лей заносится уникальное число-
(Number)
добавлении каждой
вое значение, например номер до-
новой записи
кумента. В это поле нельзя вводить буквы
Сочетание букв и
При вводе записи в одно из ее по-
Текстовый
цифр, вводимое поль-
лей заносится уникальное сочета-
(Text)
зователем при добав-
ние цифр и букв. Этот тип данных
лении каждой новой
выбирают, если поле содержит и
записи
буквы и цифры
Раздел 4. Обеспечение функционирования бд
Тема 4.1 Обеспечение функционирования бд
Лекция 18
« »